 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural ATTF: A Scalable Solution to Lifelong Multi-Agent Path Planning
Apr 21, 2025



Multi-Agent Pickup and Delivery (MAPD) is a fundamental problem in robotics, particularly in applications such as warehouse automation and logistics. Existing solutions often face challenges in scalability, adaptability, and efficiency, limiting their applicability in dynamic environments with real-time planning requirements. This paper presents Neural ATTF (Adaptive Task Token Framework), a new algorithm that combines a Priority Guided Task Matching (PGTM) Module with Neural STA* (Space-Time A*), a data-driven path planning method. Neural STA* enhances path planning by enabling rapid exploration of the search space through guided learned heuristics and ensures collision avoidance under dynamic constraints. PGTM prioritizes delayed agents and dynamically assigns tasks by prioritizing agents nearest to these tasks, optimizing both continuity and system throughput. Experimental evaluations against state-of-the-art MAPD algorithms, including TPTS, CENTRAL, RMCA, LNS-PBS, and LNS-wPBS, demonstrate the superior scalability, solution quality, and computational efficiency of Neural ATTF. These results highlight the framework's potential for addressing the critical demands of complex, real-world multi-agent systems operating in high-demand, unpredictable settings.
KFinEval-Pilot: A Comprehensive Benchmark Suite for Korean Financial Language Understanding
Apr 17, 2025We introduce KFinEval-Pilot, a benchmark suite specifically designed to evaluate large language models (LLMs) in the Korean financial domain. Addressing the limitations of existing English-centric benchmarks, KFinEval-Pilot comprises over 1,000 curated questions across three critical areas: financial knowledge, legal reasoning, and financial toxicity. The benchmark is constructed through a semi-automated pipeline that combines GPT-4-generated prompts with expert validation to ensure domain relevance and factual accuracy. We evaluate a range of representative LLMs and observe notable performance differences across models, with trade-offs between task accuracy and output safety across different model families. These results highlight persistent challenges in applying LLMs to high-stakes financial applications, particularly in reasoning and safety. Grounded in real-world financial use cases and aligned with the Korean regulatory and linguistic context, KFinEval-Pilot serves as an early diagnostic tool for developing safer and more reliable financial AI systems.
Multi-Speaker End-to-End Speech Synthesis
Jul 09, 2019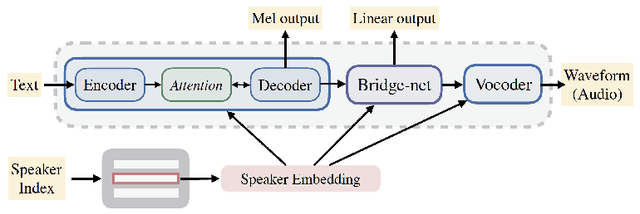
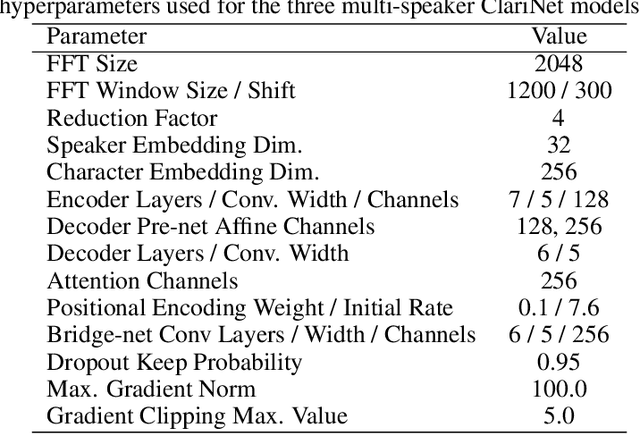
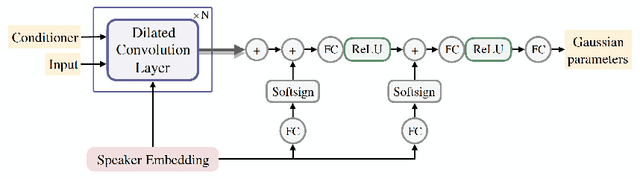
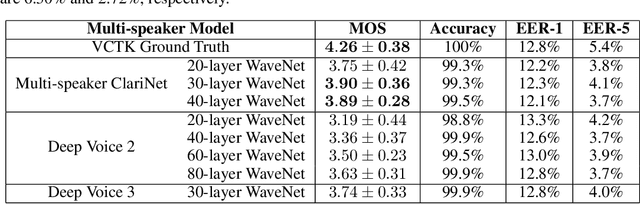
In this work, we extend ClariNet (Ping et al., 2019), a fully end-to-end speech synthesis model (i.e., text-to-wave), to generate high-fidelity speech from multiple speakers. To model the unique characteristic of different voices, low dimensional trainable speaker embeddings are shared across each component of ClariNet and trained together with the rest of the model. We demonstrate that the multi-speaker ClariNet outperforms state-of-the-art systems in terms of naturalness, because the whole model is jointly optimized in an end-to-end manner.