 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeedRepFormer: Reparameterizable Vision Transformers for Real-Time Waterhemp Segmentation and Gender Classification
Jan 06, 2026We present WeedRepFormer, a lightweight multi-task Vision Transformer designed for simultaneous waterhemp segmentation and gender classification. Existing agricultural models often struggle to balance the fine-grained feature extraction required for biological attribute classification with the efficiency needed for real-time deployment. To address this, WeedRepFormer systematically integrates structural reparameterization across the entire architecture - comprising a Vision Transformer backbone, a Lite R-ASPP decoder, and a novel reparameterizable classification head - to decouple training-time capacity from inference-time latency. We also introduce a comprehensive waterhemp dataset containing 10,264 annotated frames from 23 plants. On this benchmark, WeedRepFormer achieves 92.18% mIoU for segmentation and 81.91% accuracy for gender classification using only 3.59M parameters and 3.80 GFLOPs. At 108.95 FPS, our model outperforms the state-of-the-art iFormer-T by 4.40% in classification accuracy while maintaining competitive segmentation performance and significantly reducing parameter count by 1.9x.
Advancing Generative Model Evaluation: A Novel Algorithm for Realistic Image Synthesis and Comparison in OCR System
Mar 01, 2024This research addresses a critical challenge in the field of generative models, particularly in the generation and evaluation of synthetic images. Given the inherent complexity of generative models and the absence of a standardized procedure for their comparison, our study introduces a pioneering algorithm to objectively assess the realism of synthetic images. This approach significantly enhances the evaluation methodology by refining the Fr\'echet Inception Distance (FID) score, allowing for a more precise and subjective assessment of image quality. Our algorithm is particularly tailored to address the challenges in generating and evaluating realistic images of Arabic handwritten digits, a task that has traditionally been near-impossible due to the subjective nature of realism in image generation. By providing a systematic and objective framework, our method not only enables the comparison of different generative models but also paves the way for improvements in their design and output. This breakthrough in evaluation and comparison is crucial for advancing the field of OCR, especially for scripts that present unique complexities, and sets a new standard in the generation and assessment of high-quality synthetic images.
FedSiKD: Clients Similarity and Knowledge Distillation: Addressing Non-i.i.d. and Constraints in Federated Learning
Feb 14, 2024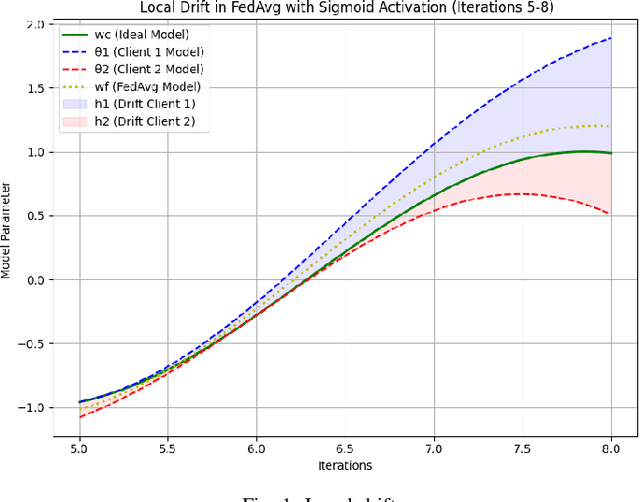



In recent years, federated learning (FL) has emerged as a promising technique for training machine learning models in a decentralized manner while also preserving data privacy. The non-independent and identically distributed (non-i.i.d.) nature of client data, coupled with constraints on client or edge devices, presents significant challenges in FL. Furthermore, learning across a high number of communication rounds can be risky and potentially unsafe for model exploitation. Traditional FL approaches may suffer from these challenges. Therefore, we introduce FedSiKD, which incorporates knowledge distillation (KD) within a similarity-based federated learning framework. As clients join the system, they securely share relevant statistics about their data distribution, promoting intra-cluster homogeneity. This enhances optimization efficiency and accelerates the learning process, effectively transferring knowledge between teacher and student models and addressing device constraints. FedSiKD outperforms state-of-the-art algorithms by achieving higher accuracy, exceeding by 25\% and 18\% for highly skewed data at $\alpha = {0.1,0.5}$ on the HAR and MNIST datasets, respectively. Its faster convergence is illustrated by a 17\% and 20\% increase in accuracy within the first five rounds on the HAR and MNIST datasets, respectively, highlighting its early-stage learning proficiency. Code is publicly available and hosted on GitHub (https://github.com/SimuEnv/FedSiKD)