 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Predicting the Success of Transfer-based Attacks by Quantifying Shared Feature Representations
Paper and Code
Dec 06, 2024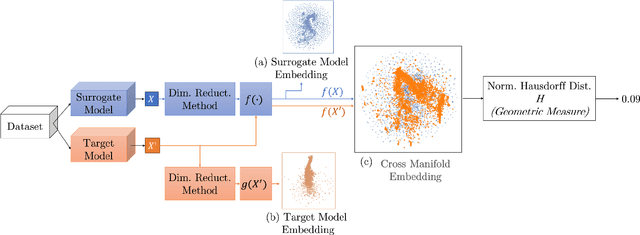
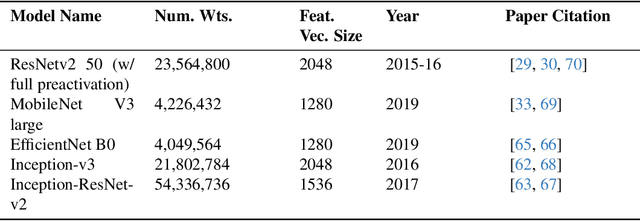
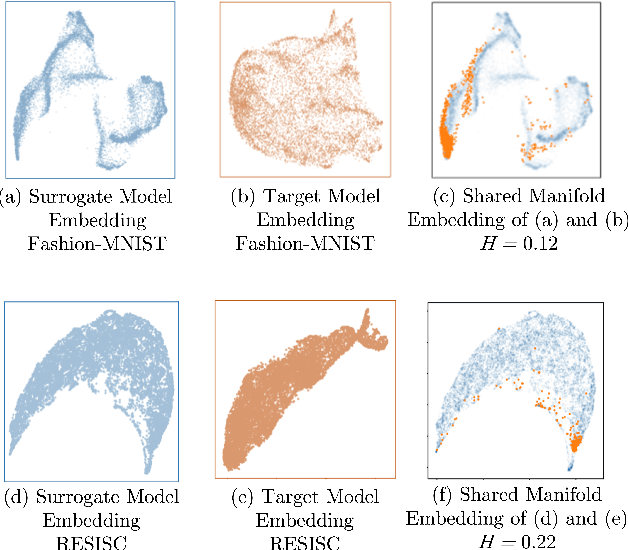

Much effort has been made to explain and improve the success of transfer-based attacks (TBA) on black-box computer vision models. This work provides the first attempt at a priori prediction of attack success by identifying the presence of vulnerable features within target models. Recent work by Chen and Liu (2024) proposed the manifold attack model, a unifying framework proposing that successful TBA exist in a common manifold space. Our work experimentally tests the common manifold space hypothesis by a new methodology: first, projecting feature vectors from surrogate and target feature extractors trained on ImageNet onto the same low-dimensional manifold; second, quantifying any observed structure similarities on the manifold; and finally, by relating these observed similarities to the success of the TBA. We find that shared feature representation moderately correlates with increased success of TBA (\r{ho}= 0.56). This method may be used to predict whether an attack will transfer without information of the model weights, training, architecture or details of the attack. The results confirm the presence of shared feature representations between two feature extractors of different sizes and complexities, and demonstrate the utility of datasets from different target domains as test signals for interpreting black-box feature representations.