 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerSEval: Assessing Personalization in Text Summarizers
Jun 29, 2024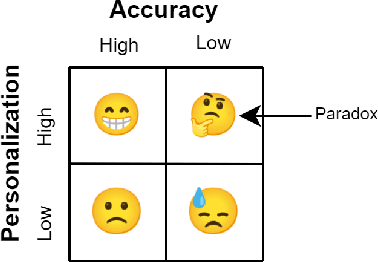
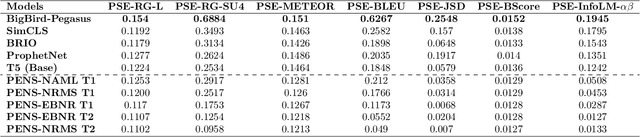
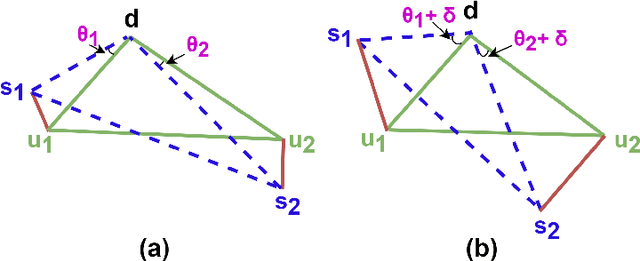

Personalized summarization models cater to individuals' subjective understanding of saliency, as represented by their reading history and current topics of attention. Existing personalized text summarizers are primarily evaluated based on accuracy measures such as BLEU, ROUGE, and METEOR. However, a recent study argued that accuracy measures are inadequate for evaluating the degree of personalization of these models and proposed EGISES, the first metric to evaluate personalized text summaries. It was suggested that accuracy is a separate aspect and should be evaluated standalone. In this paper, we challenge the necessity of an accuracy leaderboard, suggesting that relying on accuracy-based aggregated results might lead to misleading conclusions. To support this, we delve deeper into EGISES, demonstrating both theoretically and empirically that it measures the degree of responsiveness, a necessary but not sufficient condition for degree-of-personalization. We subsequently propose PerSEval, a novel measure that satisfies the required sufficiency condition. Based on the benchmarking of ten SOTA summarization models on the PENS dataset, we empirically establish that -- (i) PerSEval is reliable w.r.t human-judgment correlation (Pearson's r = 0.73; Spearman's $\rho$ = 0.62; Kendall's $\tau$ = 0.42), (ii) PerSEval has high rank-stability, (iii) PerSEval as a rank-measure is not entailed by EGISES-based ranking, and (iv) PerSEval can be a standalone rank-measure without the need of any aggregated ranking.
Inline Citation Classification using Peripheral Context and Time-evolving Augmentation
Mar 01, 2023



Citation plays a pivotal role in determining the associations among research articles. It portrays essential information in indicative, supportive, or contrastive studies. The task of inline citation classification aids in extrapolating these relationships; However, existing studies are still immature and demand further scrutiny. Current datasets and methods used for inline citation classification only use citation-marked sentences constraining the model to turn a blind eye to domain knowledge and neighboring contextual sentences. In this paper, we propose a new dataset, named 3Cext, which along with the cited sentences, provides discourse information using the vicinal sentences to analyze the contrasting and entailing relationships as well as domain information. We propose PeriCite, a Transformer-based deep neural network that fuses peripheral sentences and domain knowledge. Our model achieves the state-of-the-art on the 3Cext dataset by +0.09 F1 against the best baseline. We conduct extensive ablations to analyze the efficacy of the proposed dataset and model fusion methods.
Formal Ontology Learning from English IS-A Sentences
Feb 11, 2018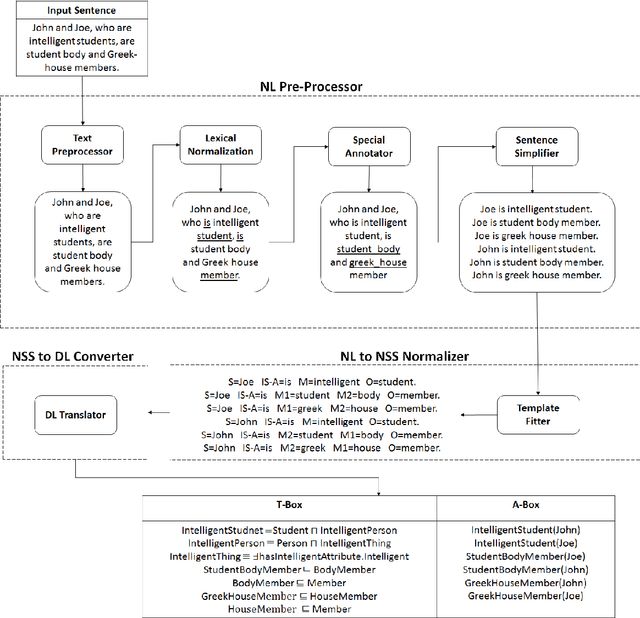
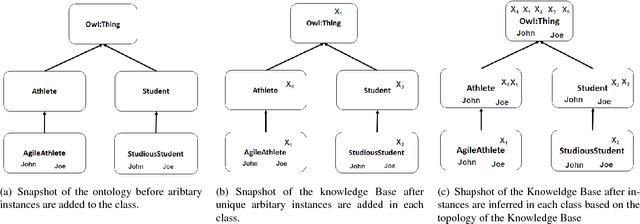

Ontology learning (OL) is the process of automatically generating an ontological knowledge base from a plain text document. In this paper, we propose a new ontology learning approach and tool, called DLOL, which generates a knowledge base in the description logic (DL) SHOQ(D) from a collection of factual non-negative IS-A sentences in English. We provide extensive experimental results on the accuracy of DLOL, giving experimental comparisons to three state-of-the-art existing OL tools, namely Text2Onto, FRED, and LExO. Here, we use the standard OL accuracy measure, called lexical accuracy, and a novel OL accuracy measure, called instance-based inference model. In our experimental results, DLOL turns out to be about 21% and 46%, respectively, better than the best of the other three approaches.
SimDoc: Topic Sequence Alignment based Document Similarity Framework
Nov 11, 2017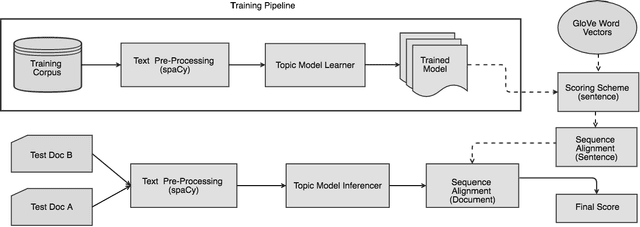

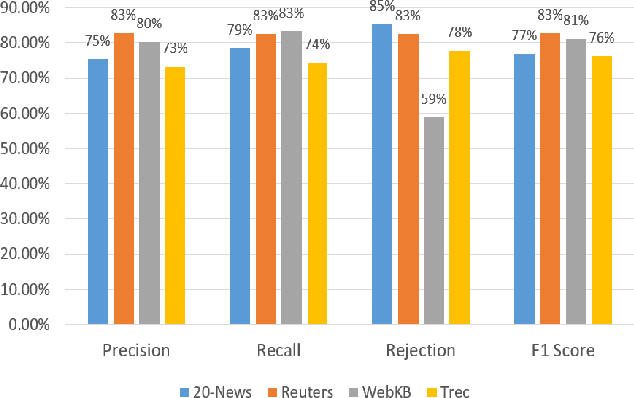

Document similarity is the problem of estimating the degree to which a given pair of documents has similar semantic content. An accurate document similarity measure can improve several enterprise relevant tasks such as document clustering, text mining, and question-answering. In this paper, we show that a document's thematic flow, which is often disregarded by bag-of-word techniques, is pivotal in estimating their similarity. To this end, we propose a novel semantic document similarity framework, called SimDoc. We model documents as topic-sequences, where topics represent latent generative clusters of related words. Then, we use a sequence alignment algorithm to estimate their semantic similarity. We further conceptualize a novel mechanism to compute topic-topic similarity to fine tune our system. In our experiments, we show that SimDoc outperforms many contemporary bag-of-words techniques in accurately computing document similarity, and on practical applications such as document clustering.
Formal Ontology Learning on Factual IS-A Corpus in English using Description Logics
Mar 08, 2016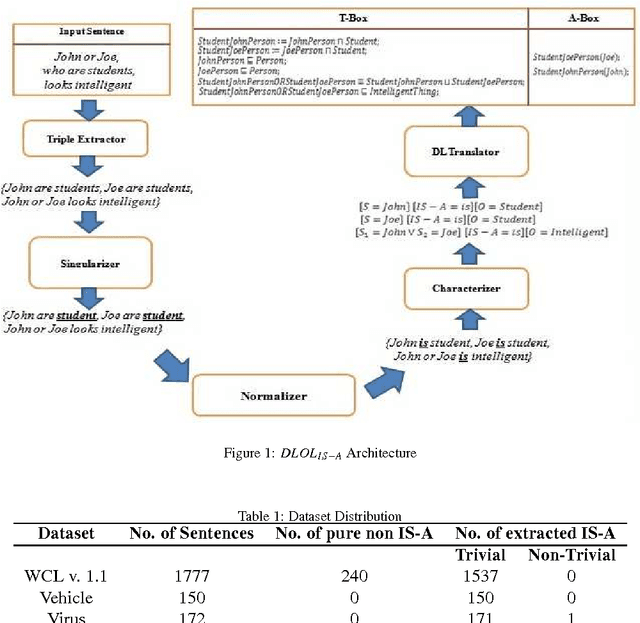

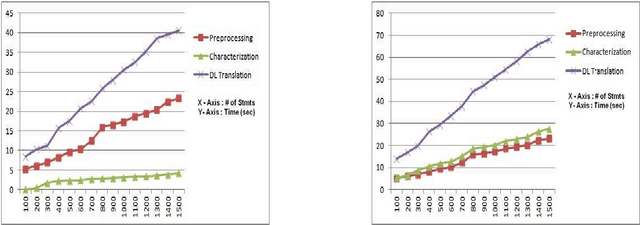
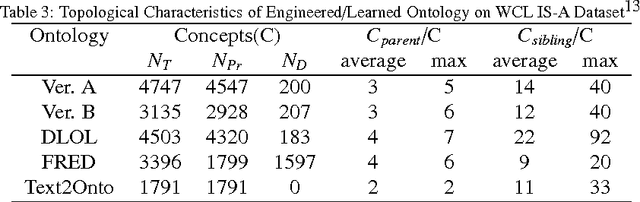
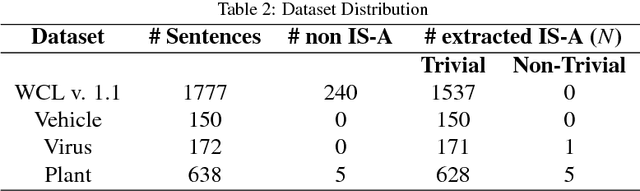
Ontology Learning (OL) is the computational task of generating a knowledge base in the form of an ontology given an unstructured corpus whose content is in natural language (NL). Several works can be found in this area most of which are limited to statistical and lexico-syntactic pattern matching based techniques Light-Weight OL. These techniques do not lead to very accurate learning mostly because of several linguistic nuances in NL. Formal OL is an alternative (less explored) methodology were deep linguistics analysis is made using theory and tools found in computational linguistics to generate formal axioms and definitions instead simply inducing a taxonomy. In this paper we propose "Description Logic (DL)" based formal OL framework for learning factual IS-A type sentences in English. We claim that semantic construction of IS-A sentences is non trivial. Hence, we also claim that such sentences requires special studies in the context of OL before any truly formal OL can be proposed. We introduce a learner tool, called DLOL_IS-A, that generated such ontologies in the owl format. We have adopted "Gold Standard" based OL evaluation on IS-A rich WCL v.1.1 dataset and our own Community representative IS-A dataset. We observed significant improvement of DLOL_IS-A when compared to the light-weight OL tool Text2Onto and formal OL tool FRED.
BitSim: An Algebraic Similarity Measure for Description Logics Concepts
Mar 19, 2015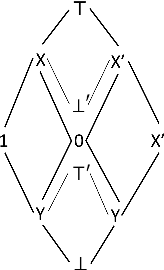
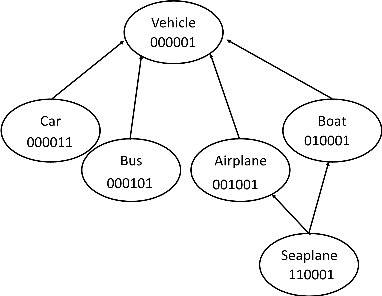
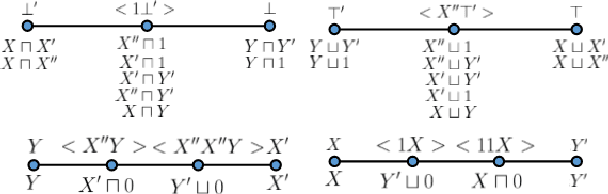
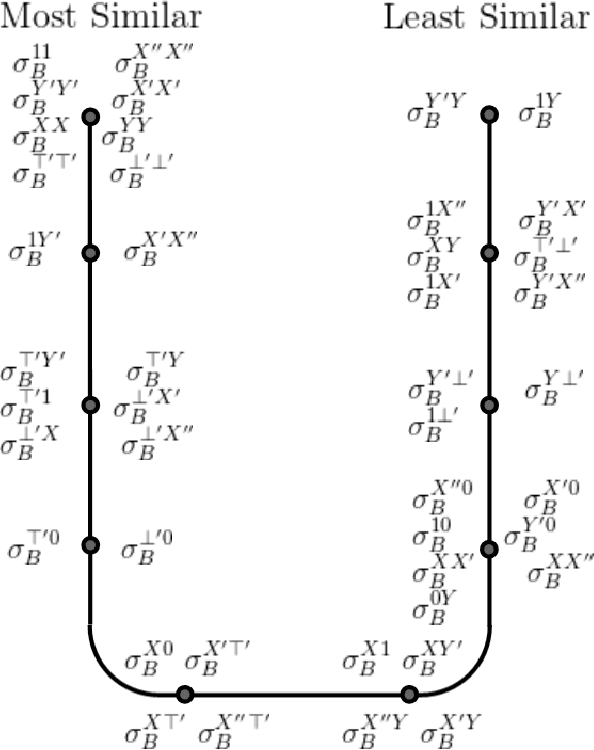
In this paper, we propose an algebraic similarity measure {\sigma}BS (BS stands for BitSim) for assigning semantic similarity score to concept definitions in ALCH+ an expressive fragment of Description Logics (DL). We define an algebraic interpretation function, I_B, that maps a concept definition to a unique string ({\omega}_B) called bit-code) over an alphabet {\Sigma}_B of 11 symbols belonging to L_B - the language over P B. IB has semantic correspondence with conventional model-theoretic interpretation of DL. We then define {\sigma}_BS on L_B. A detailed analysis of I_B and {\sigma}_BS has been given.
Description Logics based Formalization of Wh-Queries
Dec 25, 2013


The problem of Natural Language Query Formalization (NLQF) is to translate a given user query in natural language (NL) into a formal language so that the semantic interpretation has equivalence with the NL interpretation. Formalization of NL queries enables logic based reasoning during information retrieval, database query, question-answering, etc. Formalization also helps in Web query normalization and indexing, query intent analysis, etc. In this paper we are proposing a Description Logics based formal methodology for wh-query intent (also called desire) identification and corresponding formal translation. We evaluated the scalability of our proposed formalism using Microsoft Encarta 98 query dataset and OWL-S TC v.4.0 dataset.
DLOLIS-A: Description Logic based Text Ontology Learning
Mar 24, 2013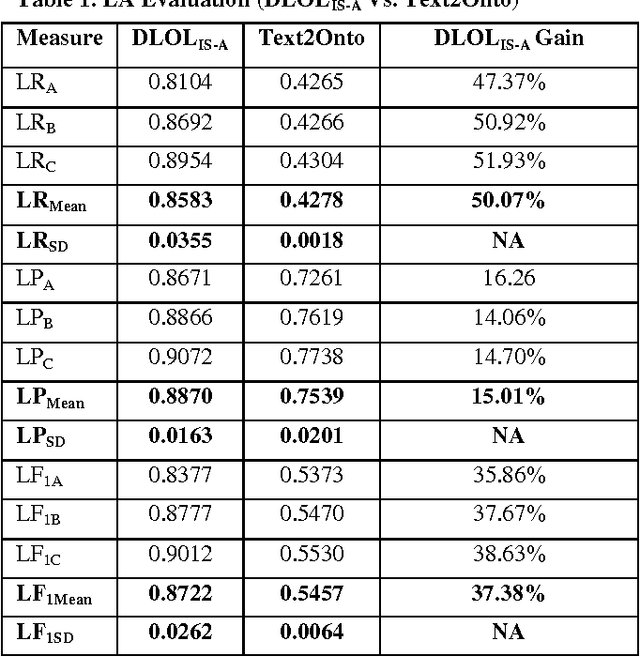

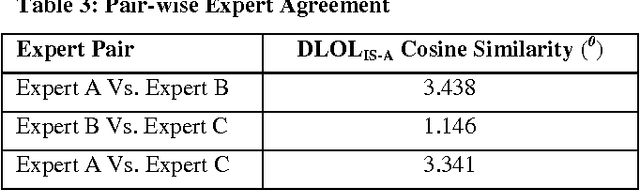
Ontology Learning has been the subject of intensive study for the past decade. Researchers in this field have been motivated by the possibility of automatically building a knowledge base on top of text documents so as to support reasoning based knowledge extraction. While most works in this field have been primarily statistical (known as light-weight Ontology Learning) not much attempt has been made in axiomatic Ontology Learning (called heavy-weight Ontology Learning) from Natural Language text documents. Heavy-weight Ontology Learning supports more precise formal logic-based reasoning when compared to statistical ontology learning. In this paper we have proposed a sound Ontology Learning tool DLOL_(IS-A) that maps English language IS-A sentences into their equivalent Description Logic (DL) expressions in order to automatically generate a consistent pair of T-box and A-box thereby forming both regular (definitional form) and generalized (axiomatic form) DL ontology. The current scope of the paper is strictly limited to IS-A sentences that exclude the possible structures of: (i) implicative IS-A sentences, and (ii) "Wh" IS-A questions. Other linguistic nuances that arise out of pragmatics and epistemic of IS-A sentences are beyond the scope of this present work. We have adopted Gold Standard based Ontology Learning evaluation on chosen IS-A rich Wikipedia documents.