 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatThero: An LLM-Supported Chatbot for Behavior Change and Therapeutic Support in Addiction Recovery
Aug 28, 2025
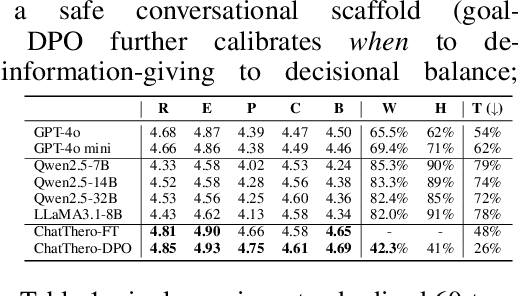
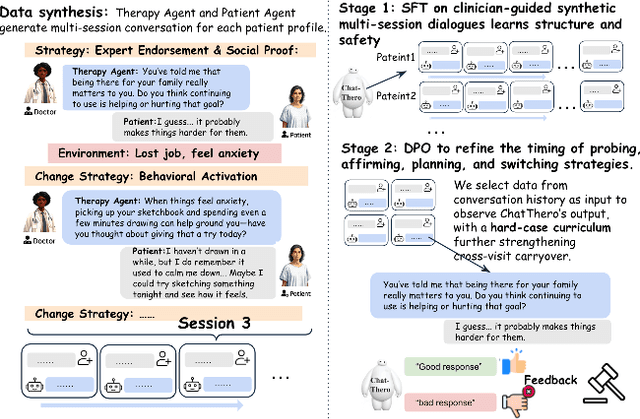

Substance use disorders (SUDs) affect over 36 million people worldwide, yet few receive effective care due to stigma, motivational barriers, and limited personalized support. Although large language models (LLMs) show promise for mental-health assistance, most systems lack tight integration with clinically validated strategies, reducing effectiveness in addiction recovery. We present ChatThero, a multi-agent conversational framework that couples dynamic patient modeling with context-sensitive therapeutic dialogue and adaptive persuasive strategies grounded in cognitive behavioral therapy (CBT) and motivational interviewing (MI). We build a high-fidelity synthetic benchmark spanning Easy, Medium, and Hard resistance levels, and train ChatThero with a two-stage pipeline comprising supervised fine-tuning (SFT) followed by direct preference optimization (DPO). In evaluation, ChatThero yields a 41.5\% average gain in patient motivation, a 0.49\% increase in treatment confidence, and resolves hard cases with 26\% fewer turns than GPT-4o, and both automated and human clinical assessments rate it higher in empathy, responsiveness, and behavioral realism. The framework supports rigorous, privacy-preserving study of therapeutic conversation and provides a robust, replicable basis for research and clinical translation.
On-Board Vision-Language Models for Personalized Autonomous Vehicle Motion Control: System Design and Real-World Validation
Nov 17, 2024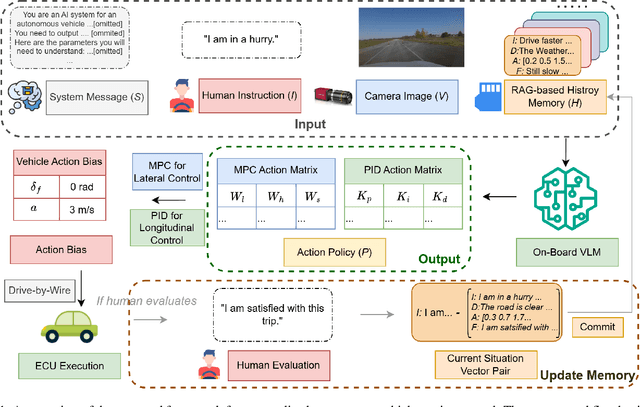
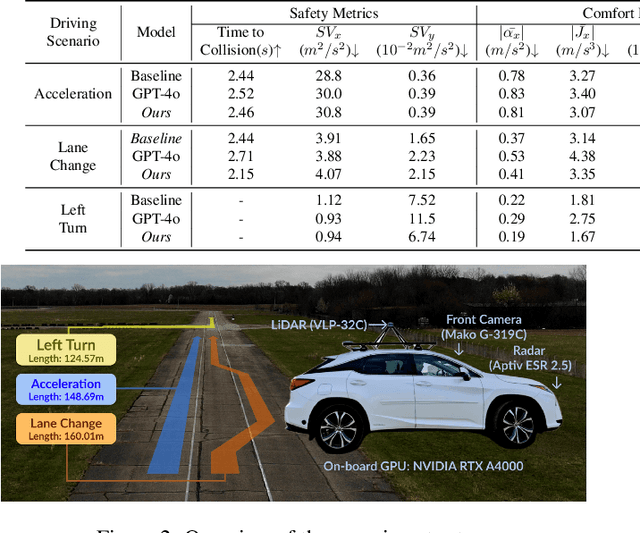

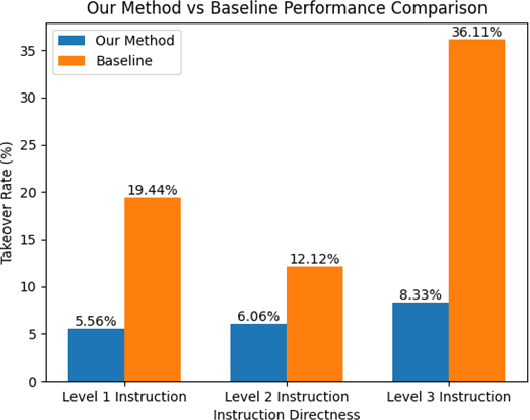
Personalized driving refers to an autonomous vehicle's ability to adapt its driving behavior or control strategies to match individual users' preferences and driving styles while maintaining safety and comfort standards. However, existing works either fail to capture every individual preference precisely or become computationally inefficient as the user base expands. Vision-Language Models (VLMs) offer promising solutions to this front through their natural language understanding and scene reasoning capabilities. In this work, we propose a lightweight yet effective on-board VLM framework that provides low-latency personalized driving performance while maintaining strong reasoning capabilities. Our solution incorporates a Retrieval-Augmented Generation (RAG)-based memory module that enables continuous learning of individual driving preferences through human feedback. Through comprehensive real-world vehicle deployment and experiments, our system has demonstrated the ability to provide safe, comfortable, and personalized driving experiences across various scenarios and significantly reduce takeover rates by up to 76.9%. To the best of our knowledge, this work represents the first end-to-end VLM-based motion control system in real-world autonomous vehicles.
Adaptive Aspect Ratios with Patch-Mixup-ViT-based Vehicle ReID
Nov 09, 2024



Vision Transformers (ViTs) have shown exceptional performance in vehicle re-identification (ReID) tasks. However, non-square aspect ratios of image or video inputs can negatively impact re-identification accuracy. To address this challenge, we propose a novel, human perception driven, and general ViT-based ReID framework that fuses models trained on various aspect ratios. Our key contributions are threefold: (i) We analyze the impact of aspect ratios on performance using the VeRi-776 and VehicleID datasets, providing guidance for input settings based on the distribution of original image aspect ratios. (ii) We introduce patch-wise mixup strategy during ViT patchification (guided by spatial attention scores) and implement uneven stride for better alignment with object aspect ratios. (iii) We propose a dynamic feature fusion ReID network to enhance model robustness. Our method outperforms state-of-the-art transformer-based approaches on both datasets, with only a minimal increase in inference time per image.
Blocks Architecture (BloArk): Efficient, Cost-Effective, and Incremental Dataset Architecture for Wikipedia Revision History
Oct 06, 2024
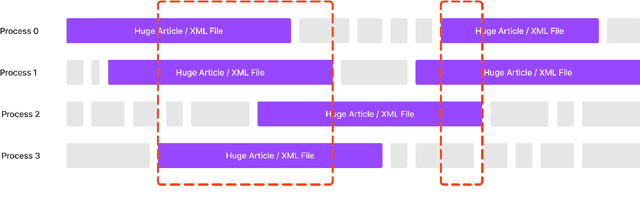
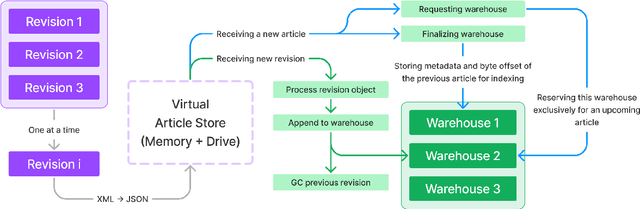
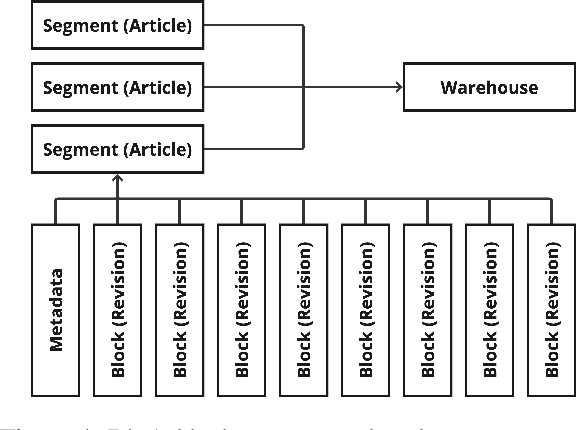
Wikipedia (Wiki) is one of the most widely used and publicly available resources for natural language processing (NLP) applications. Wikipedia Revision History (WikiRevHist) shows the order in which edits were made to any Wiki page since its first modification. While the most up-to-date Wiki has been widely used as a training source, WikiRevHist can also be valuable resources for NLP applications. However, there are insufficient tools available to process WikiRevHist without having substantial computing resources, making additional customization, and spending extra time adapting others' works. Therefore, we report Blocks Architecture (BloArk), an efficiency-focused data processing architecture that reduces running time, computing resource requirements, and repeated works in processing WikiRevHist dataset. BloArk consists of three parts in its infrastructure: blocks, segments, and warehouses. On top of that, we build the core data processing pipeline: builder and modifier. The BloArk builder transforms the original WikiRevHist dataset from XML syntax into JSON Lines (JSONL) format for improving the concurrent and storage efficiency. The BloArk modifier takes previously-built warehouses to operate incremental modifications for improving the utilization of existing databases and reducing the cost of reusing others' works. In the end, BloArk can scale up easily in both processing Wikipedia Revision History and incrementally modifying existing dataset for downstream NLP use cases. The source code, documentations, and example usages are publicly available online and open-sourced under GPL-2.0 license.
Optimizing ROI Benefits Vehicle ReID in ITS
Jul 13, 2024



Vehicle re-identification (ReID) is a computer vision task that matches the same vehicle across different cameras or viewpoints in a surveillance system. This is crucial for Intelligent Transportation Systems (ITS), where the effectiveness is influenced by the regions from which vehicle images are cropped. This study explores whether optimal vehicle detection regions, guided by detection confidence scores, can enhance feature matching and ReID tasks. Using our framework with multiple Regions of Interest (ROIs) and lane-wise vehicle counts, we employed YOLOv8 for detection and DeepSORT for tracking across twelve Indiana Highway videos, including two pairs of videos from non-overlapping cameras. Tracked vehicle images were cropped from inside and outside the ROIs at five-frame intervals. Features were extracted using pre-trained models: ResNet50, ResNeXt50, Vision Transformer, and Swin-Transformer. Feature consistency was assessed through cosine similarity, information entropy, and clustering variance. Results showed that features from images cropped inside ROIs had higher mean cosine similarity values compared to those involving one image inside and one outside the ROIs. The most significant difference was observed during night conditions (0.7842 inside vs. 0.5 outside the ROI with Swin-Transformer) and in cross-camera scenarios (0.75 inside-inside vs. 0.52 inside-outside the ROI with Vision Transformer). Information entropy and clustering variance further supported that features in ROIs are more consistent. These findings suggest that strategically selected ROIs can enhance tracking performance and ReID accuracy in ITS.
Study on Aspect Ratio Variability toward Robustness of Vision Transformer-based Vehicle Re-identification
Jul 10, 2024



Vision Transformers (ViTs) have excelled in vehicle re-identification (ReID) tasks. However, non-square aspect ratios of image or video input might significantly affect the re-identification performance. To address this issue, we propose a novel ViT-based ReID framework in this paper, which fuses models trained on a variety of aspect ratios. Our main contributions are threefold: (i) We analyze aspect ratio performance on VeRi-776 and VehicleID datasets, guiding input settings based on aspect ratios of original images. (ii) We introduce patch-wise mixup intra-image during ViT patchification (guided by spatial attention scores) and implement uneven stride for better object aspect ratio matching. (iii) We propose a dynamic feature fusing ReID network, enhancing model robustness. Our ReID method achieves a significantly improved mean Average Precision (mAP) of 91.0\% compared to the the closest state-of-the-art (CAL) result of 80.9\% on VehicleID dataset.
ReadCtrl: Personalizing text generation with readability-controlled instruction learning
Jun 13, 2024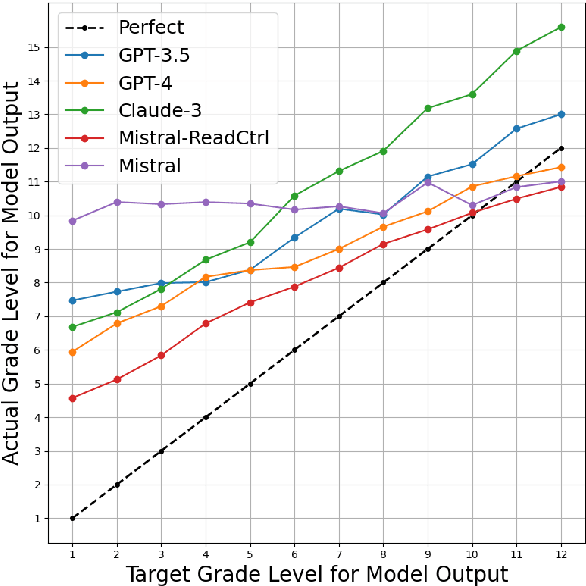
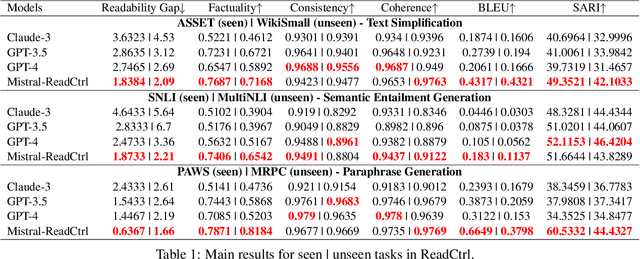
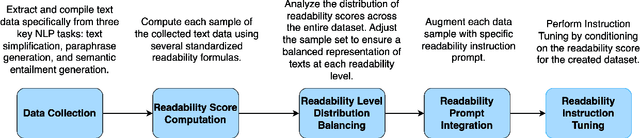
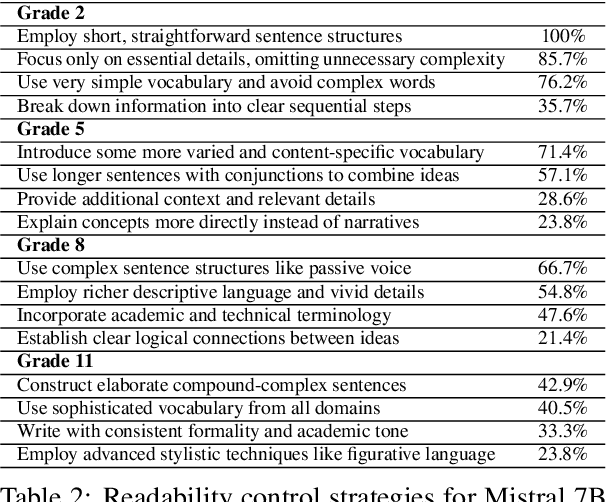
Content generation conditioning on users's readability is an important application for personalization. In an era of large language models (LLMs), readability-controlled text generation based on LLMs has become increasingly important. This paper introduces a novel methodology called "Readability-Controlled Instruction Learning (ReadCtrl)," which aims to instruction-tune LLMs to tailor users' readability levels. Unlike the traditional methods, which primarily focused on categorical readability adjustments typically classified as high, medium, and low or expert and layperson levels with limited success, ReadCtrl introduces a dynamic framework that enables LLMs to generate content at various (near continuous level) complexity levels, thereby enhancing their versatility across different applications. Our results show that the ReadCtrl-Mistral-7B models significantly outperformed strong baseline models such as GPT-4 and Claude-3, with a win rate of 52.1%:35.7% against GPT-4 in human evaluations. Furthermore, Read-Ctrl has shown significant improvements in automatic evaluations, as evidenced by better readability metrics (e.g., FOG, FKGL) and generation quality metrics (e.g., BLEU, SARI, SummaC-Factuality, UniEval-Consistency and Coherence). These results underscore Read-Ctrl's effectiveness and tenacity in producing high-quality, contextually appropriate outputs that closely align with targeted readability levels, marking a significant advancement in personalized content generation using LLMs.
Social Force Embedded Mixed Graph Convolutional Network for Multi-class Trajectory Prediction
Apr 20, 2024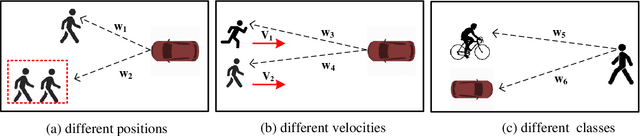
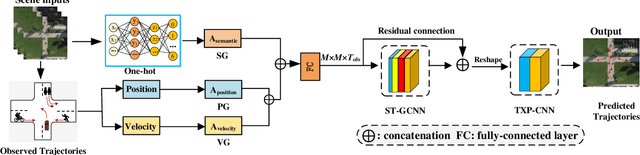
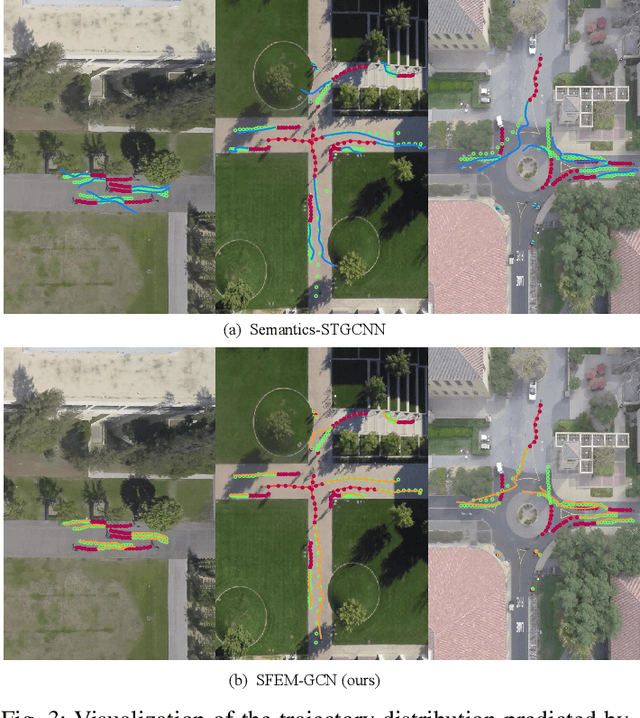

Accurate prediction of agent motion trajectories is crucial for autonomous driving, contributing to the reduction of collision risks in human-vehicle interactions and ensuring ample response time for other traffic participants. Current research predominantly focuses on traditional deep learning methods, including convolutional neural networks (CNNs) and recurrent neural networks (RNNs). These methods leverage relative distances to forecast the motion trajectories of a single class of agents. However, in complex traffic scenarios, the motion patterns of various types of traffic participants exhibit inherent randomness and uncertainty. Relying solely on relative distances may not adequately capture the nuanced interaction patterns between different classes of road users. In this paper, we propose a novel multi-class trajectory prediction method named the social force embedded mixed graph convolutional network (SFEM-GCN). SFEM-GCN comprises three graph topologies: the semantic graph (SG), position graph (PG), and velocity graph (VG). These graphs encode various of social force relationships among different classes of agents in complex scenes. Specifically, SG utilizes one-hot encoding of agent-class information to guide the construction of graph adjacency matrices based on semantic information. PG and VG create adjacency matrices to capture motion interaction relationships between different classes agents. These graph structures are then integrated into a mixed graph, where learning is conducted using a spatiotemporal graph convolutional neural network (ST-GCNN). To further enhance prediction performance, we adopt temporal convolutional networks (TCNs) to generate the predicted trajectory with fewer parameters. Experimental results on publicly available datasets demonstrate that SFEM-GCN surpasses state-of-the-art methods in terms of accuracy and robustness.
PaniniQA: Enhancing Patient Education Through Interactive Question Answering
Aug 21, 2023Patient portal allows discharged patients to access their personalized discharge instructions in electronic health records (EHRs). However, many patients have difficulty understanding or memorizing their discharge instructions. In this paper, we present PaniniQA, a patient-centric interactive question answering system designed to help patients understand their discharge instructions. PaniniQA first identifies important clinical content from patients' discharge instructions and then formulates patient-specific educational questions. In addition, PaniniQA is also equipped with answer verification functionality to provide timely feedback to correct patients' misunderstandings. Our comprehensive automatic and human evaluation results demonstrate our PaniniQA is capable of improving patients' mastery of their medical instructions through effective interactions
FusionPlanner: A Multi-task Motion Planner for Mining Trucks using Multi-sensor Fusion Method
Aug 14, 2023In recent years, significant achievements have been made in motion planning for intelligent vehicles. However, as a typical unstructured environment, open-pit mining attracts limited attention due to its complex operational conditions and adverse environmental factors. A comprehensive paradigm for unmanned transportation in open-pit mines is proposed in this research, including a simulation platform, a testing benchmark, and a trustworthy and robust motion planner. \textcolor{red}{Firstly, we propose a multi-task motion planning algorithm, called FusionPlanner, for autonomous mining trucks by the Multi-sensor fusion method to adapt both lateral and longitudinal control tasks for unmanned transportation. Then, we develop a novel benchmark called MiningNav, which offers three validation approaches to evaluate the trustworthiness and robustness of well-trained algorithms in transportation roads of open-pit mines. Finally, we introduce the Parallel Mining Simulator (PMS), a new high-fidelity simulator specifically designed for open-pit mining scenarios. PMS enables the users to manage and control open-pit mine transportation from both the single-truck control and multi-truck scheduling perspectives.} \textcolor{red}{The performance of FusionPlanner is tested by MiningNav in PMS, and the empirical results demonstrate a significant reduction in the number of collisions and takeovers of our planner. We anticipate our unmanned transportation paradigm will bring mining trucks one step closer to trustworthiness and robustness in continuous round-the-clock unmanned transportation.