 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLINICSUM: Utilizing Language Models for Generating Clinical Summaries from Patient-Doctor Conversations
Dec 05, 2024



This paper presents ClinicSum, a novel framework designed to automatically generate clinical summaries from patient-doctor conversations. It utilizes a two-module architecture: a retrieval-based filtering module that extracts Subjective, Objective, Assessment, and Plan (SOAP) information from conversation transcripts, and an inference module powered by fine-tuned Pre-trained Language Models (PLMs), which leverage the extracted SOAP data to generate abstracted clinical summaries. To fine-tune the PLM, we created a training dataset of consisting 1,473 conversations-summaries pair by consolidating two publicly available datasets, FigShare and MTS-Dialog, with ground truth summaries validated by Subject Matter Experts (SMEs). ClinicSum's effectiveness is evaluated through both automatic metrics (e.g., ROUGE, BERTScore) and expert human assessments. Results show that ClinicSum outperforms state-of-the-art PLMs, demonstrating superior precision, recall, and F-1 scores in automatic evaluations and receiving high preference from SMEs in human assessment, making it a robust solution for automated clinical summarization.
From Questions to Insightful Answers: Building an Informed Chatbot for University Resources
May 13, 2024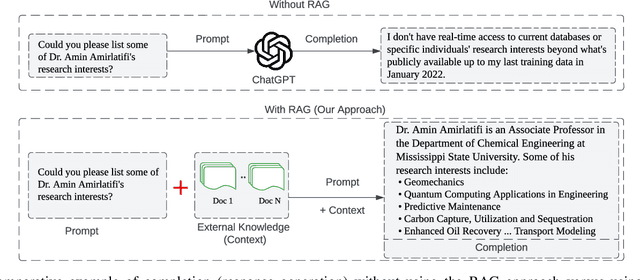
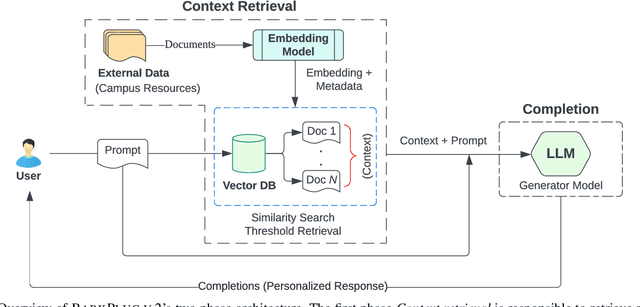
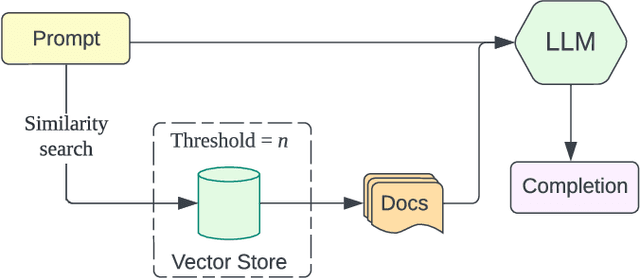
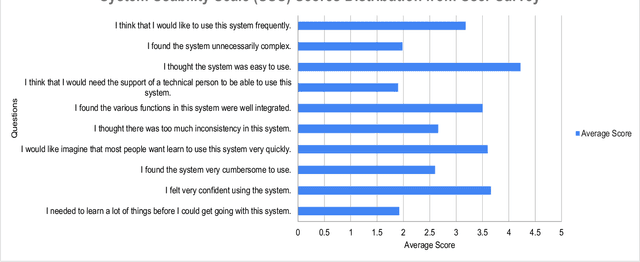
This paper presents BARKPLUG V.2, a Large Language Model (LLM)-based chatbot system built using Retrieval Augmented Generation (RAG) pipelines to enhance the user experience and access to information within academic settings.The objective of BARKPLUG V.2 is to provide information to users about various campus resources, including academic departments, programs, campus facilities, and student resources at a university setting in an interactive fashion. Our system leverages university data as an external data corpus and ingests it into our RAG pipelines for domain-specific question-answering tasks. We evaluate the effectiveness of our system in generating accurate and pertinent responses for Mississippi State University, as a case study, using quantitative measures, employing frameworks such as Retrieval Augmented Generation Assessment(RAGAS). Furthermore, we evaluate the usability of this system via subjective satisfaction surveys using the System Usability Scale (SUS). Our system demonstrates impressive quantitative performance, with a mean RAGAS score of 0.96, and experience, as validated by usability assessments.