 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription Logics based Formalization of Wh-Queries
Dec 25, 2013


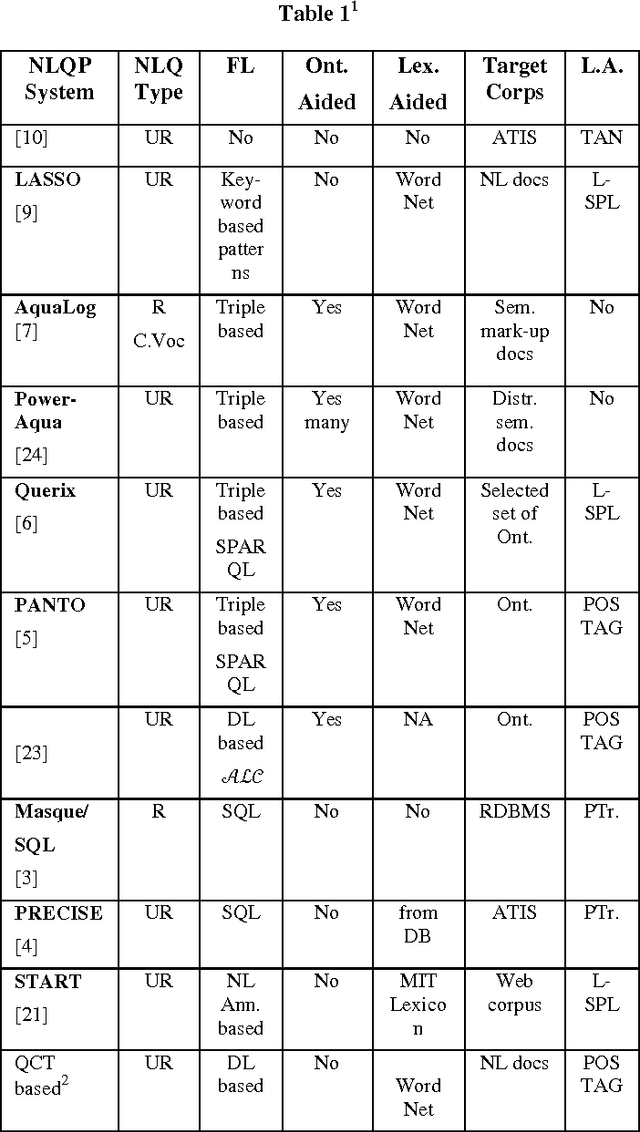
The problem of Natural Language Query Formalization (NLQF) is to translate a given user query in natural language (NL) into a formal language so that the semantic interpretation has equivalence with the NL interpretation. Formalization of NL queries enables logic based reasoning during information retrieval, database query, question-answering, etc. Formalization also helps in Web query normalization and indexing, query intent analysis, etc. In this paper we are proposing a Description Logics based formal methodology for wh-query intent (also called desire) identification and corresponding formal translation. We evaluated the scalability of our proposed formalism using Microsoft Encarta 98 query dataset and OWL-S TC v.4.0 dataset.
DLOLIS-A: Description Logic based Text Ontology Learning
Mar 24, 2013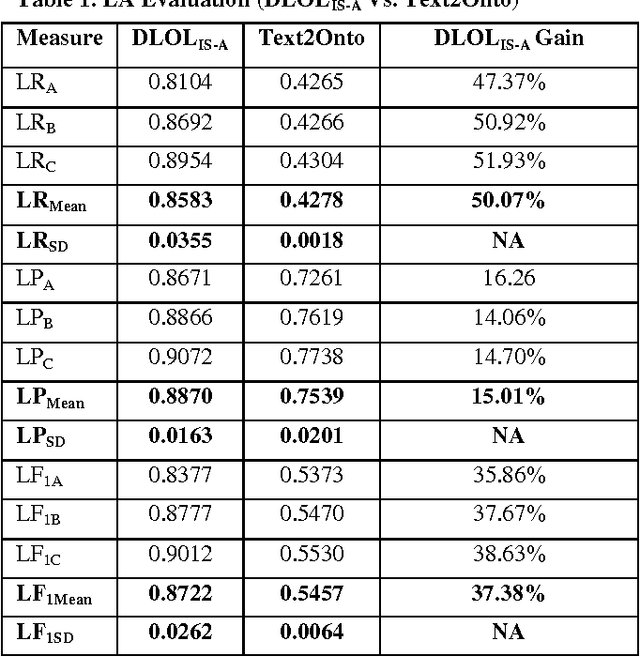

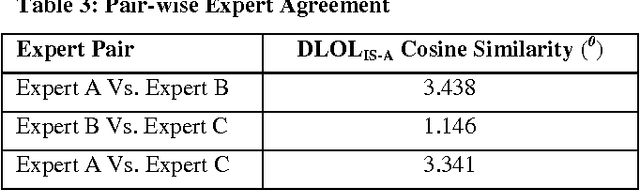
Ontology Learning has been the subject of intensive study for the past decade. Researchers in this field have been motivated by the possibility of automatically building a knowledge base on top of text documents so as to support reasoning based knowledge extraction. While most works in this field have been primarily statistical (known as light-weight Ontology Learning) not much attempt has been made in axiomatic Ontology Learning (called heavy-weight Ontology Learning) from Natural Language text documents. Heavy-weight Ontology Learning supports more precise formal logic-based reasoning when compared to statistical ontology learning. In this paper we have proposed a sound Ontology Learning tool DLOL_(IS-A) that maps English language IS-A sentences into their equivalent Description Logic (DL) expressions in order to automatically generate a consistent pair of T-box and A-box thereby forming both regular (definitional form) and generalized (axiomatic form) DL ontology. The current scope of the paper is strictly limited to IS-A sentences that exclude the possible structures of: (i) implicative IS-A sentences, and (ii) "Wh" IS-A questions. Other linguistic nuances that arise out of pragmatics and epistemic of IS-A sentences are beyond the scope of this present work. We have adopted Gold Standard based Ontology Learning evaluation on chosen IS-A rich Wikipedia documents.