 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposeRL: Learning to Ask Useful, Informative, and Diverse Questions for Semi-Supervised, Traceable Claim Verification
May 27, 2026Claim verification splits between end-to-end classifiers that are accurate but yields no inspectable traces, and decomposition-based methods produce inspectable traces but lag performance on benchmark datasets. We propose DecomposeRL an accurate claim-verifier that produce inspectable traces. DecomposeRL frames decomposition as an RL policy trained with GRPO and a multi-faceted reward ensemble, enabling both fully supervised and semi-supervised learning from unlabeled claims. DecomposeRL addresses the prohibitive training cost of GRPO with a data-curation funnel that distills 115K fact-verification claims into a compact, learning-signal-dense subset of 5K claims. We show that a DecomposeRL-7B policy trained with full supervision on only ~5K curated claims achieves 86.3 in-domain and 69.8 out-of-domain balanced accuracy across 11 claim-verification benchmarks containing biomedical, political, scientific, and general-domain claims. Despite being 4x smaller, it matches 32B baselines and GPT-4.1-mini, and it further outperforms baselines in a semi-supervised setting with only 10% labeled claims data. Code, data, and models are available at https://dipta007.github.io/DecomposeRL
IMRNNs: An Efficient Method for Interpretable Dense Retrieval via Embedding Modulation
Jan 27, 2026Interpretability in black-box dense retrievers remains a central challenge in Retrieval-Augmented Generation (RAG). Understanding how queries and documents semantically interact is critical for diagnosing retrieval behavior and improving model design. However, existing dense retrievers rely on static embeddings for both queries and documents, which obscures this bidirectional relationship. Post-hoc approaches such as re-rankers are computationally expensive, add inference latency, and still fail to reveal the underlying semantic alignment. To address these limitations, we propose Interpretable Modular Retrieval Neural Networks (IMRNNs), a lightweight framework that augments any dense retriever with dynamic, bidirectional modulation at inference time. IMRNNs employ two independent adapters: one conditions document embeddings on the current query, while the other refines the query embedding using corpus-level feedback from initially retrieved documents. This iterative modulation process enables the model to adapt representations dynamically and expose interpretable semantic dependencies between queries and documents. Empirically, IMRNNs not only enhance interpretability but also improve retrieval effectiveness. Across seven benchmark datasets, applying our method to standard dense retrievers yields average gains of +6.35% nDCG, +7.14% recall, and +7.04% MRR over state-of-the-art baselines. These results demonstrate that incorporating interpretability-driven modulation can both explain and enhance retrieval in RAG systems.
Named Entity Recognition for Nepali Language
Aug 16, 2019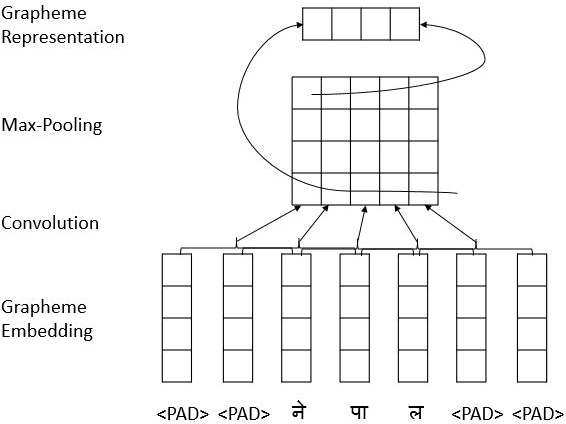
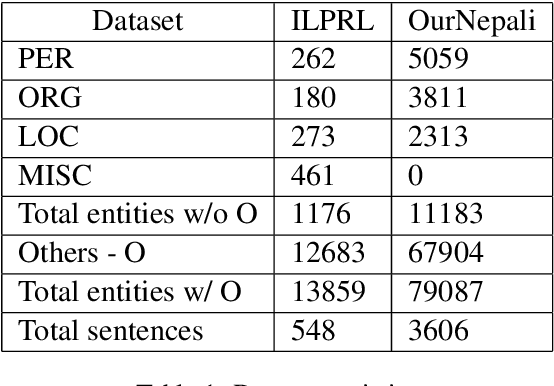
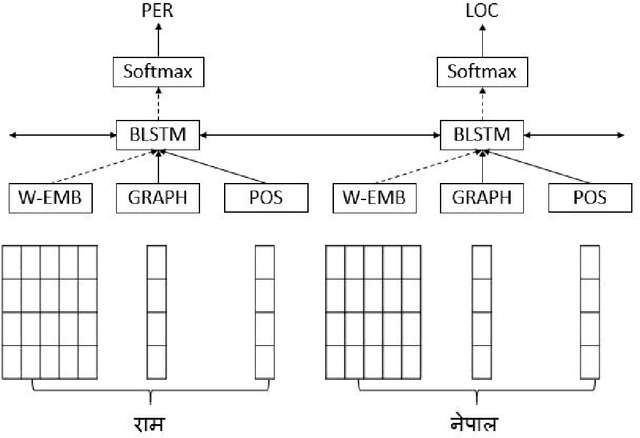
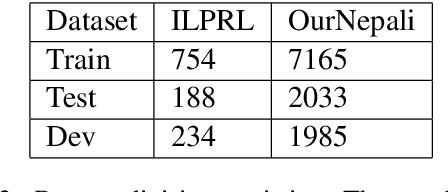
Named Entity Recognition have been studied for different languages like English, German, Spanish and many others but no study have focused on Nepali language. In this paper we propose a neural based Nepali NER using latest state-of-the-art architecture based on grapheme-level which doesn't require any hand-crafted features and no data pre-processing. Our novel neural based model gained relative improvement of 33% to 50% compared to feature based SVM model and up to 10% improvement over state-of-the-art neural based model developed for languages beside Nepali.
Knowledge Graph Fact Prediction via Knowledge-Enriched Tensor Factorization
Feb 08, 2019
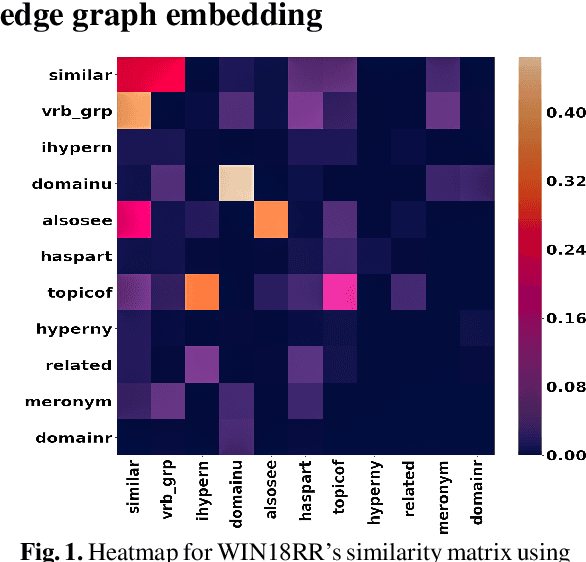
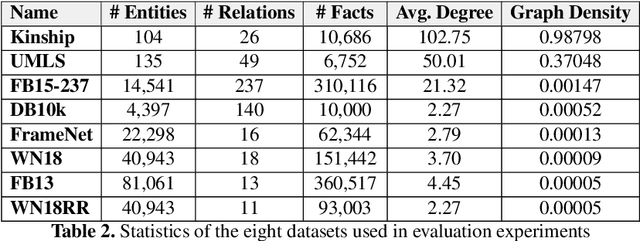
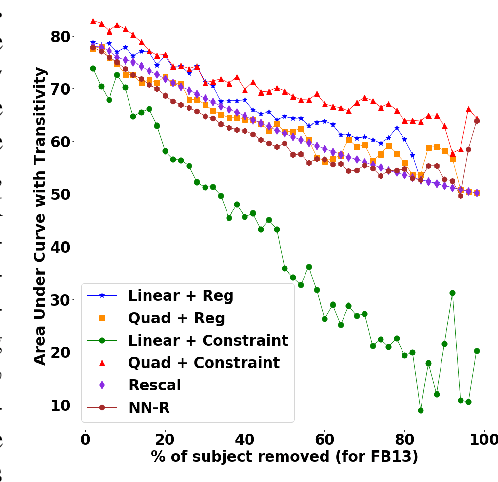
We present a family of novel methods for embedding knowledge graphs into real-valued tensors. These tensor-based embeddings capture the ordered relations that are typical in the knowledge graphs represented by semantic web languages like RDF. Unlike many previous models, our methods can easily use prior background knowledge provided by users or extracted automatically from existing knowledge graphs. In addition to providing more robust methods for knowledge graph embedding, we provide a provably-convergent, linear tensor factorization algorithm. We demonstrate the efficacy of our models for the task of predicting new facts across eight different knowledge graphs, achieving between 5% and 50% relative improvement over existing state-of-the-art knowledge graph embedding techniques. Our empirical evaluation shows that all of the tensor decomposition models perform well when the average degree of an entity in a graph is high, with constraint-based models doing better on graphs with a small number of highly similar relations and regularization-based models dominating for graphs with relations of varying degrees of similarity.
SURFACE: Semantically Rich Fact Validation with Explanations
Oct 31, 2018
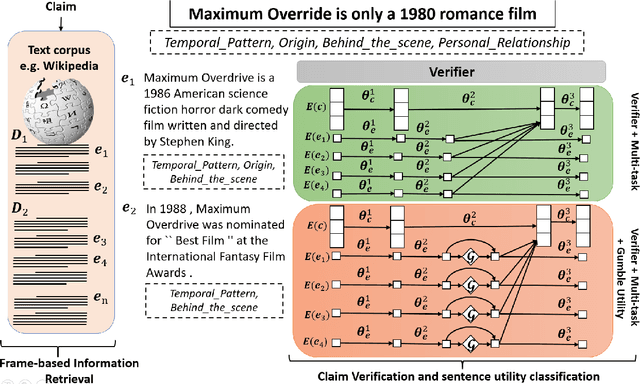
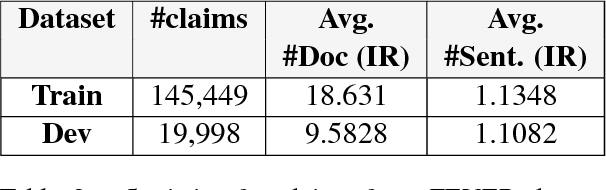
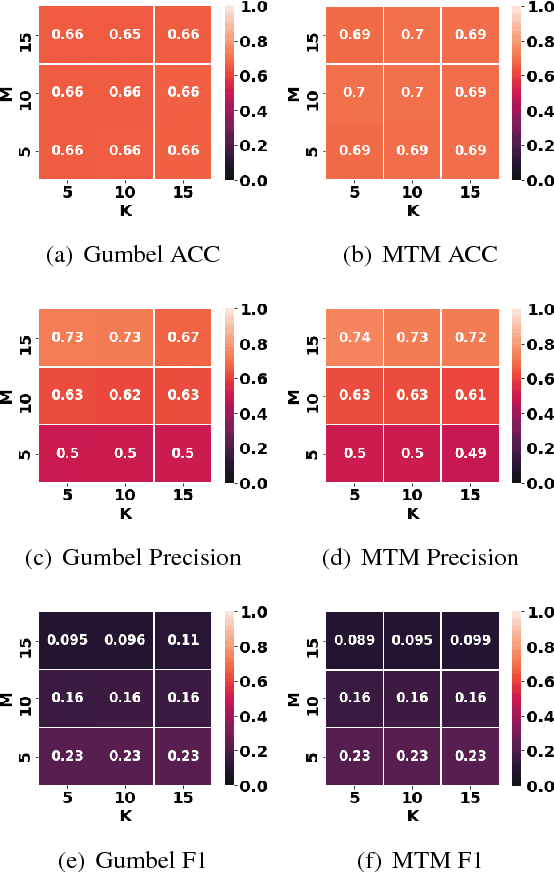
Judging the veracity of a sentence making one or more claims is an important and challenging problem with many dimensions. The recent FEVER task asked participants to classify input sentences as either SUPPORTED, REFUTED or NotEnoughInfo using Wikipedia as a source of true facts. SURFACE does this task and explains its decision through a selection of sentences from the trusted source. Our multi-task neural approach uses semantic lexical frames from FrameNet to jointly (i) find relevant evidential sentences in the trusted source and (ii) use them to classify the input sentence's veracity. An evaluation of our efficient three-parameter model on the FEVER dataset showed an improvement of 90% over the state-of-the-art baseline on retrieving relevant sentences and a 70% relative improvement in classification.
KGCleaner : Identifying and Correcting Errors Produced by Information Extraction Systems
Aug 15, 2018
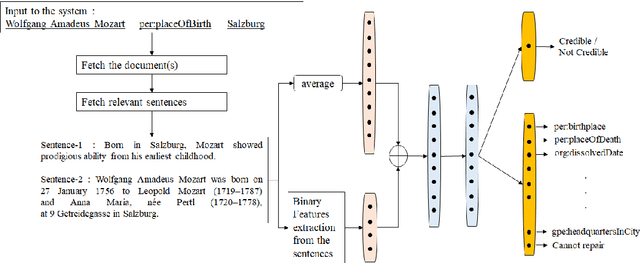

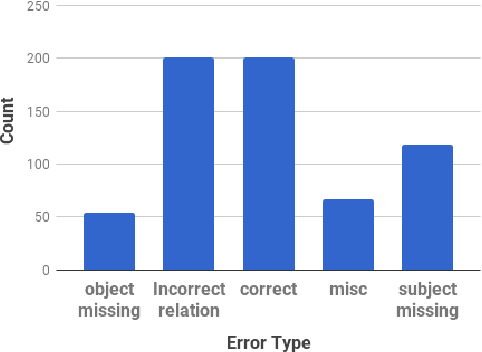
KGCleaner is a framework to identify and correct errors in data produced and delivered by an information extraction system. These tasks have been understudied and KGCleaner is the first to address both. We introduce a multi-task model that jointly learns to predict if an extracted relation is credible and repair it if not. We evaluate our approach and other models as instance of our framework on two collections: a Wikidata corpus of nearly 700K facts and 5M fact-relevant sentences and a collection of 30K facts from the 2015 TAC Knowledge Base Population task. For credibility classification, parameter efficient simple shallow neural network can achieve an absolute performance gain of 30 $F_1$ points on Wikidata and comparable performance on TAC. For the repair task, significant performance (at more than twice) gain can be obtained depending on the nature of the dataset and the models.
Formal Ontology Learning from English IS-A Sentences
Feb 11, 2018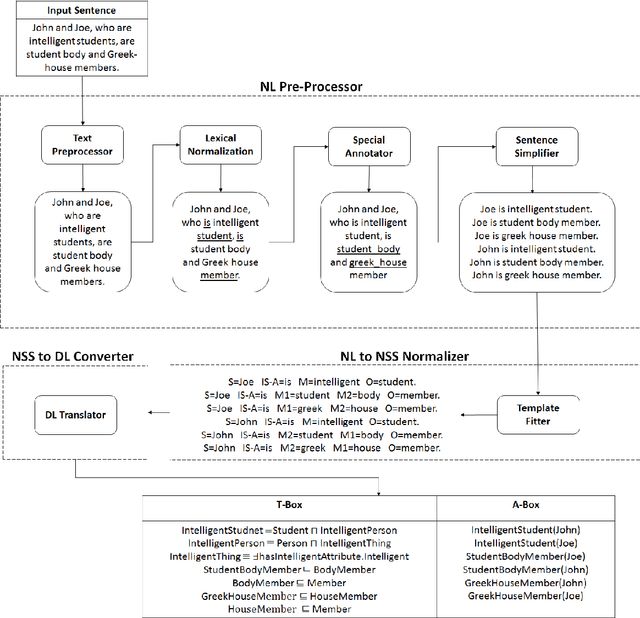
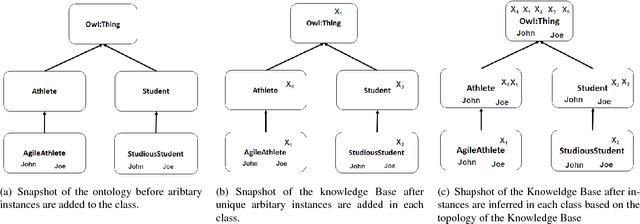

Ontology learning (OL) is the process of automatically generating an ontological knowledge base from a plain text document. In this paper, we propose a new ontology learning approach and tool, called DLOL, which generates a knowledge base in the description logic (DL) SHOQ(D) from a collection of factual non-negative IS-A sentences in English. We provide extensive experimental results on the accuracy of DLOL, giving experimental comparisons to three state-of-the-art existing OL tools, namely Text2Onto, FRED, and LExO. Here, we use the standard OL accuracy measure, called lexical accuracy, and a novel OL accuracy measure, called instance-based inference model. In our experimental results, DLOL turns out to be about 21% and 46%, respectively, better than the best of the other three approaches.
Formal Ontology Learning on Factual IS-A Corpus in English using Description Logics
Mar 08, 2016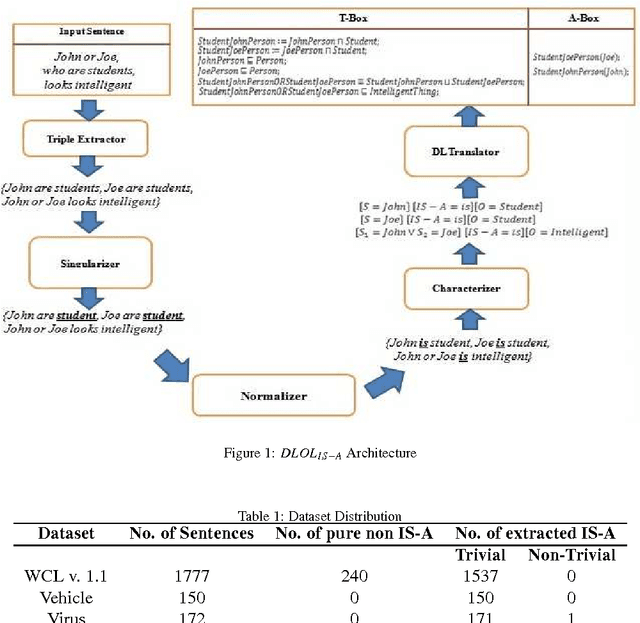

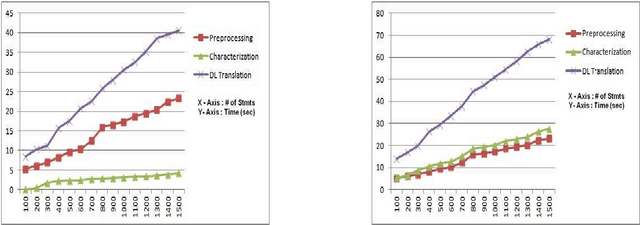
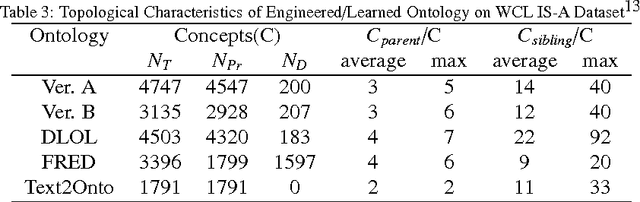
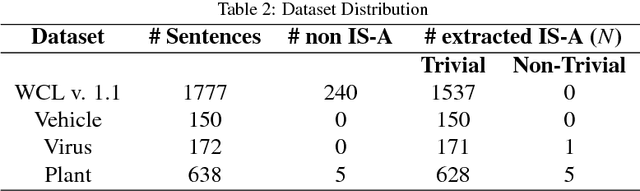
Ontology Learning (OL) is the computational task of generating a knowledge base in the form of an ontology given an unstructured corpus whose content is in natural language (NL). Several works can be found in this area most of which are limited to statistical and lexico-syntactic pattern matching based techniques Light-Weight OL. These techniques do not lead to very accurate learning mostly because of several linguistic nuances in NL. Formal OL is an alternative (less explored) methodology were deep linguistics analysis is made using theory and tools found in computational linguistics to generate formal axioms and definitions instead simply inducing a taxonomy. In this paper we propose "Description Logic (DL)" based formal OL framework for learning factual IS-A type sentences in English. We claim that semantic construction of IS-A sentences is non trivial. Hence, we also claim that such sentences requires special studies in the context of OL before any truly formal OL can be proposed. We introduce a learner tool, called DLOL_IS-A, that generated such ontologies in the owl format. We have adopted "Gold Standard" based OL evaluation on IS-A rich WCL v.1.1 dataset and our own Community representative IS-A dataset. We observed significant improvement of DLOL_IS-A when compared to the light-weight OL tool Text2Onto and formal OL tool FRED.
Description Logics based Formalization of Wh-Queries
Dec 25, 2013


The problem of Natural Language Query Formalization (NLQF) is to translate a given user query in natural language (NL) into a formal language so that the semantic interpretation has equivalence with the NL interpretation. Formalization of NL queries enables logic based reasoning during information retrieval, database query, question-answering, etc. Formalization also helps in Web query normalization and indexing, query intent analysis, etc. In this paper we are proposing a Description Logics based formal methodology for wh-query intent (also called desire) identification and corresponding formal translation. We evaluated the scalability of our proposed formalism using Microsoft Encarta 98 query dataset and OWL-S TC v.4.0 dataset.
DLOLIS-A: Description Logic based Text Ontology Learning
Mar 24, 2013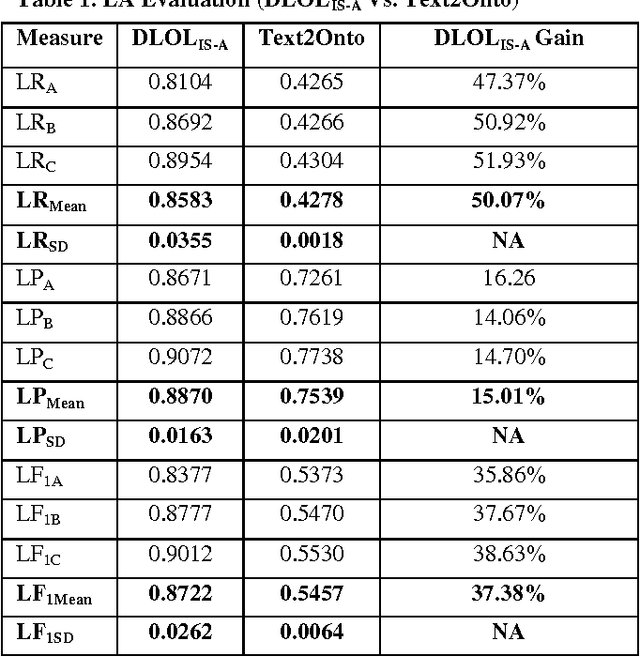

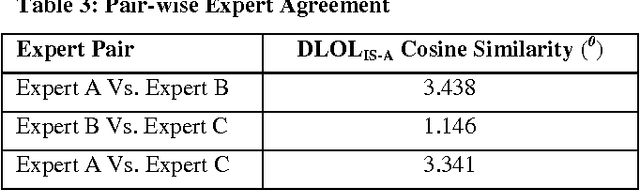
Ontology Learning has been the subject of intensive study for the past decade. Researchers in this field have been motivated by the possibility of automatically building a knowledge base on top of text documents so as to support reasoning based knowledge extraction. While most works in this field have been primarily statistical (known as light-weight Ontology Learning) not much attempt has been made in axiomatic Ontology Learning (called heavy-weight Ontology Learning) from Natural Language text documents. Heavy-weight Ontology Learning supports more precise formal logic-based reasoning when compared to statistical ontology learning. In this paper we have proposed a sound Ontology Learning tool DLOL_(IS-A) that maps English language IS-A sentences into their equivalent Description Logic (DL) expressions in order to automatically generate a consistent pair of T-box and A-box thereby forming both regular (definitional form) and generalized (axiomatic form) DL ontology. The current scope of the paper is strictly limited to IS-A sentences that exclude the possible structures of: (i) implicative IS-A sentences, and (ii) "Wh" IS-A questions. Other linguistic nuances that arise out of pragmatics and epistemic of IS-A sentences are beyond the scope of this present work. We have adopted Gold Standard based Ontology Learning evaluation on chosen IS-A rich Wikipedia documents.