 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from the Field: An Adaptable Lifecycle Approach to Applied Dialogue Summarization
Jan 13, 2026Summarization of multi-party dialogues is a critical capability in industry, enhancing knowledge transfer and operational effectiveness across many domains. However, automatically generating high-quality summaries is challenging, as the ideal summary must satisfy a set of complex, multi-faceted requirements. While summarization has received immense attention in research, prior work has primarily utilized static datasets and benchmarks, a condition rare in practical scenarios where requirements inevitably evolve. In this work, we present an industry case study on developing an agentic system to summarize multi-party interactions. We share practical insights spanning the full development lifecycle to guide practitioners in building reliable, adaptable summarization systems, as well as to inform future research, covering: 1) robust methods for evaluation despite evolving requirements and task subjectivity, 2) component-wise optimization enabled by the task decomposition inherent in an agentic architecture, 3) the impact of upstream data bottlenecks, and 4) the realities of vendor lock-in due to the poor transferability of LLM prompts.
PaniniQA: Enhancing Patient Education Through Interactive Question Answering
Aug 21, 2023Patient portal allows discharged patients to access their personalized discharge instructions in electronic health records (EHRs). However, many patients have difficulty understanding or memorizing their discharge instructions. In this paper, we present PaniniQA, a patient-centric interactive question answering system designed to help patients understand their discharge instructions. PaniniQA first identifies important clinical content from patients' discharge instructions and then formulates patient-specific educational questions. In addition, PaniniQA is also equipped with answer verification functionality to provide timely feedback to correct patients' misunderstandings. Our comprehensive automatic and human evaluation results demonstrate our PaniniQA is capable of improving patients' mastery of their medical instructions through effective interactions
Re2G: Retrieve, Rerank, Generate
Jul 13, 2022
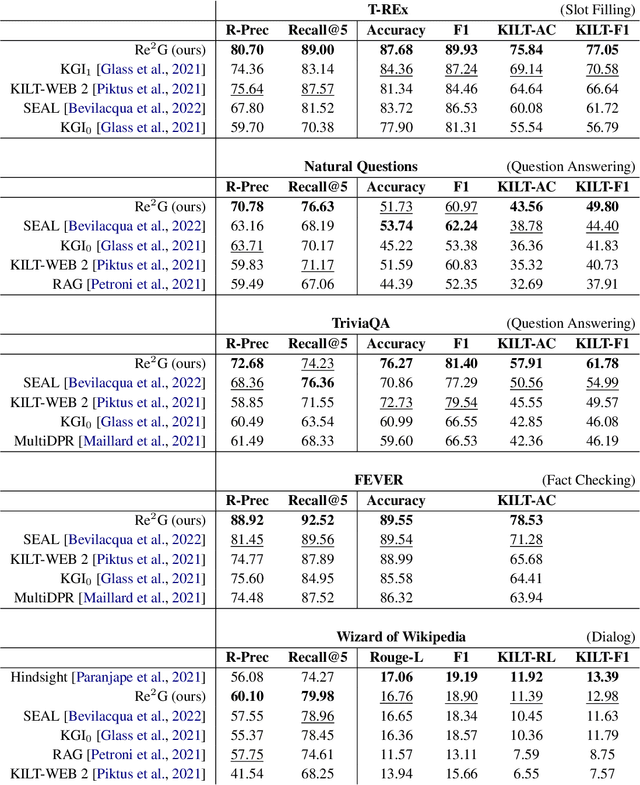
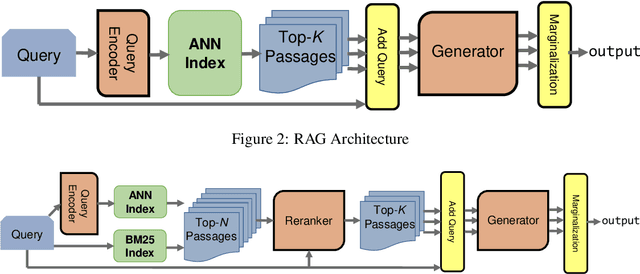
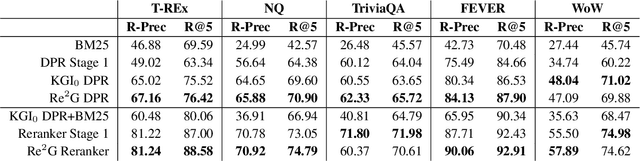
As demonstrated by GPT-3 and T5, transformers grow in capability as parameter spaces become larger and larger. However, for tasks that require a large amount of knowledge, non-parametric memory allows models to grow dramatically with a sub-linear increase in computational cost and GPU memory requirements. Recent models such as RAG and REALM have introduced retrieval into conditional generation. These models incorporate neural initial retrieval from a corpus of passages. We build on this line of research, proposing Re2G, which combines both neural initial retrieval and reranking into a BART-based sequence-to-sequence generation. Our reranking approach also permits merging retrieval results from sources with incomparable scores, enabling an ensemble of BM25 and neural initial retrieval. To train our system end-to-end, we introduce a novel variation of knowledge distillation to train the initial retrieval, reranker, and generation using only ground truth on the target sequence output. We find large gains in four diverse tasks: zero-shot slot filling, question answering, fact-checking, and dialog, with relative gains of 9% to 34% over the previous state-of-the-art on the KILT leaderboard. We make our code available as open source at https://github.com/IBM/kgi-slot-filling/tree/re2g.
Learning as Conversation: Dialogue Systems Reinforced for Information Acquisition
May 29, 2022
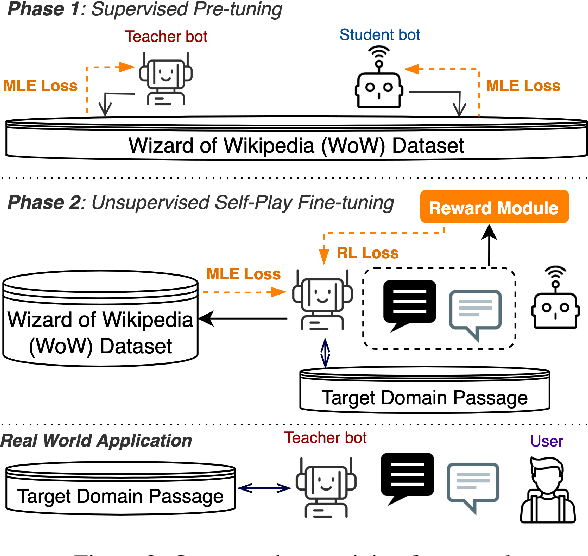

We propose novel AI-empowered chat bots for learning as conversation where a user does not read a passage but gains information and knowledge through conversation with a teacher bot. Our information-acquisition-oriented dialogue system employs a novel adaptation of reinforced self-play so that the system can be transferred to various domains without in-domain dialogue data, and can carry out conversations both informative and attentive to users. Our extensive subjective and objective evaluations on three large public data corpora demonstrate the effectiveness of our system to deliver knowledge-intensive and attentive conversations and help end users substantially gain knowledge without reading passages. Our code and datasets are publicly available for follow-up research.
Generating Classical Chinese Poems from Vernacular Chinese
Aug 31, 2019



Classical Chinese poetry is a jewel in the treasure house of Chinese culture. Previous poem generation models only allow users to employ keywords to interfere the meaning of generated poems, leaving the dominion of generation to the model. In this paper, we propose a novel task of generating classical Chinese poems from vernacular, which allows users to have more control over the semantic of generated poems. We adapt the approach of unsupervised machine translation (UMT) to our task. We use segmentation-based padding and reinforcement learning to address under-translation and over-translation respectively. According to experiments, our approach significantly improve the perplexity and BLEU compared with typical UMT models. Furthermore, we explored guidelines on how to write the input vernacular to generate better poems. Human evaluation showed our approach can generate high-quality poems which are comparable to amateur poems.
Path-Based Attention Neural Model for Fine-Grained Entity Typing
Jan 09, 2018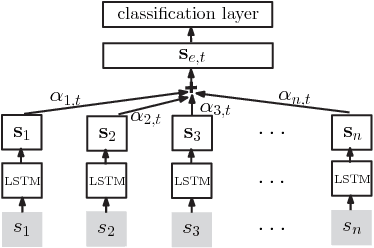
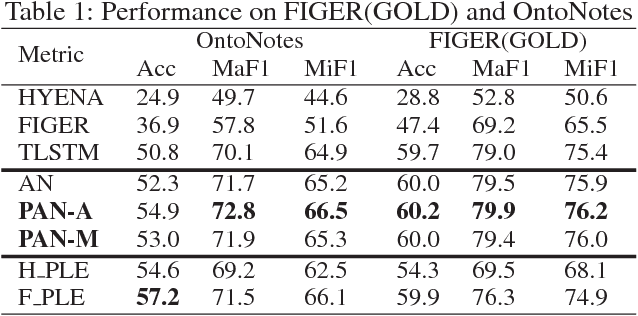
Fine-grained entity typing aims to assign entity mentions in the free text with types arranged in a hierarchical structure. Traditional distant supervision based methods employ a structured data source as a weak supervision and do not need hand-labeled data, but they neglect the label noise in the automatically labeled training corpus. Although recent studies use many features to prune wrong data ahead of training, they suffer from error propagation and bring much complexity. In this paper, we propose an end-to-end typing model, called the path-based attention neural model (PAN), to learn a noise- robust performance by leveraging the hierarchical structure of types. Experiments demonstrate its effectiveness.