 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAAD-LLM: Adaptive Anomaly Detection Using LLMs and RAG Integration
Mar 04, 2025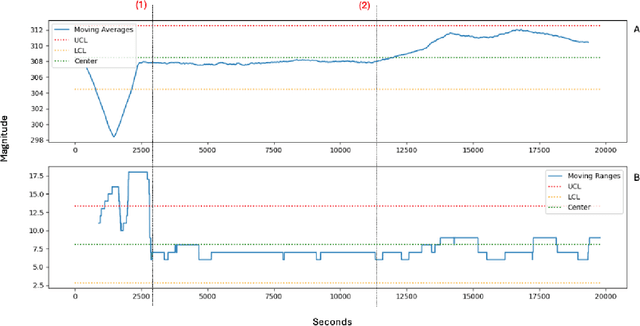
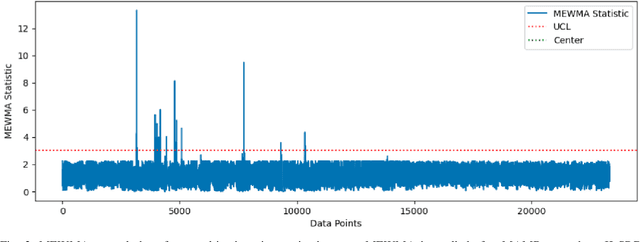
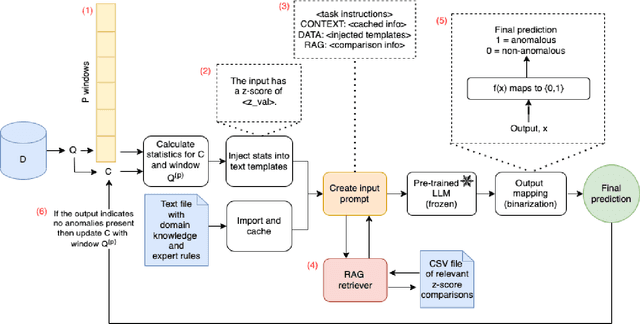
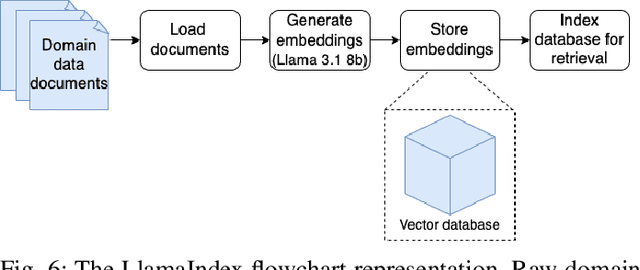
Anomaly detection in complex industrial environments poses unique challenges, particularly in contexts characterized by data sparsity and evolving operational conditions. Predictive maintenance (PdM) in such settings demands methodologies that are adaptive, transferable, and capable of integrating domain-specific knowledge. In this paper, we present RAAD-LLM, a novel framework for adaptive anomaly detection, leveraging large language models (LLMs) integrated with Retrieval-Augmented Generation (RAG). This approach addresses the aforementioned PdM challenges. By effectively utilizing domain-specific knowledge, RAAD-LLM enhances the detection of anomalies in time series data without requiring fine-tuning on specific datasets. The framework's adaptability mechanism enables it to adjust its understanding of normal operating conditions dynamically, thus increasing detection accuracy. We validate this methodology through a real-world application for a plastics manufacturing plant and the Skoltech Anomaly Benchmark (SKAB). Results show significant improvements over our previous model with an accuracy increase from 70.7 to 89.1 on the real-world dataset. By allowing for the enriching of input series data with semantics, RAAD-LLM incorporates multimodal capabilities that facilitate more collaborative decision-making between the model and plant operators. Overall, our findings support RAAD-LLM's ability to revolutionize anomaly detection methodologies in PdM, potentially leading to a paradigm shift in how anomaly detection is implemented across various industries.
AAD-LLM: Adaptive Anomaly Detection Using Large Language Models
Nov 01, 2024



For data-constrained, complex and dynamic industrial environments, there is a critical need for transferable and multimodal methodologies to enhance anomaly detection and therefore, prevent costs associated with system failures. Typically, traditional PdM approaches are not transferable or multimodal. This work examines the use of Large Language Models (LLMs) for anomaly detection in complex and dynamic manufacturing systems. The research aims to improve the transferability of anomaly detection models by leveraging Large Language Models (LLMs) and seeks to validate the enhanced effectiveness of the proposed approach in data-sparse industrial applications. The research also seeks to enable more collaborative decision-making between the model and plant operators by allowing for the enriching of input series data with semantics. Additionally, the research aims to address the issue of concept drift in dynamic industrial settings by integrating an adaptability mechanism. The literature review examines the latest developments in LLM time series tasks alongside associated adaptive anomaly detection methods to establish a robust theoretical framework for the proposed architecture. This paper presents a novel model framework (AAD-LLM) that doesn't require any training or finetuning on the dataset it is applied to and is multimodal. Results suggest that anomaly detection can be converted into a "language" task to deliver effective, context-aware detection in data-constrained industrial applications. This work, therefore, contributes significantly to advancements in anomaly detection methodologies.
Explainable Anomaly Detection: Counterfactual driven What-If Analysis
Aug 21, 2024



There exists three main areas of study inside of the field of predictive maintenance: anomaly detection, fault diagnosis, and remaining useful life prediction. Notably, anomaly detection alerts the stakeholder that an anomaly is occurring. This raises two fundamental questions: what is causing the fault and how can we fix it? Inside of the field of explainable artificial intelligence, counterfactual explanations can give that information in the form of what changes to make to put the data point into the opposing class, in this case "healthy". The suggestions are not always actionable which may raise the interest in asking "what if we do this instead?" In this work, we provide a proof of concept for utilizing counterfactual explanations as what-if analysis. We perform this on the PRONOSTIA dataset with a temporal convolutional network as the anomaly detector. Our method presents the counterfactuals in the form of a what-if analysis for this base problem to inspire future work for more complex systems and scenarios.
A Survey of Transformer Enabled Time Series Synthesis
Jun 04, 2024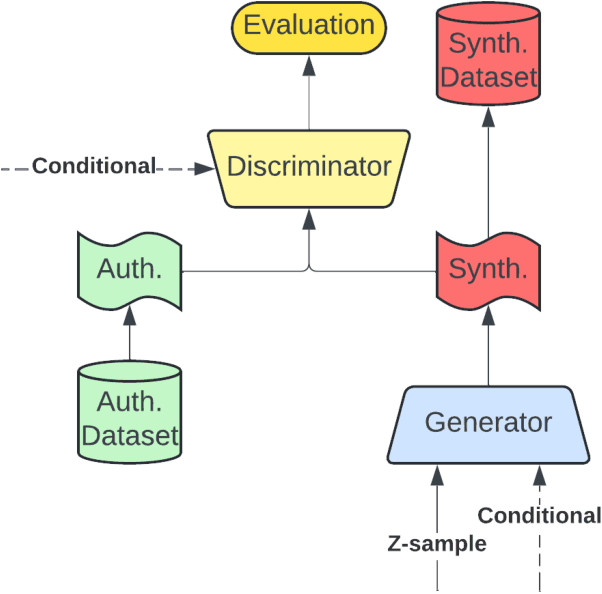
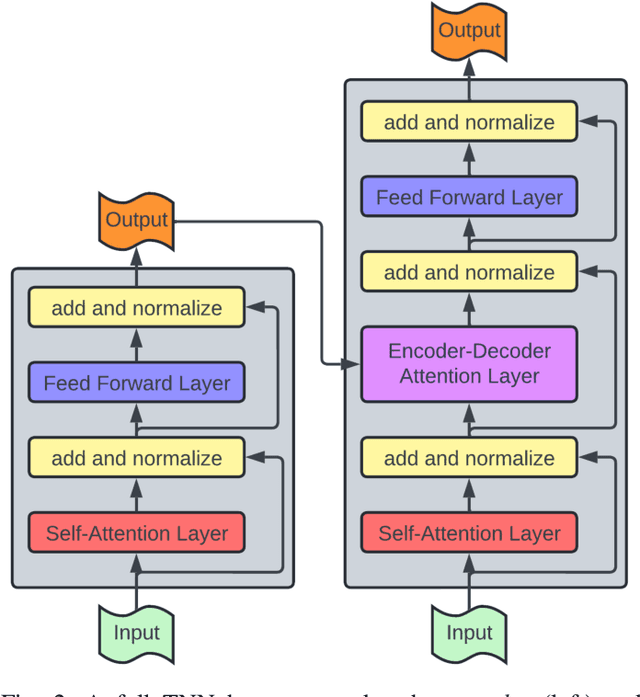


Generative AI has received much attention in the image and language domains, with the transformer neural network continuing to dominate the state of the art. Application of these models to time series generation is less explored, however, and is of great utility to machine learning, privacy preservation, and explainability research. The present survey identifies this gap at the intersection of the transformer, generative AI, and time series data, and reviews works in this sparsely populated subdomain. The reviewed works show great variety in approach, and have not yet converged on a conclusive answer to the problems the domain poses. GANs, diffusion models, state space models, and autoencoders were all encountered alongside or surrounding the transformers which originally motivated the survey. While too open a domain to offer conclusive insights, the works surveyed are quite suggestive, and several recommendations for best practice, and suggestions of valuable future work, are provided.
Generating Synthetic Time Series Data for Cyber-Physical Systems
Apr 12, 2024



Data augmentation is an important facilitator of deep learning applications in the time series domain. A gap is identified in the literature, demonstrating sparse exploration of the transformer, the dominant sequence model, for data augmentation in time series. A architecture hybridizing several successful priors is put forth and tested using a powerful time domain similarity metric. Results suggest the challenge of this domain, and several valuable directions for future work.
Eclectic Rule Extraction for Explainability of Deep Neural Network based Intrusion Detection Systems
Jan 18, 2024



This paper addresses trust issues created from the ubiquity of black box algorithms and surrogate explainers in Explainable Intrusion Detection Systems (X-IDS). While Explainable Artificial Intelligence (XAI) aims to enhance transparency, black box surrogate explainers, such as Local Interpretable Model-Agnostic Explanation (LIME) and SHapley Additive exPlanation (SHAP), are difficult to trust. The black box nature of these surrogate explainers makes the process behind explanation generation opaque and difficult to understand. To avoid this problem, one can use transparent white box algorithms such as Rule Extraction (RE). There are three types of RE algorithms: pedagogical, decompositional, and eclectic. Pedagogical methods offer fast but untrustworthy white-box explanations, while decompositional RE provides trustworthy explanations with poor scalability. This work explores eclectic rule extraction, which strikes a balance between scalability and trustworthiness. By combining techniques from pedagogical and decompositional approaches, eclectic rule extraction leverages the advantages of both, while mitigating some of their drawbacks. The proposed Hybrid X-IDS architecture features eclectic RE as a white box surrogate explainer for black box Deep Neural Networks (DNN). The presented eclectic RE algorithm extracts human-readable rules from hidden layers, facilitating explainable and trustworthy rulesets. Evaluations on UNSW-NB15 and CIC-IDS-2017 datasets demonstrate the algorithm's ability to generate rulesets with 99.9% accuracy, mimicking DNN outputs. The contributions of this work include the hybrid X-IDS architecture, the eclectic rule extraction algorithm applicable to intrusion detection datasets, and a thorough analysis of performance and explainability, demonstrating the trade-offs involved in rule extraction speed and accuracy.
Explainable Predictive Maintenance: A Survey of Current Methods, Challenges and Opportunities
Jan 15, 2024



Predictive maintenance is a well studied collection of techniques that aims to prolong the life of a mechanical system by using artificial intelligence and machine learning to predict the optimal time to perform maintenance. The methods allow maintainers of systems and hardware to reduce financial and time costs of upkeep. As these methods are adopted for more serious and potentially life-threatening applications, the human operators need trust the predictive system. This attracts the field of Explainable AI (XAI) to introduce explainability and interpretability into the predictive system. XAI brings methods to the field of predictive maintenance that can amplify trust in the users while maintaining well-performing systems. This survey on explainable predictive maintenance (XPM) discusses and presents the current methods of XAI as applied to predictive maintenance while following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 guidelines. We categorize the different XPM methods into groups that follow the XAI literature. Additionally, we include current challenges and a discussion on future research directions in XPM.
Explainable Intrusion Detection Systems Using Competitive Learning Techniques
Mar 30, 2023
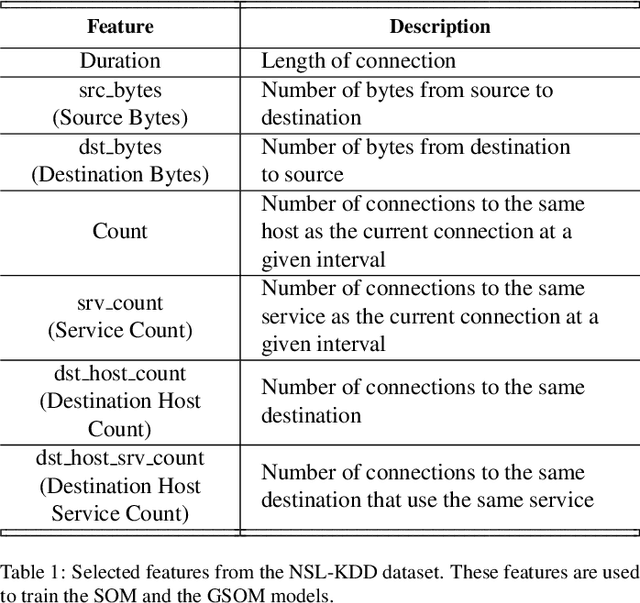

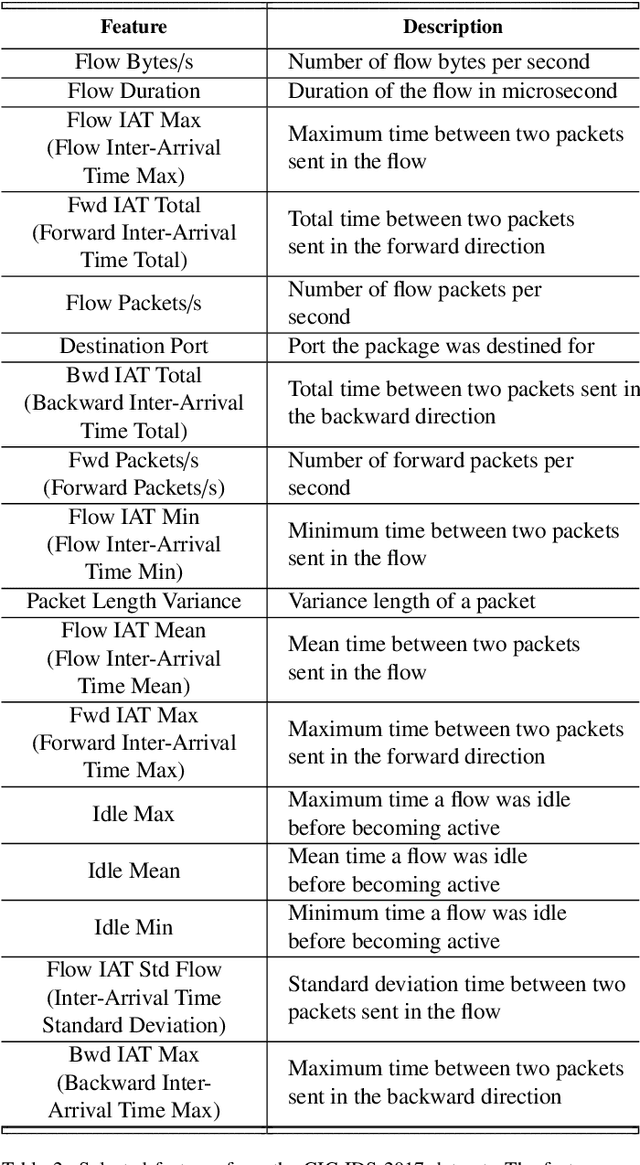
The current state of the art systems in Artificial Intelligence (AI) enabled intrusion detection use a variety of black box methods. These black box methods are generally trained using Error Based Learning (EBL) techniques with a focus on creating accurate models. These models have high performative costs and are not easily explainable. A white box Competitive Learning (CL) based eXplainable Intrusion Detection System (X-IDS) offers a potential solution to these problem. CL models utilize an entirely different learning paradigm than EBL approaches. This different learning process makes the CL family of algorithms innately explainable and less resource intensive. In this paper, we create an X-IDS architecture that is based on DARPA's recommendation for explainable systems. In our architecture we leverage CL algorithms like, Self Organizing Maps (SOM), Growing Self Organizing Maps (GSOM), and Growing Hierarchical Self Organizing Map (GHSOM). The resulting models can be data-mined to create statistical and visual explanations. Our architecture is tested using NSL-KDD and CIC-IDS-2017 benchmark datasets, and produces accuracies that are 1% - 3% less than EBL models. However, CL models are much more explainable than EBL models. Additionally, we use a pruning process that is able to significantly reduce the size of these CL based models. By pruning our models, we are able to increase prediction speeds. Lastly, we analyze the statistical and visual explanations generated by our architecture, and we give a strategy that users could use to help navigate the set of explanations. These explanations will help users build trust with an Intrusion Detection System (IDS), and allow users to discover ways to increase the IDS's potency.
Designing an Artificial Immune System inspired Intrusion Detection System
Aug 16, 2022
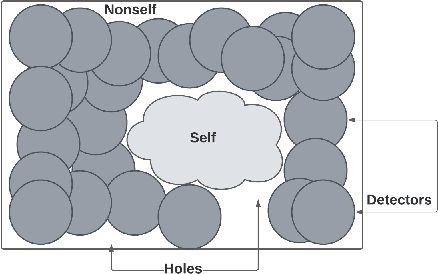
The Human Immune System (HIS) works to protect a body from infection, illness, and disease. This system can inspire cybersecurity professionals to design an Artificial Immune System (AIS) based Intrusion Detection System (IDS). These biologically inspired algorithms using Self/Nonself and Danger Theory can directly augmentIDS designs and implementations. In this paper, we include an examination into the elements of design necessary for building an AIS-IDS framework and present an architecture to create such systems.
Creating an Explainable Intrusion Detection System Using Self Organizing Maps
Jul 15, 2022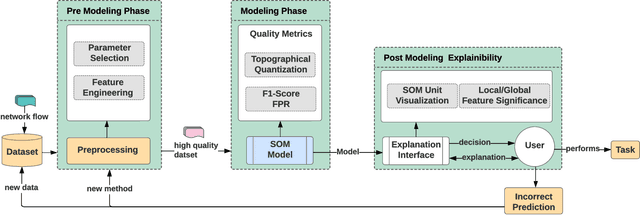
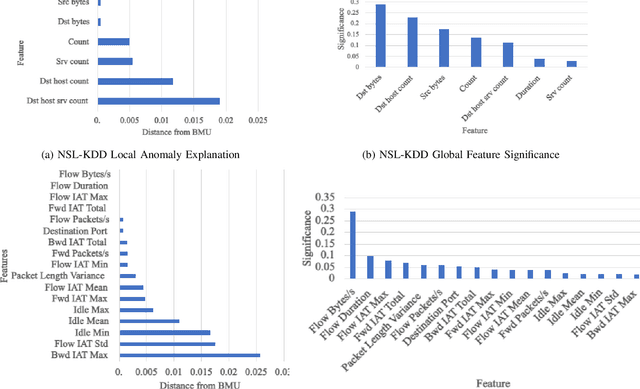
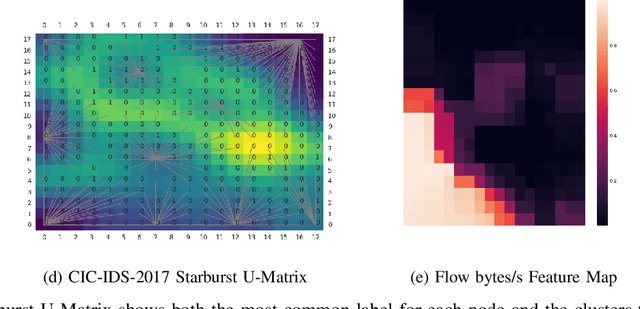
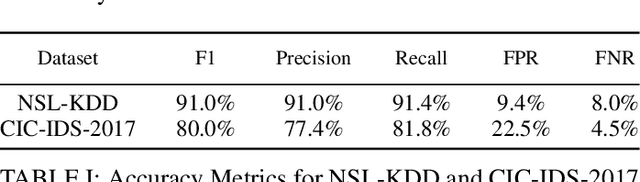
Modern Artificial Intelligence (AI) enabled Intrusion Detection Systems (IDS) are complex black boxes. This means that a security analyst will have little to no explanation or clarification on why an IDS model made a particular prediction. A potential solution to this problem is to research and develop Explainable Intrusion Detection Systems (X-IDS) based on current capabilities in Explainable Artificial Intelligence (XAI). In this paper, we create a Self Organizing Maps (SOMs) based X-IDS system that is capable of producing explanatory visualizations. We leverage SOM's explainability to create both global and local explanations. An analyst can use global explanations to get a general idea of how a particular IDS model computes predictions. Local explanations are generated for individual datapoints to explain why a certain prediction value was computed. Furthermore, our SOM based X-IDS was evaluated on both explanation generation and traditional accuracy tests using the NSL-KDD and the CIC-IDS-2017 datasets.