 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFact Checking Beyond Training Set
Mar 27, 2024Evaluating the veracity of everyday claims is time consuming and in some cases requires domain expertise. We empirically demonstrate that the commonly used fact checking pipeline, known as the retriever-reader, suffers from performance deterioration when it is trained on the labeled data from one domain and used in another domain. Afterwards, we delve into each component of the pipeline and propose novel algorithms to address this problem. We propose an adversarial algorithm to make the retriever component robust against distribution shift. Our core idea is to initially train a bi-encoder on the labeled source data, and then, to adversarially train two separate document and claim encoders using unlabeled target data. We then focus on the reader component and propose to train it such that it is insensitive towards the order of claims and evidence documents. Our empirical evaluations support the hypothesis that such a reader shows a higher robustness against distribution shift. To our knowledge, there is no publicly available multi-topic fact checking dataset. Thus, we propose a simple automatic method to re-purpose two well-known fact checking datasets. We then construct eight fact checking scenarios from these datasets, and compare our model to a set of strong baseline models, including recent domain adaptation models that use GPT4 for generating synthetic data.
Masked LoGoNet: Fast and Accurate 3D Image Analysis for Medical Domain
Feb 09, 2024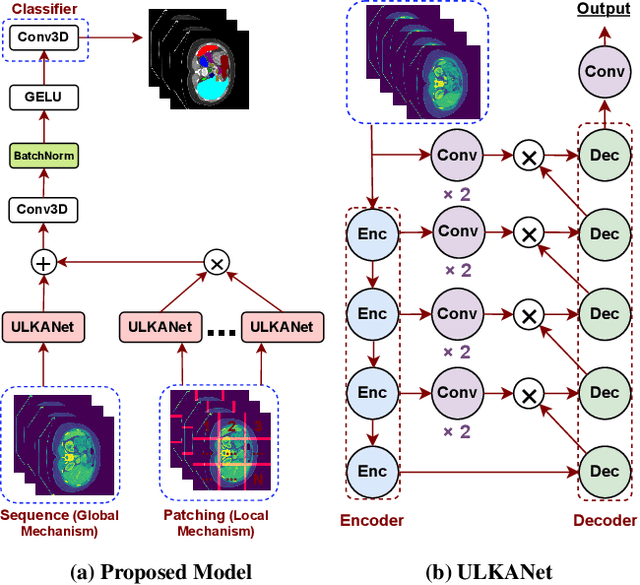
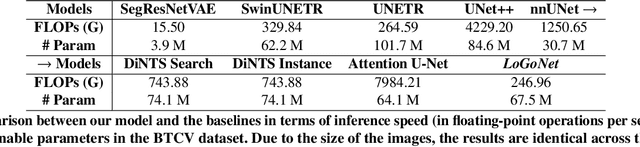
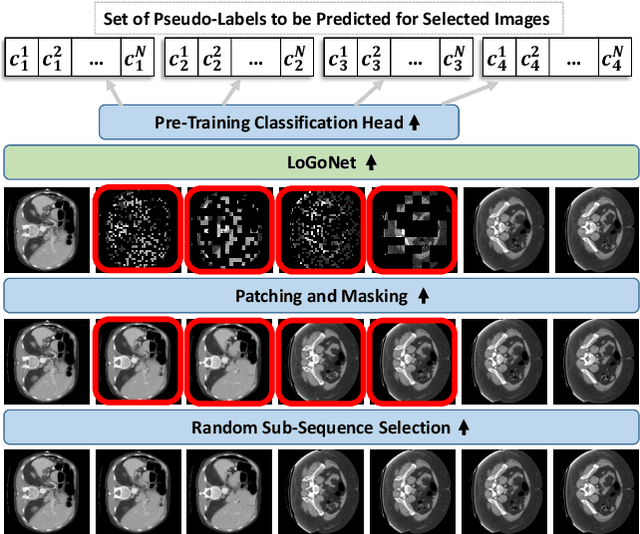
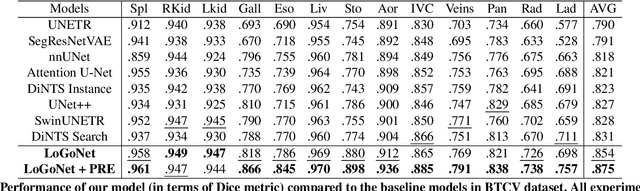
Standard modern machine-learning-based imaging methods have faced challenges in medical applications due to the high cost of dataset construction and, thereby, the limited labeled training data available. Additionally, upon deployment, these methods are usually used to process a large volume of data on a daily basis, imposing a high maintenance cost on medical facilities. In this paper, we introduce a new neural network architecture, termed LoGoNet, with a tailored self-supervised learning (SSL) method to mitigate such challenges. LoGoNet integrates a novel feature extractor within a U-shaped architecture, leveraging Large Kernel Attention (LKA) and a dual encoding strategy to capture both long-range and short-range feature dependencies adeptly. This is in contrast to existing methods that rely on increasing network capacity to enhance feature extraction. This combination of novel techniques in our model is especially beneficial in medical image segmentation, given the difficulty of learning intricate and often irregular body organ shapes, such as the spleen. Complementary, we propose a novel SSL method tailored for 3D images to compensate for the lack of large labeled datasets. The method combines masking and contrastive learning techniques within a multi-task learning framework and is compatible with both Vision Transformer (ViT) and CNN-based models. We demonstrate the efficacy of our methods in numerous tasks across two standard datasets (i.e., BTCV and MSD). Benchmark comparisons with eight state-of-the-art models highlight LoGoNet's superior performance in both inference time and accuracy.
Name Tagging Under Domain Shift via Metric Learning for Life Sciences
Jan 19, 2024



Name tagging is a key component of Information Extraction (IE), particularly in scientific domains such as biomedicine and chemistry, where large language models (LLMs), e.g., ChatGPT, fall short. We investigate the applicability of transfer learning for enhancing a name tagging model trained in the biomedical domain (the source domain) to be used in the chemical domain (the target domain). A common practice for training such a model in a few-shot learning setting is to pretrain the model on the labeled source data, and then, to finetune it on a hand-full of labeled target examples. In our experiments we observed that such a model is prone to mis-labeling the source entities, which can often appear in the text, as the target entities. To alleviate this problem, we propose a model to transfer the knowledge from the source domain to the target domain, however, at the same time, to project the source entities and target entities into separate regions of the feature space. This diminishes the risk of mis-labeling the source entities as the target entities. Our model consists of two stages: 1) entity grouping in the source domain, which incorporates knowledge from annotated events to establish relations between entities, and 2) entity discrimination in the target domain, which relies on pseudo labeling and contrastive learning to enhance discrimination between the entities in the two domains. We carry out our extensive experiments across three source and three target datasets, and demonstrate that our method outperforms the baselines, in some scenarios by 5\% absolute value.
Neural Networks Against (and For) Self-Training: Classification with Small Labeled and Large Unlabeled Sets
Dec 31, 2023We propose a semi-supervised text classifier based on self-training using one positive and one negative property of neural networks. One of the weaknesses of self-training is the semantic drift problem, where noisy pseudo-labels accumulate over iterations and consequently the error rate soars. In order to tackle this challenge, we reshape the role of pseudo-labels and create a hierarchical order of information. In addition, a crucial step in self-training is to use the classifier confidence prediction to select the best candidate pseudo-labels. This step cannot be efficiently done by neural networks, because it is known that their output is poorly calibrated. To overcome this challenge, we propose a hybrid metric to replace the plain confidence measurement. Our metric takes into account the prediction uncertainty via a subsampling technique. We evaluate our model in a set of five standard benchmarks, and show that it significantly outperforms a set of ten diverse baseline models. Furthermore, we show that the improvement achieved by our model is additive to language model pretraining, which is a widely used technique for using unlabeled documents. Our code is available at https://github.com/p-karisani/RST.
Ericson: An Interactive Open-Domain Conversational Search Agent
Apr 05, 2023


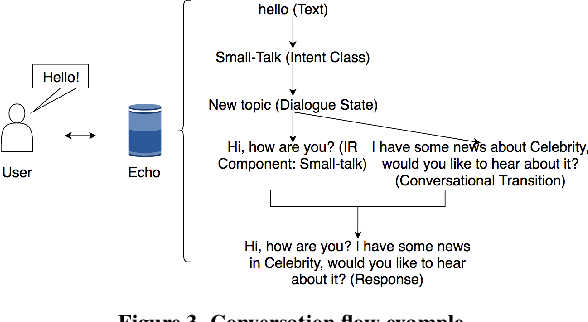
Open-domain conversational search (ODCS) aims to provide valuable, up-to-date information, while maintaining natural conversations to help users refine and ultimately answer information needs. However, creating an effective and robust ODCS agent is challenging. In this paper, we present a fully functional ODCS system, Ericson, which includes state-of-the-art question answering and information retrieval components, as well as intent inference and dialogue management models for proactive question refinement and recommendations. Our system was stress-tested in the Amazon Alexa Prize, by engaging in live conversations with thousands of Alexa users, thus providing empirical basis for the analysis of the ODCS system in real settings. Our interaction data analysis revealed that accurate intent classification, encouraging user engagement, and careful proactive recommendations contribute most to the users satisfaction. Our study further identifies limitations of the existing search techniques, and can serve as a building block for the next generation of ODCS agents.
Detecting Elevated Air Pollution Levels by Monitoring Web Search Queries: Deep Learning-Based Time Series Forecasting
Nov 09, 2022



Real-time air pollution monitoring is a valuable tool for public health and environmental surveillance. In recent years, there has been a dramatic increase in air pollution forecasting and monitoring research using artificial neural networks (ANNs). Most of the prior work relied on modeling pollutant concentrations collected from ground-based monitors and meteorological data for long-term forecasting of outdoor ozone, oxides of nitrogen, and PM2.5. Given that traditional, highly sophisticated air quality monitors are expensive and are not universally available, these models cannot adequately serve those not living near pollutant monitoring sites. Furthermore, because prior models were built on physical measurement data collected from sensors, they may not be suitable for predicting public health effects experienced from pollution exposure. This study aims to develop and validate models to nowcast the observed pollution levels using Web search data, which is publicly available in near real-time from major search engines. We developed novel machine learning-based models using both traditional supervised classification methods and state-of-the-art deep learning methods to detect elevated air pollution levels at the US city level, by using generally available meteorological data and aggregate Web-based search volume data derived from Google Trends. We validated the performance of these methods by predicting three critical air pollutants (ozone (O3), nitrogen dioxide (NO2), and fine particulate matter (PM2.5)), across ten major U.S. metropolitan statistical areas (MSAs) in 2017 and 2018.
Multiple-Source Domain Adaptation via Coordinated Domain Encoders and Paired Classifiers
Jan 28, 2022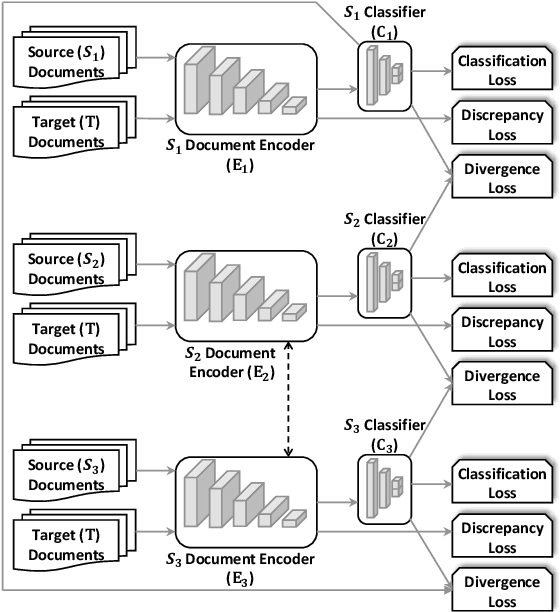
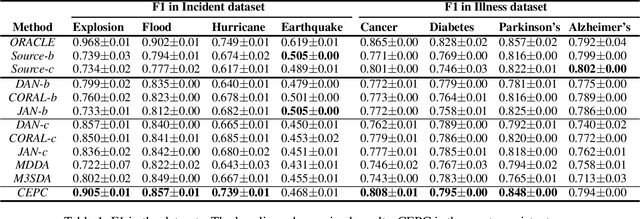
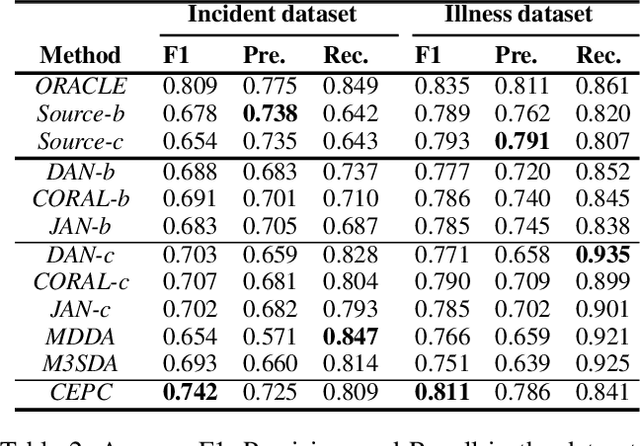

We present a novel multiple-source unsupervised model for text classification under domain shift. Our model exploits the update rates in document representations to dynamically integrate domain encoders. It also employs a probabilistic heuristic to infer the error rate in the target domain in order to pair source classifiers. Our heuristic exploits data transformation cost and the classifier accuracy in the target feature space. We have used real world scenarios of Domain Adaptation to evaluate the efficacy of our algorithm. We also used pretrained multi-layer transformers as the document encoder in the experiments to demonstrate whether the improvement achieved by domain adaptation models can be delivered by out-of-the-box language model pretraining. The experiments testify that our model is the top performing approach in this setting.
Contextual Multi-View Query Learning for Short Text Classification in User-Generated Data
Dec 05, 2021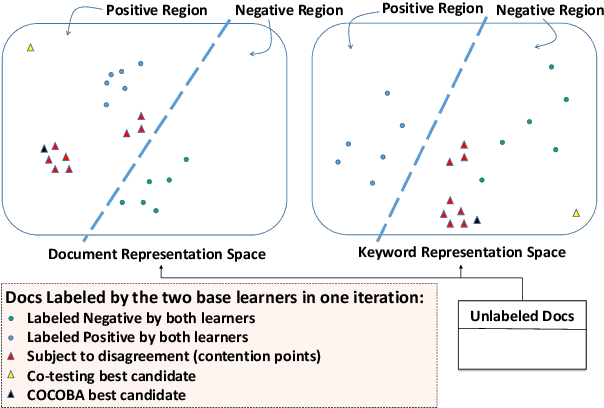
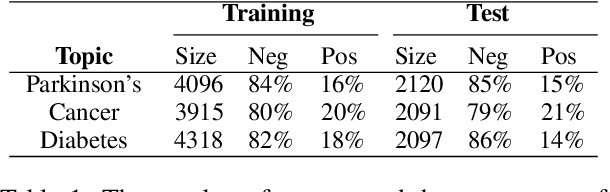
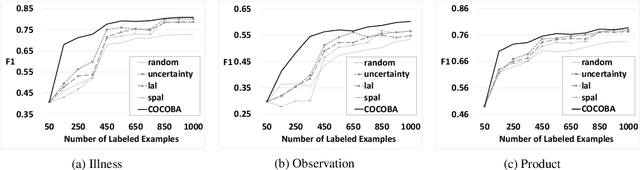

Mining user-generated content--e.g., for the early detection of outbreaks or for extracting personal observations--often suffers from the lack of enough training data, short document length, and informal language model. We propose a novel multi-view active learning model, called Context-aware Co-testing with Bagging (COCOBA), to address these issues in the classification tasks tailored for a query word--e.g., detecting illness reports given the disease name. COCOBA employs the context of user postings to construct two views. Then it uses the distribution of the representations in each view to detect the regions that are assigned to the opposite classes. This effectively leads to detecting the contexts that the two base learners disagree on. Our model also employs a query-by-committee model to address the usually noisy language of user postings. The experiments testify that our model is applicable to multiple important representative Twitter tasks and also significantly outperforms the existing baselines.
Semi-Supervised Text Classification via Self-Pretraining
Sep 30, 2021
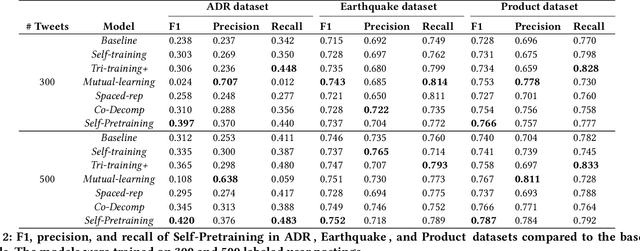
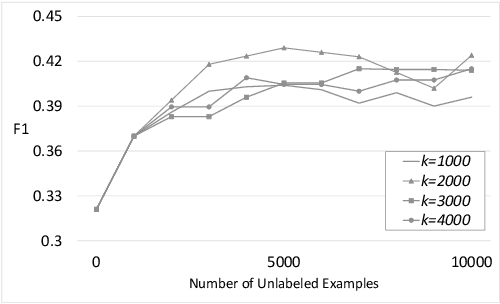
We present a neural semi-supervised learning model termed Self-Pretraining. Our model is inspired by the classic self-training algorithm. However, as opposed to self-training, Self-Pretraining is threshold-free, it can potentially update its belief about previously labeled documents, and can cope with the semantic drift problem. Self-Pretraining is iterative and consists of two classifiers. In each iteration, one classifier draws a random set of unlabeled documents and labels them. This set is used to initialize the second classifier, to be further trained by the set of labeled documents. The algorithm proceeds to the next iteration and the classifiers' roles are reversed. To improve the flow of information across the iterations and also to cope with the semantic drift problem, Self-Pretraining employs an iterative distillation process, transfers hypotheses across the iterations, utilizes a two-stage training model, uses an efficient learning rate schedule, and employs a pseudo-label transformation heuristic. We have evaluated our model in three publicly available social media datasets. Our experiments show that Self-Pretraining outperforms the existing state-of-the-art semi-supervised classifiers across multiple settings. Our code is available at https://github.com/p-karisani/self_pretraining.
View Distillation with Unlabeled Data for Extracting Adverse Drug Effects from User-Generated Data
May 24, 2021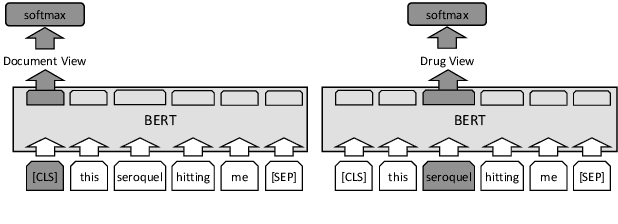



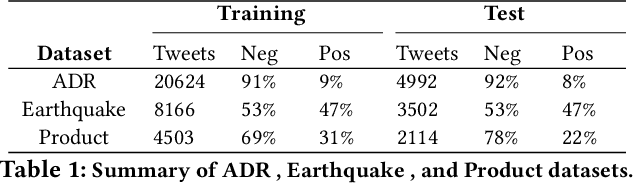
We present an algorithm based on multi-layer transformers for identifying Adverse Drug Reactions (ADR) in social media data. Our model relies on the properties of the problem and the characteristics of contextual word embeddings to extract two views from documents. Then a classifier is trained on each view to label a set of unlabeled documents to be used as an initializer for a new classifier in the other view. Finally, the initialized classifier in each view is further trained using the initial training examples. We evaluated our model in the largest publicly available ADR dataset. The experiments testify that our model significantly outperforms the transformer-based models pretrained on domain-specific data.