 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural ATTF: A Scalable Solution to Lifelong Multi-Agent Path Planning
Apr 21, 2025



Multi-Agent Pickup and Delivery (MAPD) is a fundamental problem in robotics, particularly in applications such as warehouse automation and logistics. Existing solutions often face challenges in scalability, adaptability, and efficiency, limiting their applicability in dynamic environments with real-time planning requirements. This paper presents Neural ATTF (Adaptive Task Token Framework), a new algorithm that combines a Priority Guided Task Matching (PGTM) Module with Neural STA* (Space-Time A*), a data-driven path planning method. Neural STA* enhances path planning by enabling rapid exploration of the search space through guided learned heuristics and ensures collision avoidance under dynamic constraints. PGTM prioritizes delayed agents and dynamically assigns tasks by prioritizing agents nearest to these tasks, optimizing both continuity and system throughput. Experimental evaluations against state-of-the-art MAPD algorithms, including TPTS, CENTRAL, RMCA, LNS-PBS, and LNS-wPBS, demonstrate the superior scalability, solution quality, and computational efficiency of Neural ATTF. These results highlight the framework's potential for addressing the critical demands of complex, real-world multi-agent systems operating in high-demand, unpredictable settings.
Enhancing Grammatical Error Detection using BERT with Cleaned Lang-8 Dataset
Nov 23, 2024This paper presents an improved LLM based model for Grammatical Error Detection (GED), which is a very challenging and equally important problem for many applications. The traditional approach to GED involved hand-designed features, but recently, Neural Networks (NN) have automated the discovery of these features, improving performance in GED. Traditional rule-based systems have an F1 score of 0.50-0.60 and earlier machine learning models give an F1 score of 0.65-0.75, including decision trees and simple neural networks. Previous deep learning models, for example, Bi-LSTM, have reported F1 scores within the range from 0.80 to 0.90. In our study, we have fine-tuned various transformer models using the Lang8 dataset rigorously cleaned by us. In our experiments, the BERT-base-uncased model gave an impressive performance with an F1 score of 0.91 and accuracy of 98.49% on training data and 90.53% on testing data, also showcasing the importance of data cleaning. Increasing model size using BERT-large-uncased or RoBERTa-large did not give any noticeable improvements in performance or advantage for this task, underscoring that larger models are not always better. Our results clearly show how far rigorous data cleaning and simple transformer-based models can go toward significantly improving the quality of GED.
BioNeMo Framework: a modular, high-performance library for AI model development in drug discovery
Nov 15, 2024



Artificial Intelligence models encoding biology and chemistry are opening new routes to high-throughput and high-quality in-silico drug development. However, their training increasingly relies on computational scale, with recent protein language models (pLM) training on hundreds of graphical processing units (GPUs). We introduce the BioNeMo Framework to facilitate the training of computational biology and chemistry AI models across hundreds of GPUs. Its modular design allows the integration of individual components, such as data loaders, into existing workflows and is open to community contributions. We detail technical features of the BioNeMo Framework through use cases such as pLM pre-training and fine-tuning. On 256 NVIDIA A100s, BioNeMo Framework trains a three billion parameter BERT-based pLM on over one trillion tokens in 4.2 days. The BioNeMo Framework is open-source and free for everyone to use.
Malaria detection from RBC images using shallow Convolutional Neural Networks
Oct 22, 2020
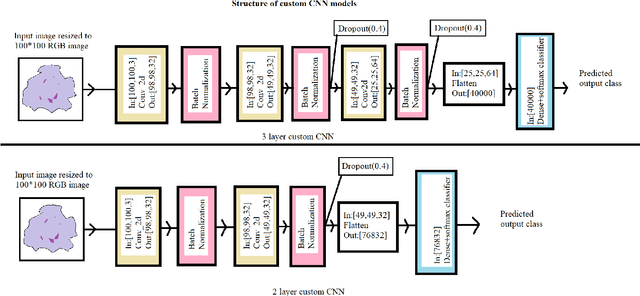
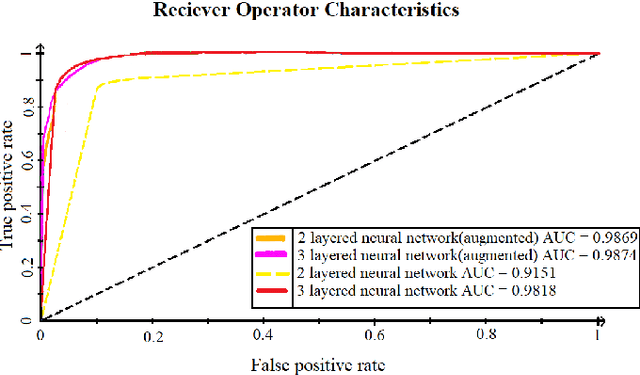
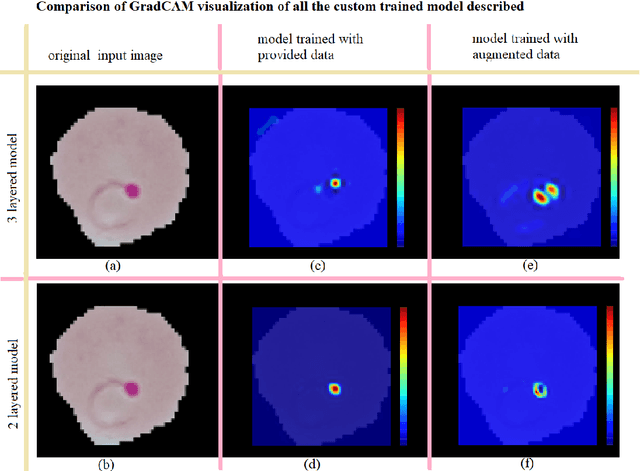
The advent of Deep Learning models like VGG-16 and Resnet-50 has considerably revolutionized the field of image classification, and by using these Convolutional Neural Networks (CNN) architectures, one can get a high classification accuracy on a wide variety of image datasets. However, these Deep Learning models have a very high computational complexity and so incur a high computational cost of running these algorithms as well as make it hard to interpret the results. In this paper, we present a shallow CNN architecture which gives the same classification accuracy as the VGG-16 and Resnet-50 models for thin blood smear RBC slide images for detection of malaria, while decreasing the computational run time by an order of magnitude. This can offer a significant advantage for commercial deployment of these algorithms, especially in poorer countries in Africa and some parts of the Indian subcontinent, where the menace of malaria is quite severe.
Open-endedness in AI systems, cellular evolution and intellectual discussions
Dec 28, 2018One of the biggest challenges that artificial intelligence (AI) research is facing in recent times is to develop algorithms and systems that are not only good at performing a specific intelligent task but also good at learning a very diverse of skills somewhat like humans do. In other words, the goal is to be able to mimic biological evolution which has produced all the living species on this planet and which seems to have no end to its creativity. The process of intellectual discussions is also somewhat similar to biological evolution in this regard and is responsible for many of the innovative discoveries and inventions that scientists and engineers have made in the past. In this paper, we present an information theoretic analogy between the process of discussions and the molecular dynamics within a cell, showing that there is a common process of information exchange at the heart of these two seemingly different processes, which can perhaps help us in building AI systems capable of open-ended innovation. We also discuss the role of consciousness in this process and present a framework for the development of open-ended AI systems.
Formal Ontology Learning on Factual IS-A Corpus in English using Description Logics
Mar 08, 2016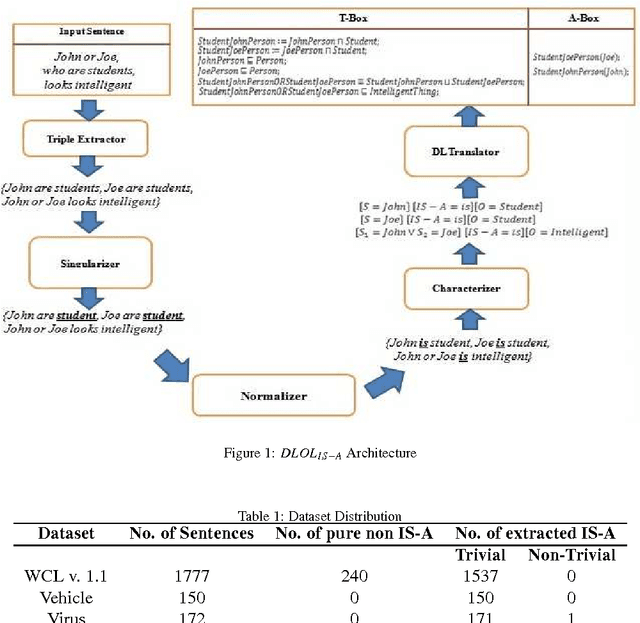

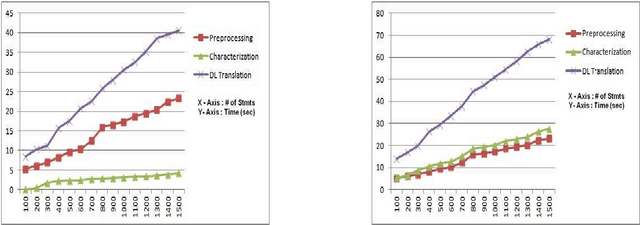
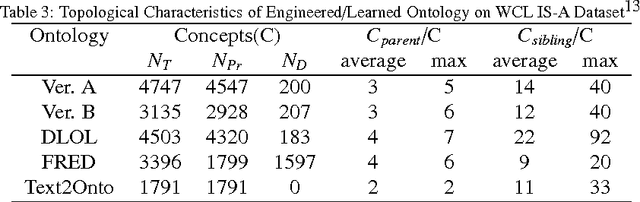
Ontology Learning (OL) is the computational task of generating a knowledge base in the form of an ontology given an unstructured corpus whose content is in natural language (NL). Several works can be found in this area most of which are limited to statistical and lexico-syntactic pattern matching based techniques Light-Weight OL. These techniques do not lead to very accurate learning mostly because of several linguistic nuances in NL. Formal OL is an alternative (less explored) methodology were deep linguistics analysis is made using theory and tools found in computational linguistics to generate formal axioms and definitions instead simply inducing a taxonomy. In this paper we propose "Description Logic (DL)" based formal OL framework for learning factual IS-A type sentences in English. We claim that semantic construction of IS-A sentences is non trivial. Hence, we also claim that such sentences requires special studies in the context of OL before any truly formal OL can be proposed. We introduce a learner tool, called DLOL_IS-A, that generated such ontologies in the owl format. We have adopted "Gold Standard" based OL evaluation on IS-A rich WCL v.1.1 dataset and our own Community representative IS-A dataset. We observed significant improvement of DLOL_IS-A when compared to the light-weight OL tool Text2Onto and formal OL tool FRED.
Description Logics based Formalization of Wh-Queries
Dec 25, 2013


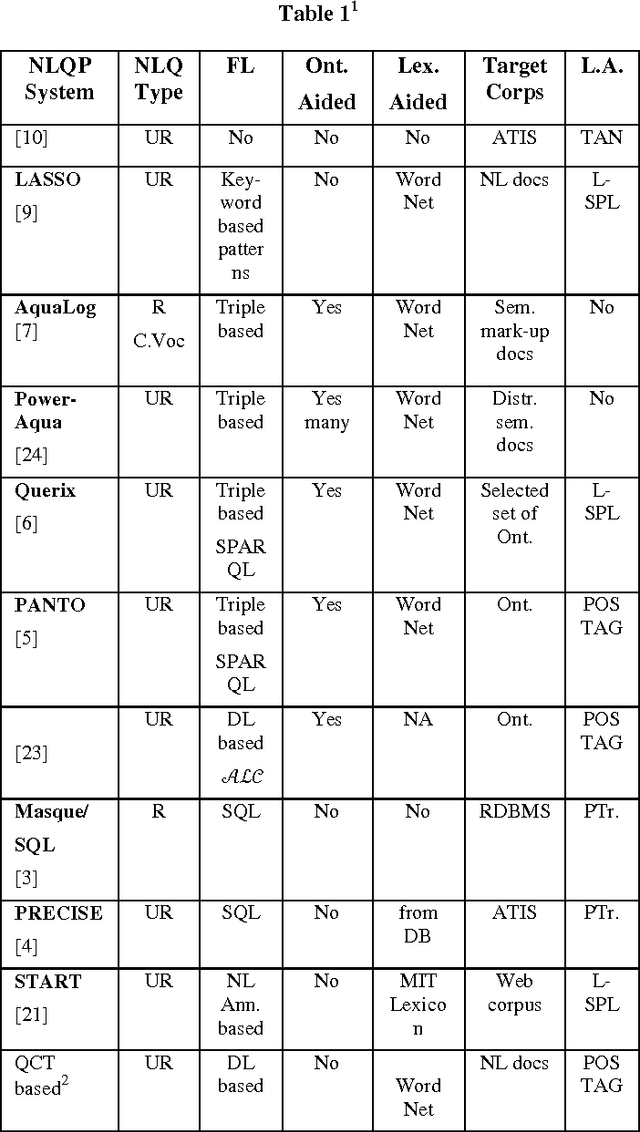
The problem of Natural Language Query Formalization (NLQF) is to translate a given user query in natural language (NL) into a formal language so that the semantic interpretation has equivalence with the NL interpretation. Formalization of NL queries enables logic based reasoning during information retrieval, database query, question-answering, etc. Formalization also helps in Web query normalization and indexing, query intent analysis, etc. In this paper we are proposing a Description Logics based formal methodology for wh-query intent (also called desire) identification and corresponding formal translation. We evaluated the scalability of our proposed formalism using Microsoft Encarta 98 query dataset and OWL-S TC v.4.0 dataset.
DLOLIS-A: Description Logic based Text Ontology Learning
Mar 24, 2013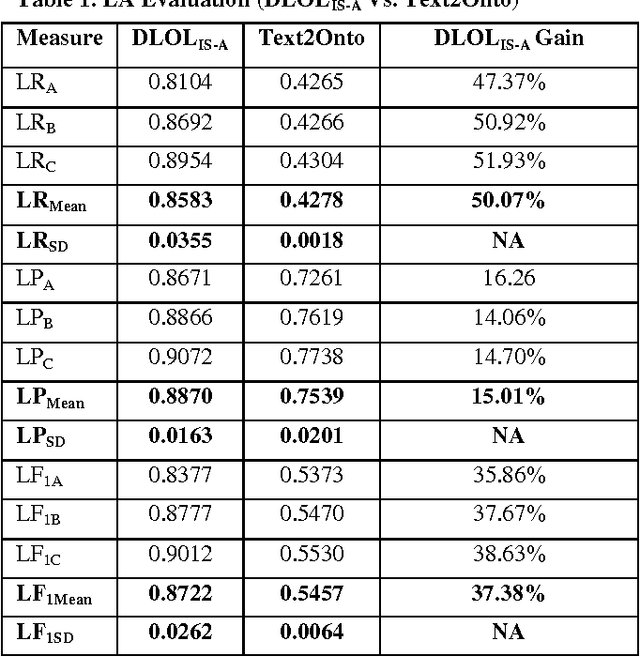

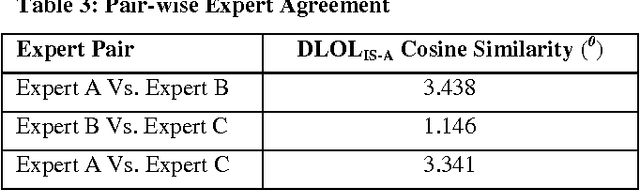
Ontology Learning has been the subject of intensive study for the past decade. Researchers in this field have been motivated by the possibility of automatically building a knowledge base on top of text documents so as to support reasoning based knowledge extraction. While most works in this field have been primarily statistical (known as light-weight Ontology Learning) not much attempt has been made in axiomatic Ontology Learning (called heavy-weight Ontology Learning) from Natural Language text documents. Heavy-weight Ontology Learning supports more precise formal logic-based reasoning when compared to statistical ontology learning. In this paper we have proposed a sound Ontology Learning tool DLOL_(IS-A) that maps English language IS-A sentences into their equivalent Description Logic (DL) expressions in order to automatically generate a consistent pair of T-box and A-box thereby forming both regular (definitional form) and generalized (axiomatic form) DL ontology. The current scope of the paper is strictly limited to IS-A sentences that exclude the possible structures of: (i) implicative IS-A sentences, and (ii) "Wh" IS-A questions. Other linguistic nuances that arise out of pragmatics and epistemic of IS-A sentences are beyond the scope of this present work. We have adopted Gold Standard based Ontology Learning evaluation on chosen IS-A rich Wikipedia documents.