 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurformer v2: A Multimodal Classifier for Surface Understanding from Touch and Vision
Sep 04, 2025
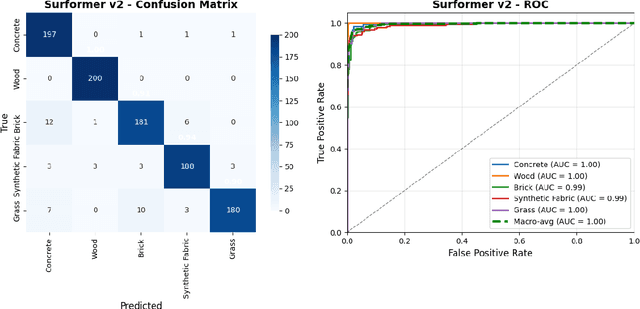
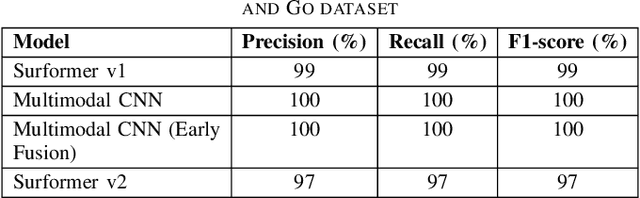
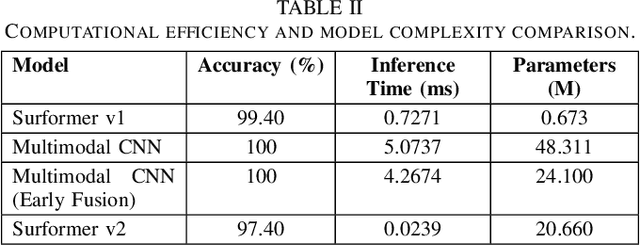
Multimodal surface material classification plays a critical role in advancing tactile perception for robotic manipulation and interaction. In this paper, we present Surformer v2, an enhanced multi-modal classification architecture designed to integrate visual and tactile sensory streams through a late(decision level) fusion mechanism. Building on our earlier Surformer v1 framework [1], which employed handcrafted feature extraction followed by mid-level fusion architecture with multi-head cross-attention layers, Surformer v2 integrates the feature extraction process within the model itself and shifts to late fusion. The vision branch leverages a CNN-based classifier(Efficient V-Net), while the tactile branch employs an encoder-only transformer model, allowing each modality to extract modality-specific features optimized for classification. Rather than merging feature maps, the model performs decision-level fusion by combining the output logits using a learnable weighted sum, enabling adaptive emphasis on each modality depending on data context and training dynamics. We evaluate Surformer v2 on the Touch and Go dataset [2], a multi-modal benchmark comprising surface images and corresponding tactile sensor readings. Our results demonstrate that Surformer v2 performs well, maintaining competitive inference speed, suitable for real-time robotic applications. These findings underscore the effectiveness of decision-level fusion and transformer-based tactile modeling for enhancing surface understanding in multi-modal robotic perception.
FALCON: Autonomous Cyber Threat Intelligence Mining with LLMs for IDS Rule Generation
Aug 26, 2025Signature-based Intrusion Detection Systems (IDS) detect malicious activities by matching network or host activity against predefined rules. These rules are derived from extensive Cyber Threat Intelligence (CTI), which includes attack signatures and behavioral patterns obtained through automated tools and manual threat analysis, such as sandboxing. The CTI is then transformed into actionable rules for the IDS engine, enabling real-time detection and prevention. However, the constant evolution of cyber threats necessitates frequent rule updates, which delay deployment time and weaken overall security readiness. Recent advancements in agentic systems powered by Large Language Models (LLMs) offer the potential for autonomous IDS rule generation with internal evaluation. We introduce FALCON, an autonomous agentic framework that generates deployable IDS rules from CTI data in real-time and evaluates them using built-in multi-phased validators. To demonstrate versatility, we target both network (Snort) and host-based (YARA) mediums and construct a comprehensive dataset of IDS rules with their corresponding CTIs. Our evaluations indicate FALCON excels in automatic rule generation, with an average of 95% accuracy validated by qualitative evaluation with 84% inter-rater agreement among multiple cybersecurity analysts across all metrics. These results underscore the feasibility and effectiveness of LLM-driven data mining for real-time cyber threat mitigation.
Towards a HIPAA Compliant Agentic AI System in Healthcare
Apr 24, 2025Agentic AI systems powered by Large Language Models (LLMs) as their foundational reasoning engine, are transforming clinical workflows such as medical report generation and clinical summarization by autonomously analyzing sensitive healthcare data and executing decisions with minimal human oversight. However, their adoption demands strict compliance with regulatory frameworks such as Health Insurance Portability and Accountability Act (HIPAA), particularly when handling Protected Health Information (PHI). This work-in-progress paper introduces a HIPAA-compliant Agentic AI framework that enforces regulatory compliance through dynamic, context-aware policy enforcement. Our framework integrates three core mechanisms: (1) Attribute-Based Access Control (ABAC) for granular PHI governance, (2) a hybrid PHI sanitization pipeline combining regex patterns and BERT-based model to minimize leakage, and (3) immutable audit trails for compliance verification.
From Patient Consultations to Graphs: Leveraging LLMs for Patient Journey Knowledge Graph Construction
Mar 18, 2025The transition towards patient-centric healthcare necessitates a comprehensive understanding of patient journeys, which encompass all healthcare experiences and interactions across the care spectrum. Existing healthcare data systems are often fragmented and lack a holistic representation of patient trajectories, creating challenges for coordinated care and personalized interventions. Patient Journey Knowledge Graphs (PJKGs) represent a novel approach to addressing the challenge of fragmented healthcare data by integrating diverse patient information into a unified, structured representation. This paper presents a methodology for constructing PJKGs using Large Language Models (LLMs) to process and structure both formal clinical documentation and unstructured patient-provider conversations. These graphs encapsulate temporal and causal relationships among clinical encounters, diagnoses, treatments, and outcomes, enabling advanced temporal reasoning and personalized care insights. The research evaluates four different LLMs, such as Claude 3.5, Mistral, Llama 3.1, and Chatgpt4o, in their ability to generate accurate and computationally efficient knowledge graphs. Results demonstrate that while all models achieved perfect structural compliance, they exhibited variations in medical entity processing and computational efficiency. The paper concludes by identifying key challenges and future research directions. This work contributes to advancing patient-centric healthcare through the development of comprehensive, actionable knowledge graphs that support improved care coordination and outcome prediction.
The AI Pentad, the CHARME$^{2}$D Model, and an Assessment of Current-State AI Regulation
Mar 08, 2025



Artificial Intelligence (AI) has made remarkable progress in the past few years with AI-enabled applications beginning to permeate every aspect of our society. Despite the widespread consensus on the need to regulate AI, there remains a lack of a unified approach to framing, developing, and assessing AI regulations. Many of the existing methods take a value-based approach, for example, accountability, fairness, free from bias, transparency, and trust. However, these methods often face challenges at the outset due to disagreements in academia over the subjective nature of these definitions. This paper aims to establish a unifying model for AI regulation from the perspective of core AI components. We first introduce the AI Pentad, which comprises the five essential components of AI: humans and organizations, algorithms, data, computing, and energy. We then review AI regulatory enablers, including AI registration and disclosure, AI monitoring, and AI enforcement mechanisms. Subsequently, we present the CHARME$^{2}$D Model to explore further the relationship between the AI Pentad and AI regulatory enablers. Finally, we apply the CHARME$^{2}$D model to assess AI regulatory efforts in the European Union (EU), China, the United Arab Emirates (UAE), the United Kingdom (UK), and the United States (US), highlighting their strengths, weaknesses, and gaps. This comparative evaluation offers insights for future legislative work in the AI domain.
RAAD-LLM: Adaptive Anomaly Detection Using LLMs and RAG Integration
Mar 04, 2025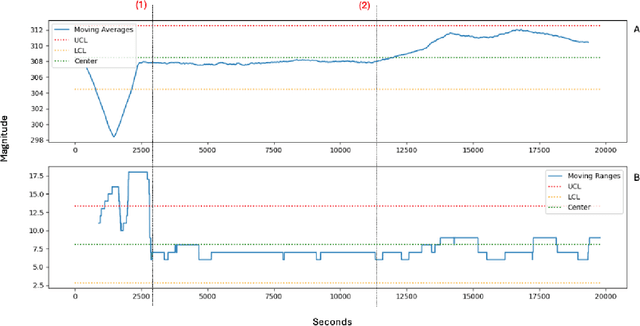
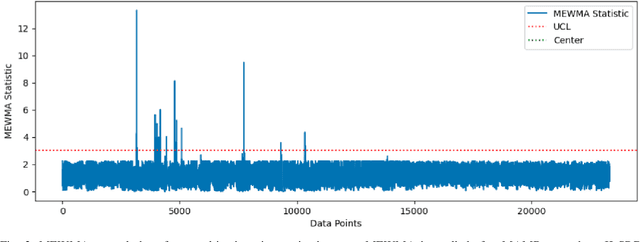
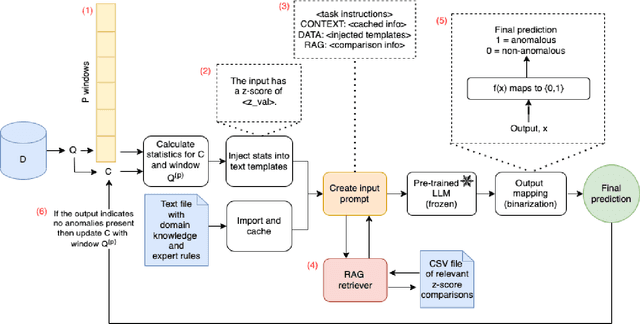
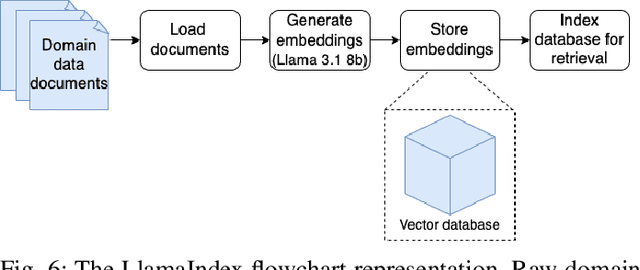
Anomaly detection in complex industrial environments poses unique challenges, particularly in contexts characterized by data sparsity and evolving operational conditions. Predictive maintenance (PdM) in such settings demands methodologies that are adaptive, transferable, and capable of integrating domain-specific knowledge. In this paper, we present RAAD-LLM, a novel framework for adaptive anomaly detection, leveraging large language models (LLMs) integrated with Retrieval-Augmented Generation (RAG). This approach addresses the aforementioned PdM challenges. By effectively utilizing domain-specific knowledge, RAAD-LLM enhances the detection of anomalies in time series data without requiring fine-tuning on specific datasets. The framework's adaptability mechanism enables it to adjust its understanding of normal operating conditions dynamically, thus increasing detection accuracy. We validate this methodology through a real-world application for a plastics manufacturing plant and the Skoltech Anomaly Benchmark (SKAB). Results show significant improvements over our previous model with an accuracy increase from 70.7 to 89.1 on the real-world dataset. By allowing for the enriching of input series data with semantics, RAAD-LLM incorporates multimodal capabilities that facilitate more collaborative decision-making between the model and plant operators. Overall, our findings support RAAD-LLM's ability to revolutionize anomaly detection methodologies in PdM, potentially leading to a paradigm shift in how anomaly detection is implemented across various industries.
CLINICSUM: Utilizing Language Models for Generating Clinical Summaries from Patient-Doctor Conversations
Dec 05, 2024



This paper presents ClinicSum, a novel framework designed to automatically generate clinical summaries from patient-doctor conversations. It utilizes a two-module architecture: a retrieval-based filtering module that extracts Subjective, Objective, Assessment, and Plan (SOAP) information from conversation transcripts, and an inference module powered by fine-tuned Pre-trained Language Models (PLMs), which leverage the extracted SOAP data to generate abstracted clinical summaries. To fine-tune the PLM, we created a training dataset of consisting 1,473 conversations-summaries pair by consolidating two publicly available datasets, FigShare and MTS-Dialog, with ground truth summaries validated by Subject Matter Experts (SMEs). ClinicSum's effectiveness is evaluated through both automatic metrics (e.g., ROUGE, BERTScore) and expert human assessments. Results show that ClinicSum outperforms state-of-the-art PLMs, demonstrating superior precision, recall, and F-1 scores in automatic evaluations and receiving high preference from SMEs in human assessment, making it a robust solution for automated clinical summarization.
AAD-LLM: Adaptive Anomaly Detection Using Large Language Models
Nov 01, 2024



For data-constrained, complex and dynamic industrial environments, there is a critical need for transferable and multimodal methodologies to enhance anomaly detection and therefore, prevent costs associated with system failures. Typically, traditional PdM approaches are not transferable or multimodal. This work examines the use of Large Language Models (LLMs) for anomaly detection in complex and dynamic manufacturing systems. The research aims to improve the transferability of anomaly detection models by leveraging Large Language Models (LLMs) and seeks to validate the enhanced effectiveness of the proposed approach in data-sparse industrial applications. The research also seeks to enable more collaborative decision-making between the model and plant operators by allowing for the enriching of input series data with semantics. Additionally, the research aims to address the issue of concept drift in dynamic industrial settings by integrating an adaptability mechanism. The literature review examines the latest developments in LLM time series tasks alongside associated adaptive anomaly detection methods to establish a robust theoretical framework for the proposed architecture. This paper presents a novel model framework (AAD-LLM) that doesn't require any training or finetuning on the dataset it is applied to and is multimodal. Results suggest that anomaly detection can be converted into a "language" task to deliver effective, context-aware detection in data-constrained industrial applications. This work, therefore, contributes significantly to advancements in anomaly detection methodologies.
Medical-GAT: Cancer Document Classification Leveraging Graph-Based Residual Network for Scenarios with Limited Data
Oct 19, 2024Accurate classification of cancer-related medical abstracts is crucial for healthcare management and research. However, obtaining large, labeled datasets in the medical domain is challenging due to privacy concerns and the complexity of clinical data. This scarcity of annotated data impedes the development of effective machine learning models for cancer document classification. To address this challenge, we present a curated dataset of 1,874 biomedical abstracts, categorized into thyroid cancer, colon cancer, lung cancer, and generic topics. Our research focuses on leveraging this dataset to improve classification performance, particularly in data-scarce scenarios. We introduce a Residual Graph Attention Network (R-GAT) with multiple graph attention layers that capture the semantic information and structural relationships within cancer-related documents. Our R-GAT model is compared with various techniques, including transformer-based models such as Bidirectional Encoder Representations from Transformers (BERT), RoBERTa, and domain-specific models like BioBERT and Bio+ClinicalBERT. We also evaluated deep learning models (CNNs, LSTMs) and traditional machine learning models (Logistic Regression, SVM). Additionally, we explore ensemble approaches that combine deep learning models to enhance classification. Various feature extraction methods are assessed, including Term Frequency-Inverse Document Frequency (TF-IDF) with unigrams and bigrams, Word2Vec, and tokenizers from BERT and RoBERTa. The R-GAT model outperforms other techniques, achieving precision, recall, and F1 scores of 0.99, 0.97, and 0.98 for thyroid cancer; 0.96, 0.94, and 0.95 for colon cancer; 0.96, 0.99, and 0.97 for lung cancer; and 0.95, 0.96, and 0.95 for generic topics.
Transfer Learning Applied to Computer Vision Problems: Survey on Current Progress, Limitations, and Opportunities
Sep 12, 2024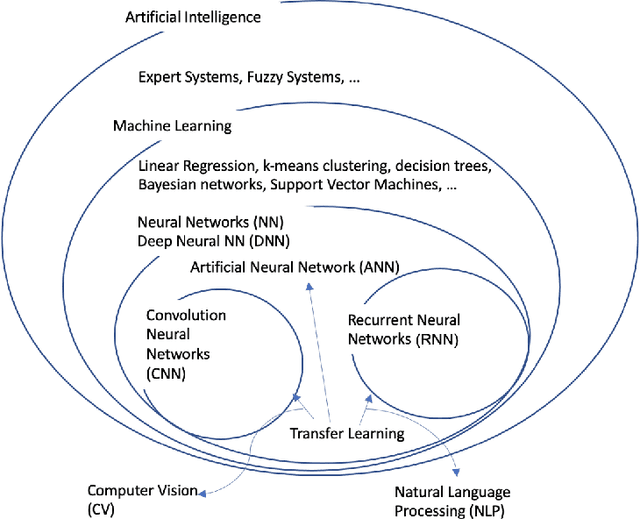


The field of Computer Vision (CV) has faced challenges. Initially, it relied on handcrafted features and rule-based algorithms, resulting in limited accuracy. The introduction of machine learning (ML) has brought progress, particularly Transfer Learning (TL), which addresses various CV problems by reusing pre-trained models. TL requires less data and computing while delivering nearly equal accuracy, making it a prominent technique in the CV landscape. Our research focuses on TL development and how CV applications use it to solve real-world problems. We discuss recent developments, limitations, and opportunities.