 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Anti-exploration via VQVAE and Fuzzy Clustering in Offline Reinforcement Learning
Feb 08, 2026Pseudo-count is an effective anti-exploration method in offline reinforcement learning (RL) by counting state-action pairs and imposing a large penalty on rare or unseen state-action pair data. Existing anti-exploration methods count continuous state-action pairs by discretizing these data, but often suffer from the issues of dimension disaster and information loss in the discretization process, leading to efficiency and performance reduction, and even failure of policy learning. In this paper, a novel anti-exploration method based on Vector Quantized Variational Autoencoder (VQVAE) and fuzzy clustering in offline RL is proposed. We first propose an efficient pseudo-count method based on the multi-codebook VQVAE to discretize state-action pairs, and design an offline RL anti-exploitation method based on the proposed pseudo-count method to handle the dimension disaster issue and improve the learning efficiency. In addition, a codebook update mechanism based on fuzzy C-means (FCM) clustering is developed to improve the use rate of vectors in codebooks, addressing the information loss issue in the discretization process. The proposed method is evaluated on the benchmark of Datasets for Deep Data-Driven Reinforcement Learning (D4RL), and experimental results show that the proposed method performs better and requires less computing cost in multiple complex tasks compared to state-of-the-art (SOTA) methods.
DiffPoGAN: Diffusion Policies with Generative Adversarial Networks for Offline Reinforcement Learning
Jun 13, 2024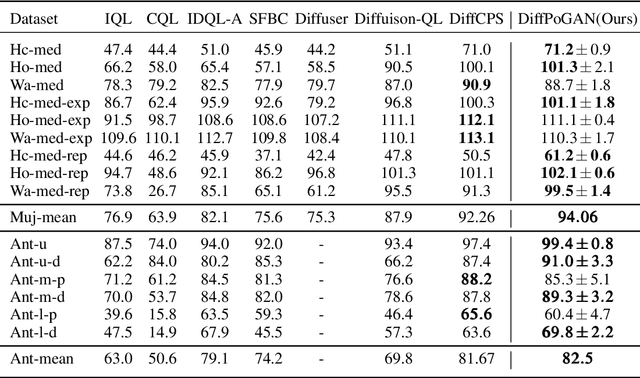
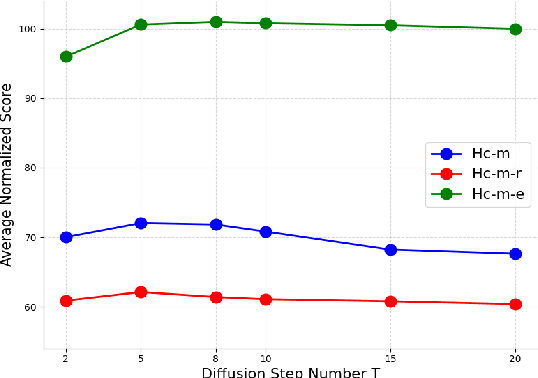
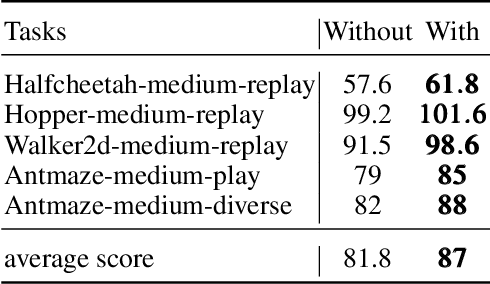
Offline reinforcement learning (RL) can learn optimal policies from pre-collected offline datasets without interacting with the environment, but the sampled actions of the agent cannot often cover the action distribution under a given state, resulting in the extrapolation error issue. Recent works address this issue by employing generative adversarial networks (GANs). However, these methods often suffer from insufficient constraints on policy exploration and inaccurate representation of behavior policies. Moreover, the generator in GANs fails in fooling the discriminator while maximizing the expected returns of a policy. Inspired by the diffusion, a generative model with powerful feature expressiveness, we propose a new offline RL method named Diffusion Policies with Generative Adversarial Networks (DiffPoGAN). In this approach, the diffusion serves as the policy generator to generate diverse distributions of actions, and a regularization method based on maximum likelihood estimation (MLE) is developed to generate data that approximate the distribution of behavior policies. Besides, we introduce an additional regularization term based on the discriminator output to effectively constrain policy exploration for policy improvement. Comprehensive experiments are conducted on the datasets for deep data-driven reinforcement learning (D4RL), and experimental results show that DiffPoGAN outperforms state-of-the-art methods in offline RL.
Long and Short-Term Constraints Driven Safe Reinforcement Learning for Autonomous Driving
Mar 27, 2024



Reinforcement learning (RL) has been widely used in decision-making tasks, but it cannot guarantee the agent's safety in the training process due to the requirements of interaction with the environment, which seriously limits its industrial applications such as autonomous driving. Safe RL methods are developed to handle this issue by constraining the expected safety violation costs as a training objective, but they still permit unsafe state occurrence, which is unacceptable in autonomous driving tasks. Moreover, these methods are difficult to achieve a balance between the cost and return expectations, which leads to learning performance degradation for the algorithms. In this paper, we propose a novel algorithm based on the long and short-term constraints (LSTC) for safe RL. The short-term constraint aims to guarantee the short-term state safety that the vehicle explores, while the long-term constraint ensures the overall safety of the vehicle throughout the decision-making process. In addition, we develop a safe RL method with dual-constraint optimization based on the Lagrange multiplier to optimize the training process for end-to-end autonomous driving. Comprehensive experiments were conducted on the MetaDrive simulator. Experimental results demonstrate that the proposed method achieves higher safety in continuous state and action tasks, and exhibits higher exploration performance in long-distance decision-making tasks compared with state-of-the-art methods.
FusionPlanner: A Multi-task Motion Planner for Mining Trucks using Multi-sensor Fusion Method
Aug 14, 2023In recent years, significant achievements have been made in motion planning for intelligent vehicles. However, as a typical unstructured environment, open-pit mining attracts limited attention due to its complex operational conditions and adverse environmental factors. A comprehensive paradigm for unmanned transportation in open-pit mines is proposed in this research, including a simulation platform, a testing benchmark, and a trustworthy and robust motion planner. \textcolor{red}{Firstly, we propose a multi-task motion planning algorithm, called FusionPlanner, for autonomous mining trucks by the Multi-sensor fusion method to adapt both lateral and longitudinal control tasks for unmanned transportation. Then, we develop a novel benchmark called MiningNav, which offers three validation approaches to evaluate the trustworthiness and robustness of well-trained algorithms in transportation roads of open-pit mines. Finally, we introduce the Parallel Mining Simulator (PMS), a new high-fidelity simulator specifically designed for open-pit mining scenarios. PMS enables the users to manage and control open-pit mine transportation from both the single-truck control and multi-truck scheduling perspectives.} \textcolor{red}{The performance of FusionPlanner is tested by MiningNav in PMS, and the empirical results demonstrate a significant reduction in the number of collisions and takeovers of our planner. We anticipate our unmanned transportation paradigm will bring mining trucks one step closer to trustworthiness and robustness in continuous round-the-clock unmanned transportation.
Sim2real and Digital Twins in Autonomous Driving: A Survey
May 02, 2023



Safety and cost are two important concerns for the development of autonomous driving technologies. From the academic research to commercial applications of autonomous driving vehicles, sufficient simulation and real world testing are required. In general, a large scale of testing in simulation environment is conducted and then the learned driving knowledge is transferred to the real world, so how to adapt driving knowledge learned in simulation to reality becomes a critical issue. However, the virtual simulation world differs from the real world in many aspects such as lighting, textures, vehicle dynamics, and agents' behaviors, etc., which makes it difficult to bridge the gap between the virtual and real worlds. This gap is commonly referred to as the reality gap (RG). In recent years, researchers have explored various approaches to address the reality gap issue, which can be broadly classified into two categories: transferring knowledge from simulation to reality (sim2real) and learning in digital twins (DTs). In this paper, we consider the solutions through the sim2real and DTs technologies, and review important applications and innovations in the field of autonomous driving. Meanwhile, we show the state-of-the-arts from the views of algorithms, models, and simulators, and elaborate the development process from sim2real to DTs. The presentation also illustrates the far-reaching effects of the development of sim2real and DTs in autonomous driving.
Motion Planning for Autonomous Driving: The State of the Art and Future Perspectives
Mar 29, 2023



Thanks to the augmented convenience, safety advantages, and potential commercial value, Intelligent vehicles (IVs) have attracted wide attention throughout the world. Although a few autonomous driving unicorns assert that IVs will be commercially deployable by 2025, their implementation is still restricted to small-scale validation due to various issues, among which precise computation of control commands or trajectories by planning methods remains a prerequisite for IVs. This paper aims to review state-of-the-art planning methods, including pipeline planning and end-to-end planning methods. In terms of pipeline methods, a survey of selecting algorithms is provided along with a discussion of the expansion and optimization mechanisms, whereas in end-to-end methods, the training approaches and verification scenarios of driving tasks are points of concern. Experimental platforms are reviewed to facilitate readers in selecting suitable training and validation methods. Finally, the current challenges and future directions are discussed. The side-by-side comparison presented in this survey not only helps to gain insights into the strengths and limitations of the reviewed methods but also assists with system-level design choices.