 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerSEval: Assessing Personalization in Text Summarizers
Paper and Code
Jun 29, 2024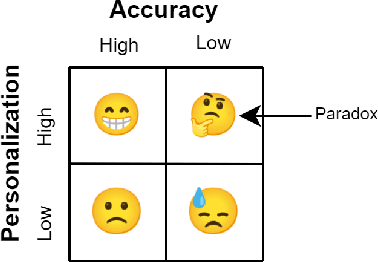
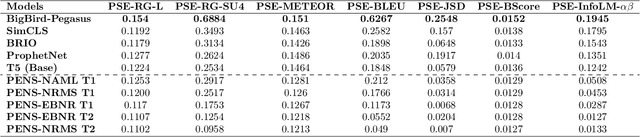
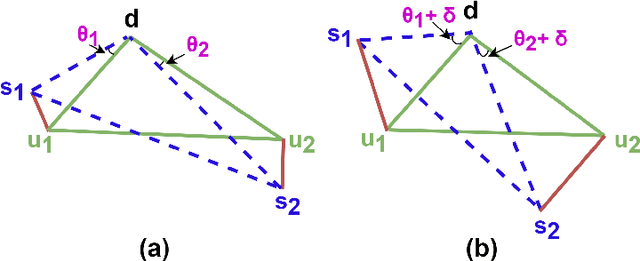

Personalized summarization models cater to individuals' subjective understanding of saliency, as represented by their reading history and current topics of attention. Existing personalized text summarizers are primarily evaluated based on accuracy measures such as BLEU, ROUGE, and METEOR. However, a recent study argued that accuracy measures are inadequate for evaluating the degree of personalization of these models and proposed EGISES, the first metric to evaluate personalized text summaries. It was suggested that accuracy is a separate aspect and should be evaluated standalone. In this paper, we challenge the necessity of an accuracy leaderboard, suggesting that relying on accuracy-based aggregated results might lead to misleading conclusions. To support this, we delve deeper into EGISES, demonstrating both theoretically and empirically that it measures the degree of responsiveness, a necessary but not sufficient condition for degree-of-personalization. We subsequently propose PerSEval, a novel measure that satisfies the required sufficiency condition. Based on the benchmarking of ten SOTA summarization models on the PENS dataset, we empirically establish that -- (i) PerSEval is reliable w.r.t human-judgment correlation (Pearson's r = 0.73; Spearman's $\rho$ = 0.62; Kendall's $\tau$ = 0.42), (ii) PerSEval has high rank-stability, (iii) PerSEval as a rank-measure is not entailed by EGISES-based ranking, and (iv) PerSEval can be a standalone rank-measure without the need of any aggregated ranking.