 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGCleaner : Identifying and Correcting Errors Produced by Information Extraction Systems
Paper and Code
Aug 15, 2018
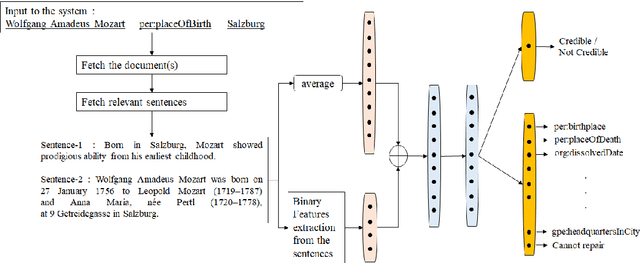

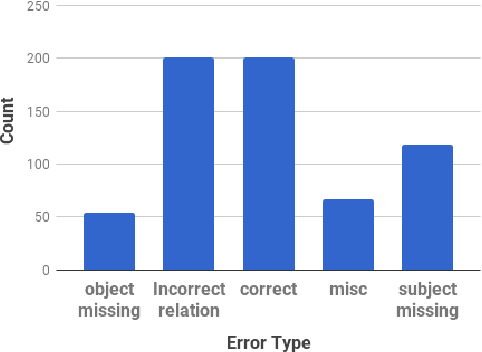
KGCleaner is a framework to identify and correct errors in data produced and delivered by an information extraction system. These tasks have been understudied and KGCleaner is the first to address both. We introduce a multi-task model that jointly learns to predict if an extracted relation is credible and repair it if not. We evaluate our approach and other models as instance of our framework on two collections: a Wikidata corpus of nearly 700K facts and 5M fact-relevant sentences and a collection of 30K facts from the 2015 TAC Knowledge Base Population task. For credibility classification, parameter efficient simple shallow neural network can achieve an absolute performance gain of 30 $F_1$ points on Wikidata and comparable performance on TAC. For the repair task, significant performance (at more than twice) gain can be obtained depending on the nature of the dataset and the models.