 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGamma2Patterns: Deep Cognitive Attention Region Identification and Gamma-Alpha Pattern Analysis
Jan 09, 2026Deep cognitive attention is characterized by heightened gamma oscillations and coordinated visual behavior. Despite the physiological importance of these mechanisms, computational studies rarely synthesize these modalities or identify the neural regions most responsible for sustained focus. To address this gap, this work introduces Gamma2Patterns, a multimodal framework that characterizes deep cognitive attention by leveraging complementary Gamma and Alpha band EEG activity alongside Eye-tracking measurements. Using the SEED-IV dataset [1], we extract spectral power, burst-based temporal dynamics, and fixation-saccade-pupil signals across 62 channels or electrodes to analyze how neural activation differs between high-focus (Gamma-dominant) and low-focus (Alpha-dominant) states. Our findings reveal that frontopolar, temporal, anterior frontal, and parieto-occipital regions exhibit the strongest Gamma power and burst rates, indicating their dominant role in deep attentional engagement, while Eye-tracking signals confirm complementary contributions from frontal, frontopolar, and frontotemporal regions. Furthermore, we show that Gamma power and burst duration provide more discriminative markers of deep focus than Alpha power alone, demonstrating their value for attention decoding. Collectively, these results establish a multimodal, evidence-based map of cortical regions and oscillatory signatures underlying deep focus, providing a neurophysiological foundation for future brain-inspired attention mechanisms in AI systems.
Surformer v2: A Multimodal Classifier for Surface Understanding from Touch and Vision
Sep 04, 2025
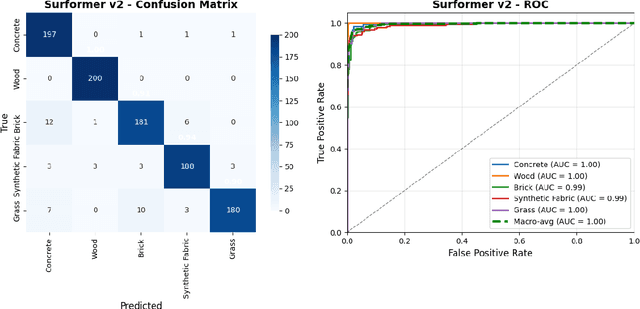
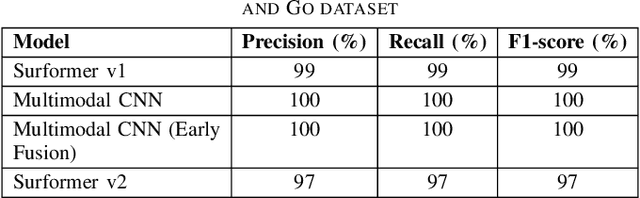
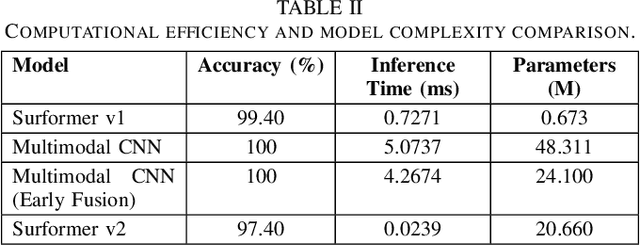
Multimodal surface material classification plays a critical role in advancing tactile perception for robotic manipulation and interaction. In this paper, we present Surformer v2, an enhanced multi-modal classification architecture designed to integrate visual and tactile sensory streams through a late(decision level) fusion mechanism. Building on our earlier Surformer v1 framework [1], which employed handcrafted feature extraction followed by mid-level fusion architecture with multi-head cross-attention layers, Surformer v2 integrates the feature extraction process within the model itself and shifts to late fusion. The vision branch leverages a CNN-based classifier(Efficient V-Net), while the tactile branch employs an encoder-only transformer model, allowing each modality to extract modality-specific features optimized for classification. Rather than merging feature maps, the model performs decision-level fusion by combining the output logits using a learnable weighted sum, enabling adaptive emphasis on each modality depending on data context and training dynamics. We evaluate Surformer v2 on the Touch and Go dataset [2], a multi-modal benchmark comprising surface images and corresponding tactile sensor readings. Our results demonstrate that Surformer v2 performs well, maintaining competitive inference speed, suitable for real-time robotic applications. These findings underscore the effectiveness of decision-level fusion and transformer-based tactile modeling for enhancing surface understanding in multi-modal robotic perception.
Edge-Based Learning for Improved Classification Under Adversarial Noise
Apr 25, 2025Adversarial noise introduces small perturbations in images, misleading deep learning models into misclassification and significantly impacting recognition accuracy. In this study, we analyzed the effects of Fast Gradient Sign Method (FGSM) adversarial noise on image classification and investigated whether training on specific image features can improve robustness. We hypothesize that while adversarial noise perturbs various regions of an image, edges may remain relatively stable and provide essential structural information for classification. To test this, we conducted a series of experiments using brain tumor and COVID datasets. Initially, we trained the models on clean images and then introduced subtle adversarial perturbations, which caused deep learning models to significantly misclassify the images. Retraining on a combination of clean and noisy images led to improved performance. To evaluate the robustness of the edge features, we extracted edges from the original/clean images and trained the models exclusively on edge-based representations. When noise was introduced to the images, the edge-based models demonstrated greater resilience to adversarial attacks compared to those trained on the original or clean images. These results suggest that while adversarial noise is able to exploit complex non-edge regions significantly more than edges, the improvement in the accuracy after retraining is marginally more in the original data as compared to the edges. Thus, leveraging edge-based learning can improve the resilience of deep learning models against adversarial perturbations.
Medical-GAT: Cancer Document Classification Leveraging Graph-Based Residual Network for Scenarios with Limited Data
Oct 19, 2024Accurate classification of cancer-related medical abstracts is crucial for healthcare management and research. However, obtaining large, labeled datasets in the medical domain is challenging due to privacy concerns and the complexity of clinical data. This scarcity of annotated data impedes the development of effective machine learning models for cancer document classification. To address this challenge, we present a curated dataset of 1,874 biomedical abstracts, categorized into thyroid cancer, colon cancer, lung cancer, and generic topics. Our research focuses on leveraging this dataset to improve classification performance, particularly in data-scarce scenarios. We introduce a Residual Graph Attention Network (R-GAT) with multiple graph attention layers that capture the semantic information and structural relationships within cancer-related documents. Our R-GAT model is compared with various techniques, including transformer-based models such as Bidirectional Encoder Representations from Transformers (BERT), RoBERTa, and domain-specific models like BioBERT and Bio+ClinicalBERT. We also evaluated deep learning models (CNNs, LSTMs) and traditional machine learning models (Logistic Regression, SVM). Additionally, we explore ensemble approaches that combine deep learning models to enhance classification. Various feature extraction methods are assessed, including Term Frequency-Inverse Document Frequency (TF-IDF) with unigrams and bigrams, Word2Vec, and tokenizers from BERT and RoBERTa. The R-GAT model outperforms other techniques, achieving precision, recall, and F1 scores of 0.99, 0.97, and 0.98 for thyroid cancer; 0.96, 0.94, and 0.95 for colon cancer; 0.96, 0.99, and 0.97 for lung cancer; and 0.95, 0.96, and 0.95 for generic topics.
Learning Algorithms Made Simple
Oct 11, 2024In this paper, we discuss learning algorithms and their importance in different types of applications which includes training to identify important patterns and features in a straightforward, easy-to-understand manner. We will review the main concepts of artificial intelligence (AI), machine learning (ML), deep learning (DL), and hybrid models. Some important subsets of Machine Learning algorithms such as supervised, unsupervised, and reinforcement learning are also discussed in this paper. These techniques can be used for some important tasks like prediction, classification, and segmentation. Convolutional Neural Networks (CNNs) are used for image and video processing and many more applications. We dive into the architecture of CNNs and how to integrate CNNs with ML algorithms to build hybrid models. This paper explores the vulnerability of learning algorithms to noise, leading to misclassification. We further discuss the integration of learning algorithms with Large Language Models (LLM) to generate coherent responses applicable to many domains such as healthcare, marketing, and finance by learning important patterns from large volumes of data. Furthermore, we discuss the next generation of learning algorithms and how we may have an unified Adaptive and Dynamic Network to perform important tasks. Overall, this article provides brief overview of learning algorithms, exploring their current state, applications and future direction.
From Questions to Insightful Answers: Building an Informed Chatbot for University Resources
May 13, 2024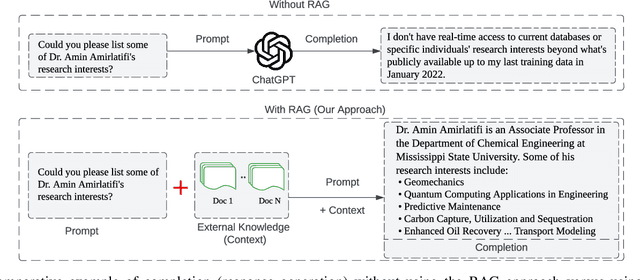
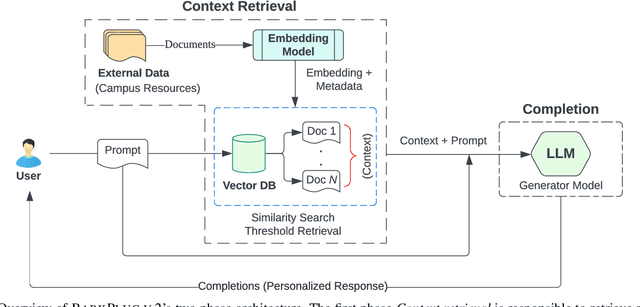
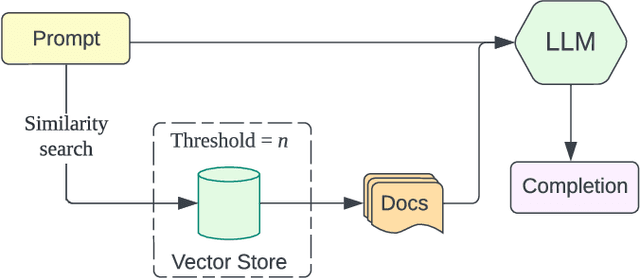
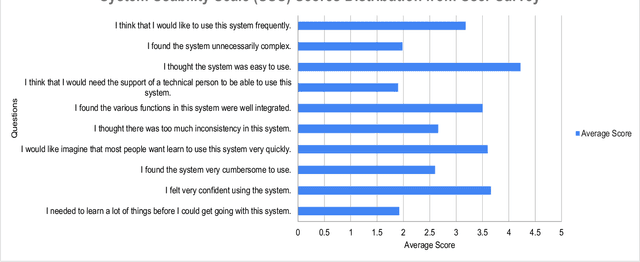
This paper presents BARKPLUG V.2, a Large Language Model (LLM)-based chatbot system built using Retrieval Augmented Generation (RAG) pipelines to enhance the user experience and access to information within academic settings.The objective of BARKPLUG V.2 is to provide information to users about various campus resources, including academic departments, programs, campus facilities, and student resources at a university setting in an interactive fashion. Our system leverages university data as an external data corpus and ingests it into our RAG pipelines for domain-specific question-answering tasks. We evaluate the effectiveness of our system in generating accurate and pertinent responses for Mississippi State University, as a case study, using quantitative measures, employing frameworks such as Retrieval Augmented Generation Assessment(RAGAS). Furthermore, we evaluate the usability of this system via subjective satisfaction surveys using the System Usability Scale (SUS). Our system demonstrates impressive quantitative performance, with a mean RAGAS score of 0.96, and experience, as validated by usability assessments.
MedInsight: A Multi-Source Context Augmentation Framework for Generating Patient-Centric Medical Responses using Large Language Models
Mar 13, 2024



Large Language Models (LLMs) have shown impressive capabilities in generating human-like responses. However, their lack of domain-specific knowledge limits their applicability in healthcare settings, where contextual and comprehensive responses are vital. To address this challenge and enable the generation of patient-centric responses that are contextually relevant and comprehensive, we propose MedInsight:a novel retrieval augmented framework that augments LLM inputs (prompts) with relevant background information from multiple sources. MedInsight extracts pertinent details from the patient's medical record or consultation transcript. It then integrates information from authoritative medical textbooks and curated web resources based on the patient's health history and condition. By constructing an augmented context combining the patient's record with relevant medical knowledge, MedInsight generates enriched, patient-specific responses tailored for healthcare applications such as diagnosis, treatment recommendations, or patient education. Experiments on the MTSamples dataset validate MedInsight's effectiveness in generating contextually appropriate medical responses. Quantitative evaluation using the Ragas metric and TruLens for answer similarity and answer correctness demonstrates the model's efficacy. Furthermore, human evaluation studies involving Subject Matter Expert (SMEs) confirm MedInsight's utility, with moderate inter-rater agreement on the relevance and correctness of the generated responses.
Advancing Generative Model Evaluation: A Novel Algorithm for Realistic Image Synthesis and Comparison in OCR System
Mar 01, 2024This research addresses a critical challenge in the field of generative models, particularly in the generation and evaluation of synthetic images. Given the inherent complexity of generative models and the absence of a standardized procedure for their comparison, our study introduces a pioneering algorithm to objectively assess the realism of synthetic images. This approach significantly enhances the evaluation methodology by refining the Fr\'echet Inception Distance (FID) score, allowing for a more precise and subjective assessment of image quality. Our algorithm is particularly tailored to address the challenges in generating and evaluating realistic images of Arabic handwritten digits, a task that has traditionally been near-impossible due to the subjective nature of realism in image generation. By providing a systematic and objective framework, our method not only enables the comparison of different generative models but also paves the way for improvements in their design and output. This breakthrough in evaluation and comparison is crucial for advancing the field of OCR, especially for scripts that present unique complexities, and sets a new standard in the generation and assessment of high-quality synthetic images.
Patient-Centric Knowledge Graphs: A Survey of Current Methods, Challenges, and Applications
Feb 20, 2024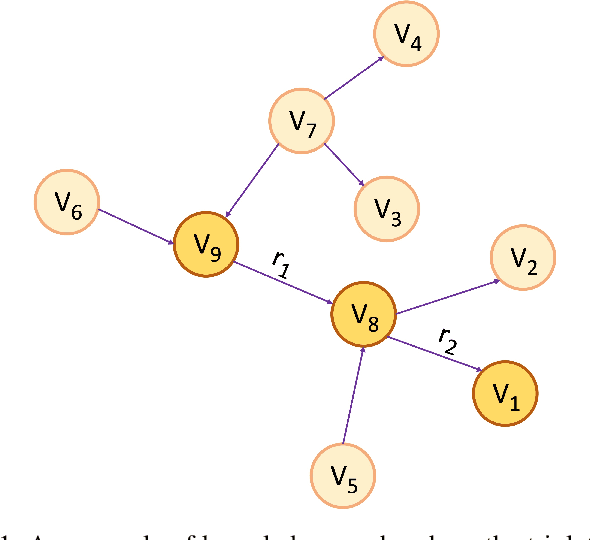
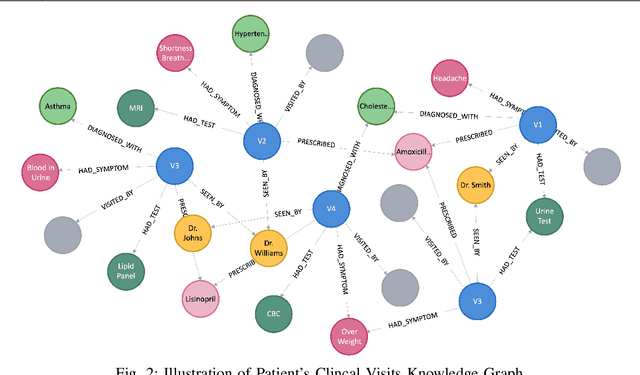
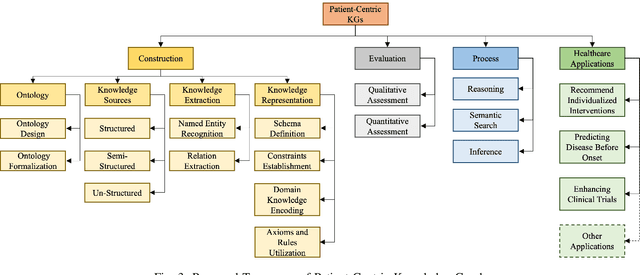
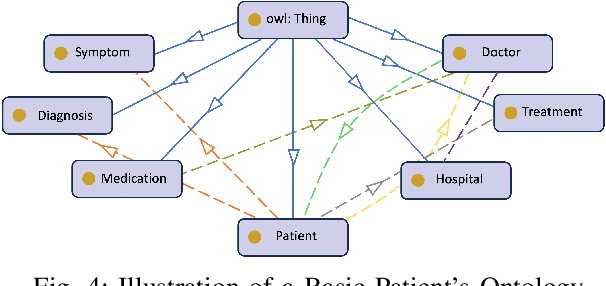
Patient-Centric Knowledge Graphs (PCKGs) represent an important shift in healthcare that focuses on individualized patient care by mapping the patient's health information in a holistic and multi-dimensional way. PCKGs integrate various types of health data to provide healthcare professionals with a comprehensive understanding of a patient's health, enabling more personalized and effective care. This literature review explores the methodologies, challenges, and opportunities associated with PCKGs, focusing on their role in integrating disparate healthcare data and enhancing patient care through a unified health perspective. In addition, this review also discusses the complexities of PCKG development, including ontology design, data integration techniques, knowledge extraction, and structured representation of knowledge. It highlights advanced techniques such as reasoning, semantic search, and inference mechanisms essential in constructing and evaluating PCKGs for actionable healthcare insights. We further explore the practical applications of PCKGs in personalized medicine, emphasizing their significance in improving disease prediction and formulating effective treatment plans. Overall, this review provides a foundational perspective on the current state-of-the-art and best practices of PCKGs, guiding future research and applications in this dynamic field.