 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurOCS: Neural NOCS Supervision for Monocular 3D Object Localization
May 28, 2023Monocular 3D object localization in driving scenes is a crucial task, but challenging due to its ill-posed nature. Estimating 3D coordinates for each pixel on the object surface holds great potential as it provides dense 2D-3D geometric constraints for the underlying PnP problem. However, high-quality ground truth supervision is not available in driving scenes due to sparsity and various artifacts of Lidar data, as well as the practical infeasibility of collecting per-instance CAD models. In this work, we present NeurOCS, a framework that uses instance masks and 3D boxes as input to learn 3D object shapes by means of differentiable rendering, which further serves as supervision for learning dense object coordinates. Our approach rests on insights in learning a category-level shape prior directly from real driving scenes, while properly handling single-view ambiguities. Furthermore, we study and make critical design choices to learn object coordinates more effectively from an object-centric view. Altogether, our framework leads to new state-of-the-art in monocular 3D localization that ranks 1st on the KITTI-Object benchmark among published monocular methods.
DDM-NET: End-to-end learning of keypoint feature Detection, Description and Matching for 3D localization
Dec 08, 2022



In this paper, we propose an end-to-end framework that jointly learns keypoint detection, descriptor representation and cross-frame matching for the task of image-based 3D localization. Prior art has tackled each of these components individually, purportedly aiming to alleviate difficulties in effectively train a holistic network. We design a self-supervised image warping correspondence loss for both feature detection and matching, a weakly-supervised epipolar constraints loss on relative camera pose learning, and a directional matching scheme that detects key-point features in a source image and performs coarse-to-fine correspondence search on the target image. We leverage this framework to enforce cycle consistency in our matching module. In addition, we propose a new loss to robustly handle both definite inlier/outlier matches and less-certain matches. The integration of these learning mechanisms enables end-to-end training of a single network performing all three localization components. Bench-marking our approach on public data-sets, exemplifies how such an end-to-end framework is able to yield more accurate localization that out-performs both traditional methods as well as state-of-the-art weakly supervised methods.
LASER: LAtent SpacE Rendering for 2D Visual Localization
Apr 01, 2022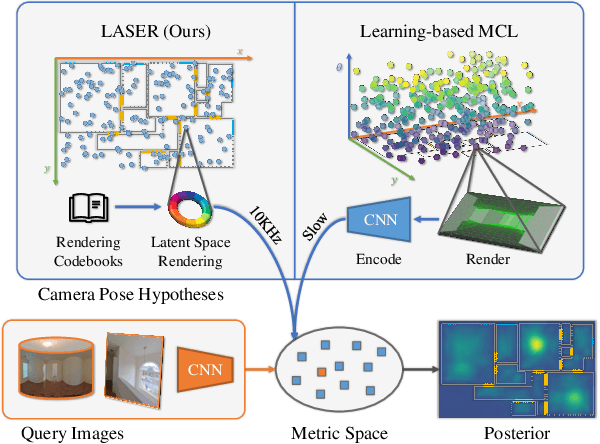
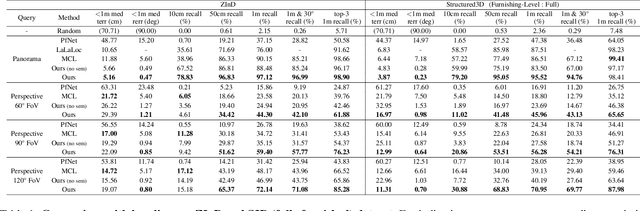
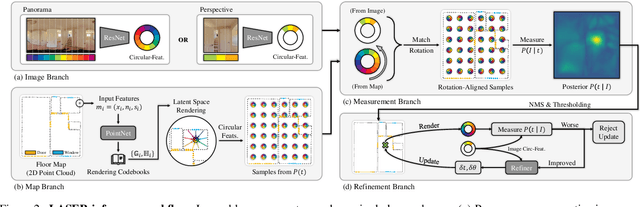
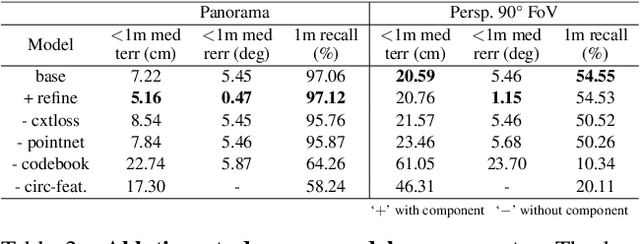
We present LASER, an image-based Monte Carlo Localization (MCL) framework for 2D floor maps. LASER introduces the concept of latent space rendering, where 2D pose hypotheses on the floor map are directly rendered into a geometrically-structured latent space by aggregating viewing ray features. Through a tightly coupled rendering codebook scheme, the viewing ray features are dynamically determined at rendering-time based on their geometries (i.e. length, incident-angle), endowing our representation with view-dependent fine-grain variability. Our codebook scheme effectively disentangles feature encoding from rendering, allowing the latent space rendering to run at speeds above 10KHz. Moreover, through metric learning, our geometrically-structured latent space is common to both pose hypotheses and query images with arbitrary field of views. As a result, LASER achieves state-of-the-art performance on large-scale indoor localization datasets (i.e. ZInD and Structured3D) for both panorama and perspective image queries, while significantly outperforming existing learning-based methods in speed.
GTT-Net: Learned Generalized Trajectory Triangulation
Sep 08, 2021

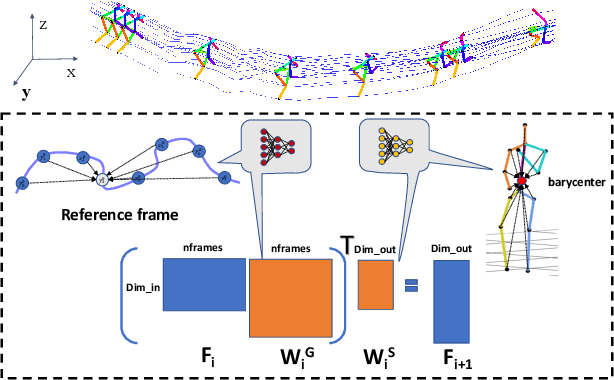
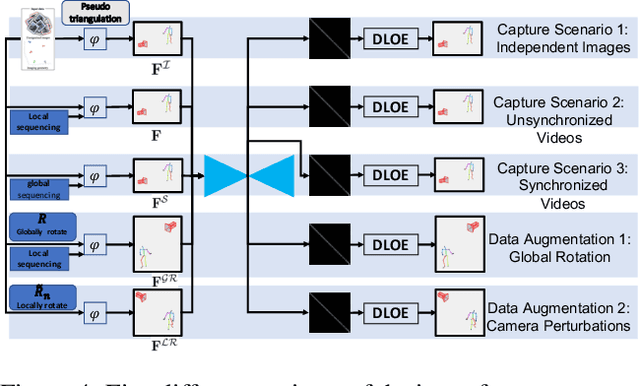
We present GTT-Net, a supervised learning framework for the reconstruction of sparse dynamic 3D geometry. We build on a graph-theoretic formulation of the generalized trajectory triangulation problem, where non-concurrent multi-view imaging geometry is known but global image sequencing is not provided. GTT-Net learns pairwise affinities modeling the spatio-temporal relationships among our input observations and leverages them to determine 3D geometry estimates. Experiments reconstructing 3D motion-capture sequences show GTT-Net outperforms the state of the art in terms of accuracy and robustness. Within the context of articulated motion reconstruction, our proposed architecture is 1) able to learn and enforce semantic 3D motion priors for shared training and test domains, while being 2) able to generalize its performance across different training and test domains. Moreover, GTT-Net provides a computationally streamlined framework for trajectory triangulation with applications to multi-instance reconstruction and event segmentation.
VOLDOR-SLAM: For the Times When Feature-Based or Direct Methods Are Not Good Enough
Apr 14, 2021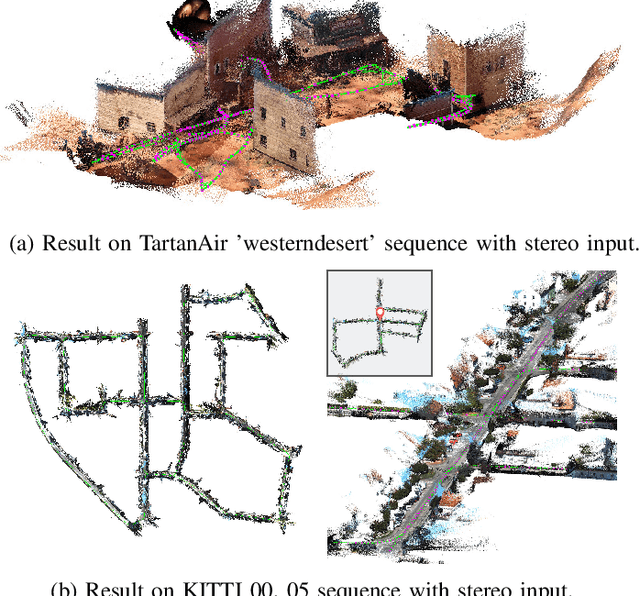
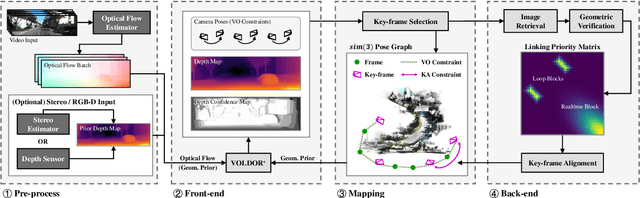
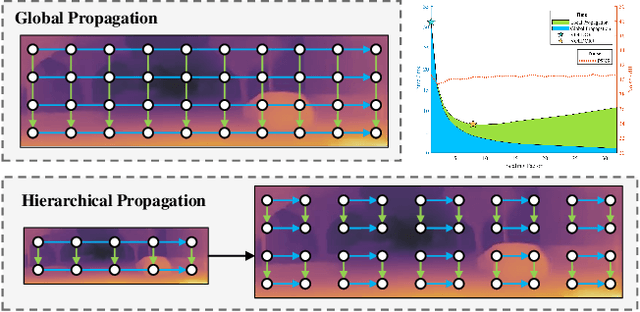
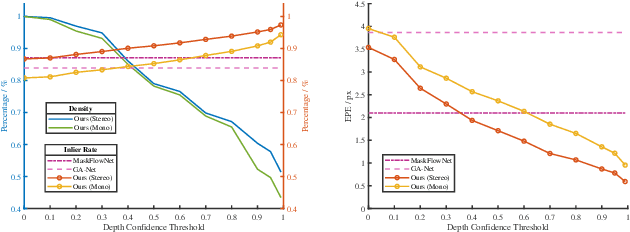
We present a dense-indirect SLAM system using external dense optical flows as input. We extend the recent probabilistic visual odometry model VOLDOR [Min et al. CVPR'20], by incorporating the use of geometric priors to 1) robustly bootstrap estimation from monocular capture, while 2) seamlessly supporting stereo and/or RGB-D input imagery. Our customized back-end tightly couples our intermediate geometric estimates with an adaptive priority scheme managing the connectivity of an incremental pose graph. We leverage recent advances in dense optical flow methods to achieve accurate and robust camera pose estimates, while constructing fine-grain globally-consistent dense environmental maps. Our open source implementation [https://github.com/htkseason/VOLDOR] operates online at around 15 FPS on a single GTX1080Ti GPU.
VOLDOR: Visual Odometry from Log-logistic Dense Optical flow Residuals
Apr 14, 2021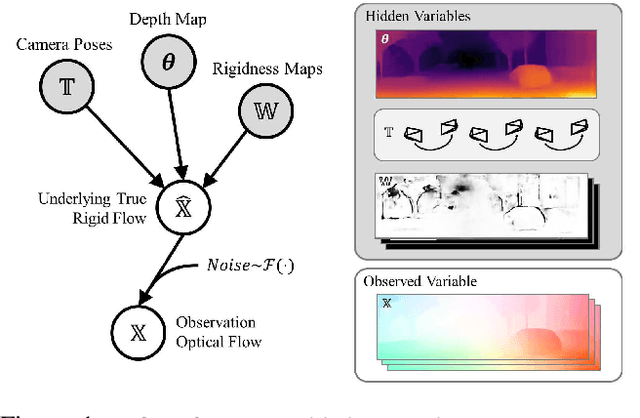

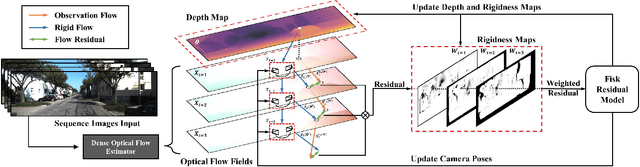
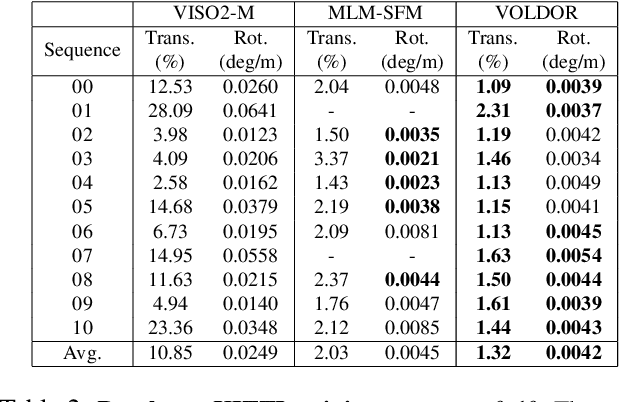
We propose a dense indirect visual odometry method taking as input externally estimated optical flow fields instead of hand-crafted feature correspondences. We define our problem as a probabilistic model and develop a generalized-EM formulation for the joint inference of camera motion, pixel depth, and motion-track confidence. Contrary to traditional methods assuming Gaussian-distributed observation errors, we supervise our inference framework under an (empirically validated) adaptive log-logistic distribution model. Moreover, the log-logistic residual model generalizes well to different state-of-the-art optical flow methods, making our approach modular and agnostic to the choice of optical flow estimators. Our method achieved top-ranking results on both TUM RGB-D and KITTI odometry benchmarks. Our open-sourced implementation is inherently GPU-friendly with only linear computational and storage growth.
Discrete Laplace Operator Estimation for Dynamic 3D Reconstruction
Aug 29, 2019

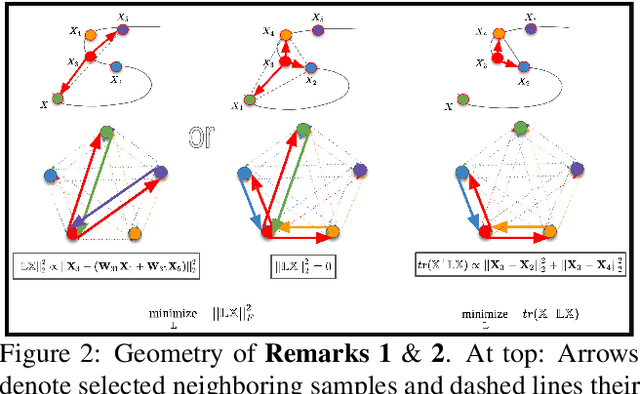

We present a general paradigm for dynamic 3D reconstruction from multiple independent and uncontrolled image sources having arbitrary temporal sampling density and distribution. Our graph-theoretic formulation models the Spatio-temporal relationships among our observations in terms of the joint estimation of their 3D geometry and its discrete Laplace operator. Towards this end, we define a tri-convex optimization framework that leverages the geometric properties and dependencies found among a Euclideanshape-space and the discrete Laplace operator describing its local and global topology. We present a reconstructability analysis, experiments on motion capture data and multi-view image datasets, as well as explore applications to geometry-based event segmentation and data association.
Self-expressive Dictionary Learning for Dynamic 3D Reconstruction
May 22, 2016
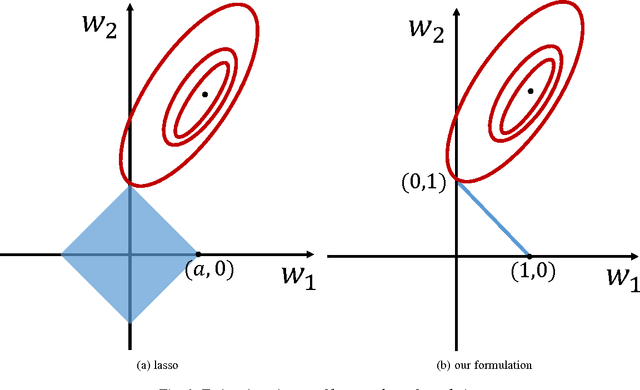
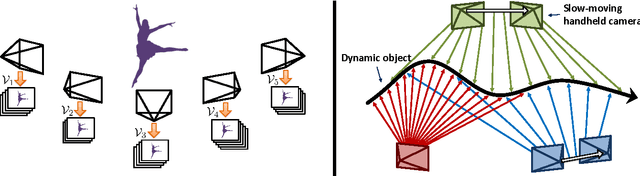
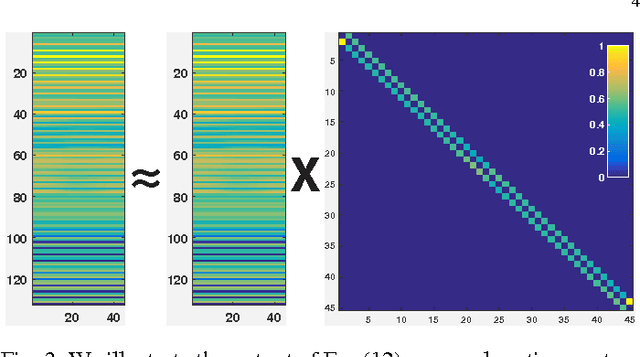
We target the problem of sparse 3D reconstruction of dynamic objects observed by multiple unsynchronized video cameras with unknown temporal overlap. To this end, we develop a framework to recover the unknown structure without sequencing information across video sequences. Our proposed compressed sensing framework poses the estimation of 3D structure as the problem of dictionary learning, where the dictionary is defined as an aggregation of the temporally varying 3D structures. Given the smooth motion of dynamic objects, we observe any element in the dictionary can be well approximated by a sparse linear combination of other elements in the same dictionary (i. e. self-expression). Moreover, the sparse coefficients describing a locally linear 3D structural interpolation reveal the local sequencing information. Our formulation optimizes a biconvex cost function that leverages a compressed sensing formulation and enforces both structural dependency coherence across video streams, as well as motion smoothness across estimates from common video sources. We further analyze the reconstructability of our approach under different capture scenarios, and its comparison and relation to existing methods. Experimental results on large amounts of synthetic data as well as real imagery demonstrate the effectiveness of our approach.