 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep View Morphing
Mar 07, 2017



Recently, convolutional neural networks (CNN) have been successfully applied to view synthesis problems. However, such CNN-based methods can suffer from lack of texture details, shape distortions, or high computational complexity. In this paper, we propose a novel CNN architecture for view synthesis called "Deep View Morphing" that does not suffer from these issues. To synthesize a middle view of two input images, a rectification network first rectifies the two input images. An encoder-decoder network then generates dense correspondences between the rectified images and blending masks to predict the visibility of pixels of the rectified images in the middle view. A view morphing network finally synthesizes the middle view using the dense correspondences and blending masks. We experimentally show the proposed method significantly outperforms the state-of-the-art CNN-based view synthesis method.
Self-expressive Dictionary Learning for Dynamic 3D Reconstruction
May 22, 2016
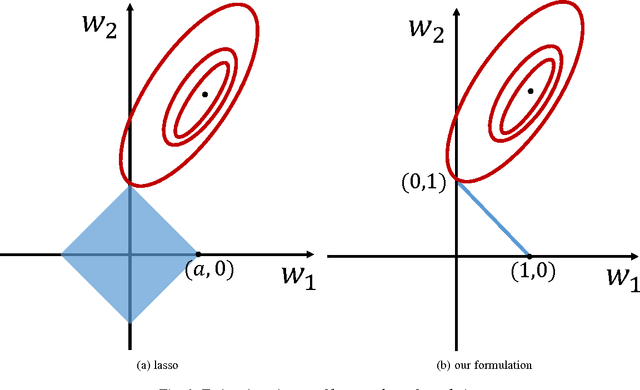
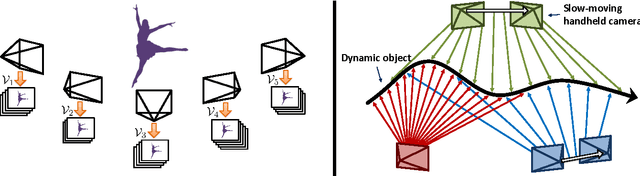
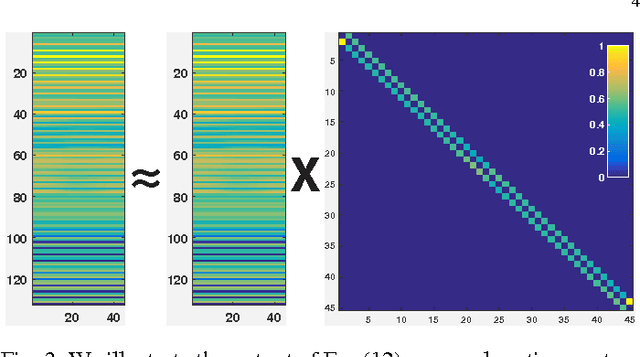
We target the problem of sparse 3D reconstruction of dynamic objects observed by multiple unsynchronized video cameras with unknown temporal overlap. To this end, we develop a framework to recover the unknown structure without sequencing information across video sequences. Our proposed compressed sensing framework poses the estimation of 3D structure as the problem of dictionary learning, where the dictionary is defined as an aggregation of the temporally varying 3D structures. Given the smooth motion of dynamic objects, we observe any element in the dictionary can be well approximated by a sparse linear combination of other elements in the same dictionary (i. e. self-expression). Moreover, the sparse coefficients describing a locally linear 3D structural interpolation reveal the local sequencing information. Our formulation optimizes a biconvex cost function that leverages a compressed sensing formulation and enforces both structural dependency coherence across video streams, as well as motion smoothness across estimates from common video sources. We further analyze the reconstructability of our approach under different capture scenarios, and its comparison and relation to existing methods. Experimental results on large amounts of synthetic data as well as real imagery demonstrate the effectiveness of our approach.