 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Predicting the Success of Transfer-based Attacks by Quantifying Shared Feature Representations
Dec 06, 2024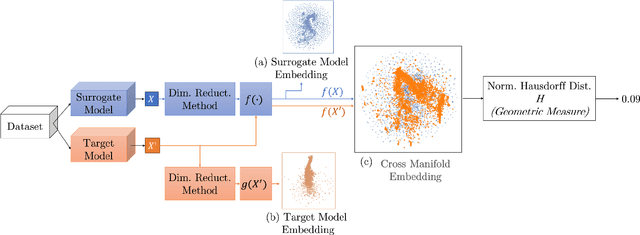
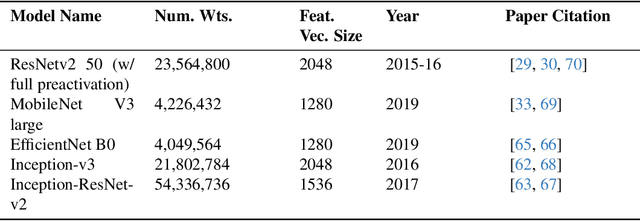
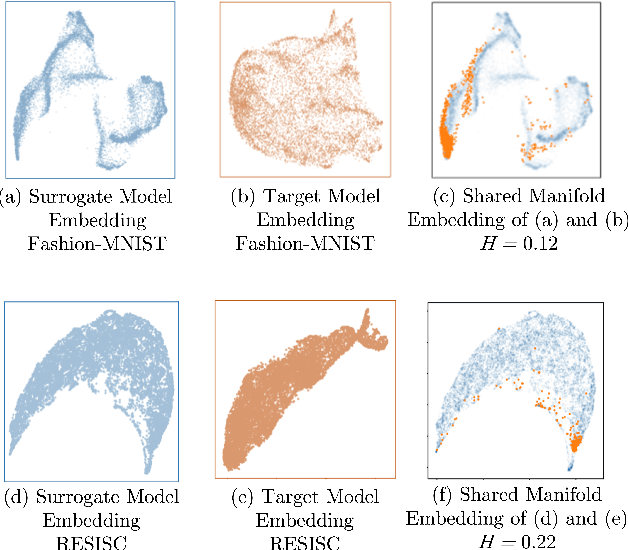

Much effort has been made to explain and improve the success of transfer-based attacks (TBA) on black-box computer vision models. This work provides the first attempt at a priori prediction of attack success by identifying the presence of vulnerable features within target models. Recent work by Chen and Liu (2024) proposed the manifold attack model, a unifying framework proposing that successful TBA exist in a common manifold space. Our work experimentally tests the common manifold space hypothesis by a new methodology: first, projecting feature vectors from surrogate and target feature extractors trained on ImageNet onto the same low-dimensional manifold; second, quantifying any observed structure similarities on the manifold; and finally, by relating these observed similarities to the success of the TBA. We find that shared feature representation moderately correlates with increased success of TBA (\r{ho}= 0.56). This method may be used to predict whether an attack will transfer without information of the model weights, training, architecture or details of the attack. The results confirm the presence of shared feature representations between two feature extractors of different sizes and complexities, and demonstrate the utility of datasets from different target domains as test signals for interpreting black-box feature representations.
Study on Aspect Ratio Variability toward Robustness of Vision Transformer-based Vehicle Re-identification
Jul 10, 2024



Vision Transformers (ViTs) have excelled in vehicle re-identification (ReID) tasks. However, non-square aspect ratios of image or video input might significantly affect the re-identification performance. To address this issue, we propose a novel ViT-based ReID framework in this paper, which fuses models trained on a variety of aspect ratios. Our main contributions are threefold: (i) We analyze aspect ratio performance on VeRi-776 and VehicleID datasets, guiding input settings based on aspect ratios of original images. (ii) We introduce patch-wise mixup intra-image during ViT patchification (guided by spatial attention scores) and implement uneven stride for better object aspect ratio matching. (iii) We propose a dynamic feature fusing ReID network, enhancing model robustness. Our ReID method achieves a significantly improved mean Average Precision (mAP) of 91.0\% compared to the the closest state-of-the-art (CAL) result of 80.9\% on VehicleID dataset.
Enhancing Vehicle Re-identification and Matching for Weaving Analysis
Jul 05, 2024



Vehicle weaving on highways contributes to traffic congestion, raises safety issues, and underscores the need for sophisticated traffic management systems. Current tools are inadequate in offering precise and comprehensive data on lane-specific weaving patterns. This paper introduces an innovative method for collecting non-overlapping video data in weaving zones, enabling the generation of quantitative insights into lane-specific weaving behaviors. Our experimental results confirm the efficacy of this approach, delivering critical data that can assist transportation authorities in enhancing traffic control and roadway infrastructure.