 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Modeling of Human-Machine Authentication Channels under Partial Information Leakage
May 03, 2026Reliable and secure human-machine communication is fundamental to IoT and cyber-physical ecosystems, where smartphones and wearables commonly serve as authentication controllers. PIN-based authentication can be viewed as a low-bandwidth communication channel through which users transmit numeric credentials under practical constraints. However, conventional evaluations adopt a binary view of security-treating such channels as either fully secure or fully compromised-thereby overlooking the progressive reliability degradation caused by partial information leakage in real-world IoT settings. In this paper, we model the PIN entry process as a stochastic human-IoT communication system and propose a context-conditioned probabilistic inference framework to quantify reliability loss and Quality-of-Service degradation under partial symbol exposure. The proposed approach treats missing digits as latent variables and estimates them using smoothed conditional probability distributions with fallback priors. Unlike traditional sequential models that assume contiguous positional dependencies, the method does not explicitly parameterize hidden-state transitions or emissions; instead, it performs context-driven probabilistic inference to approximate latent dependencies across digit positions. Using over one million real-world four-digit PIN samples, we evaluate single-, double-, and triple-digit leakage scenarios and derive position-dependent reliability metrics. The proposed model achieves up to 55.31% prediction accuracy for one missing digit and 12.12% for three missing digits, while consistently outperforming a standard sequence-model baseline and classical machine learning models in terms of precision, recall, and F1-score. These results formalize PIN entry as a noisy human--IoT communication channel and demonstrate substantial reliability degradation under realistic partial exposure conditions.
Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs
Jul 22, 2019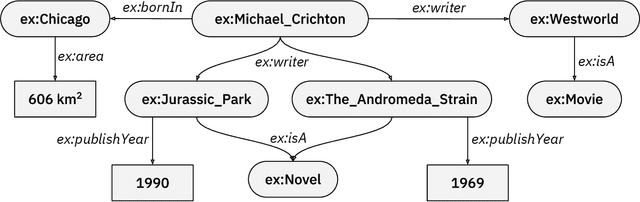
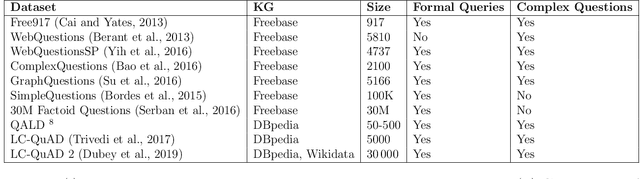
Question answering has emerged as an intuitive way of querying structured data sources, and has attracted significant advancements over the years. In this article, we provide an overview over these recent advancements, focusing on neural network based question answering systems over knowledge graphs. We introduce readers to the challenges in the tasks, current paradigms of approaches, discuss notable advancements, and outline the emerging trends in the field. Through this article, we aim to provide newcomers to the field with a suitable entry point, and ease their process of making informed decisions while creating their own QA system.
Translating Natural Language to SQL using Pointer-Generator Networks and How Decoding Order Matters
Nov 13, 2018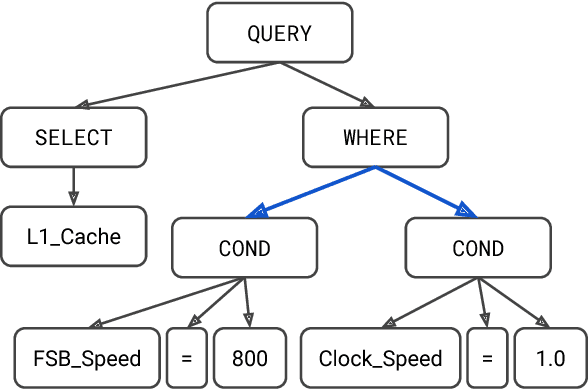
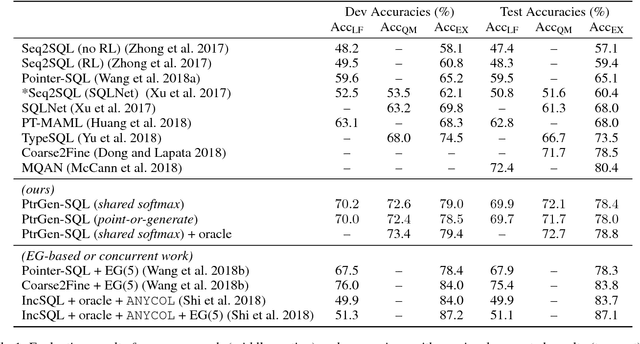
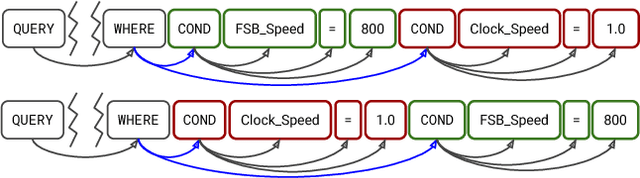
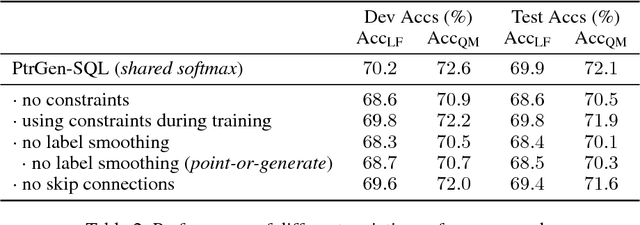
Translating natural language to SQL queries for table-based question answering is a challenging problem and has received significant attention from the research community. In this work, we extend a pointer-generator and investigate the order-matters problem in semantic parsing for SQL. Even though our model is a straightforward extension of a general-purpose pointer-generator, it outperforms early works for WikiSQL and remains competitive to concurrently introduced, more complex models. Moreover, we provide a deeper investigation of the potential order-matters problem that could arise due to having multiple correct decoding paths, and investigate the use of REINFORCE as well as a dynamic oracle in this context.
Learning to Rank Query Graphs for Complex Question Answering over Knowledge Graphs
Nov 02, 2018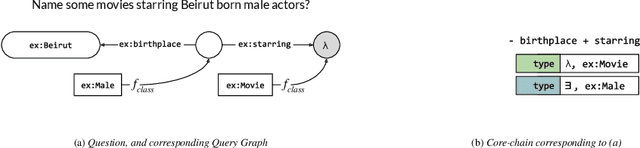
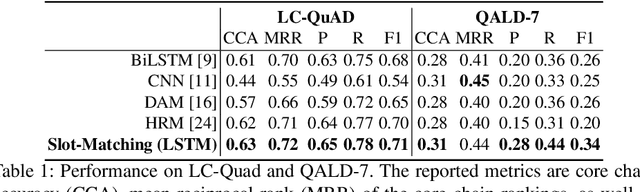
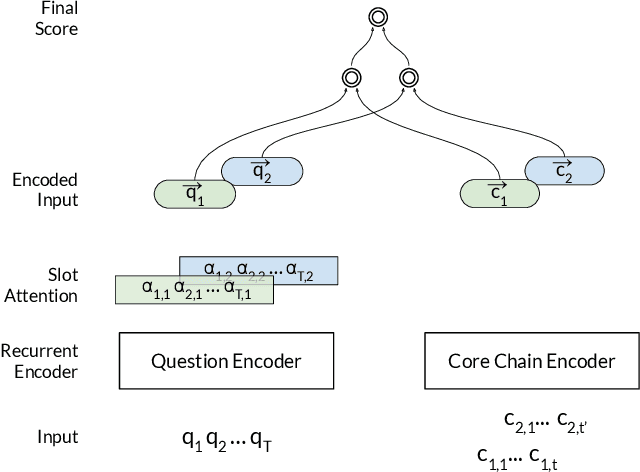
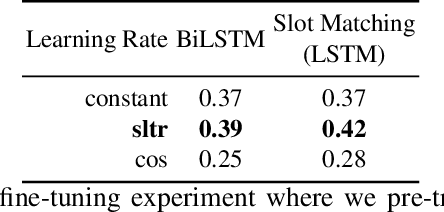
In this paper, we conduct an empirical investigation of neural query graph ranking approaches for the task of complex question answering over knowledge graphs. We experiment with six different ranking models and propose a novel self-attention based slot matching model which exploits the inherent structure of query graphs, our logical form of choice. Our proposed model generally outperforms the other models on two QA datasets over the DBpedia knowledge graph, evaluated in different settings. In addition, we show that transfer learning from the larger of those QA datasets to the smaller dataset yields substantial improvements, effectively offsetting the general lack of training data.