 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedGraph-VASP: Privacy-Preserving Federated Graph Learning with Post-Quantum Security for Cross-Institutional Anti-Money Laundering
Jan 25, 2026Virtual Asset Service Providers (VASPs) face a fundamental tension between regulatory compliance and user privacy when detecting cross-institutional money laundering. Current approaches require either sharing sensitive transaction data or operating in isolation, leaving critical cross-chain laundering patterns undetected. We present FedGraph-VASP, a privacy-preserving federated graph learning framework that enables collaborative anti-money laundering (AML) without exposing raw user data. Our key contribution is a Boundary Embedding Exchange protocol that shares only compressed, non-invertible graph neural network representations of boundary accounts. These exchanges are secured using post-quantum cryptography, specifically the NIST-standardized Kyber-512 key encapsulation mechanism combined with AES-256-GCM authenticated encryption. Experiments on the Elliptic Bitcoin dataset with realistic Louvain partitioning show that FedGraph-VASP achieves an F1-score of 0.508, outperforming the state-of-the-art generative baseline FedSage+ (F1 = 0.453) by 12.1 percent on binary fraud detection. We further show robustness under low-connectivity settings where generative imputation degrades performance, while approaching centralized performance (F1 = 0.620) in high-connectivity regimes. We additionally evaluate generalization on an Ethereum fraud detection dataset, where FedGraph-VASP (F1 = 0.635) is less effective under sparse cross-silo connectivity, while FedSage+ excels (F1 = 0.855), outperforming even local training (F1 = 0.785). These results highlight a topology-dependent trade-off: embedding exchange benefits connected transaction graphs, whereas generative imputation can dominate in highly modular sparse graphs. A privacy audit shows embeddings are only partially invertible (R^2 = 0.32), limiting exact feature recovery.
FedSiKD: Clients Similarity and Knowledge Distillation: Addressing Non-i.i.d. and Constraints in Federated Learning
Feb 14, 2024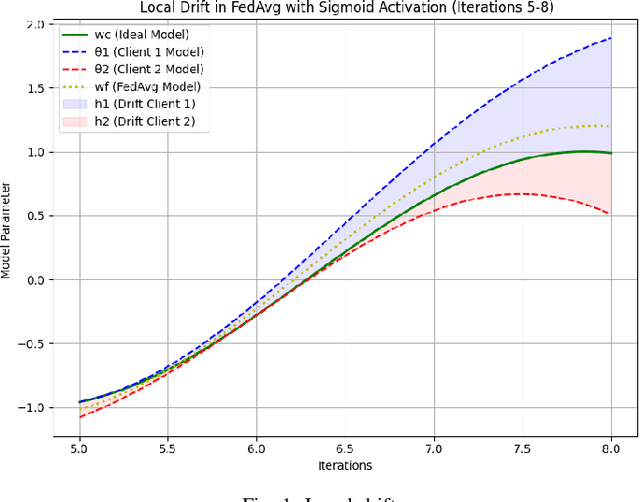



In recent years, federated learning (FL) has emerged as a promising technique for training machine learning models in a decentralized manner while also preserving data privacy. The non-independent and identically distributed (non-i.i.d.) nature of client data, coupled with constraints on client or edge devices, presents significant challenges in FL. Furthermore, learning across a high number of communication rounds can be risky and potentially unsafe for model exploitation. Traditional FL approaches may suffer from these challenges. Therefore, we introduce FedSiKD, which incorporates knowledge distillation (KD) within a similarity-based federated learning framework. As clients join the system, they securely share relevant statistics about their data distribution, promoting intra-cluster homogeneity. This enhances optimization efficiency and accelerates the learning process, effectively transferring knowledge between teacher and student models and addressing device constraints. FedSiKD outperforms state-of-the-art algorithms by achieving higher accuracy, exceeding by 25\% and 18\% for highly skewed data at $\alpha = {0.1,0.5}$ on the HAR and MNIST datasets, respectively. Its faster convergence is illustrated by a 17\% and 20\% increase in accuracy within the first five rounds on the HAR and MNIST datasets, respectively, highlighting its early-stage learning proficiency. Code is publicly available and hosted on GitHub (https://github.com/SimuEnv/FedSiKD)