 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECLIPSE: An Evolutionary Computation Library for Instrumentation Prototyping in Scientific Engineering
Jan 08, 2026Designing scientific instrumentation often requires exploring large, highly constrained design spaces using computationally expensive physics simulations. These simulators pose substantial challenges for integrating evolutionary computation (EC) into scientific design workflows. Evolutionary computation typically requires numerous design evaluations, making the integration of slow, low-throughput simulators particularly challenging, as they are optimized for accuracy and ease of use rather than throughput. We present ECLIPSE, an evolutionary computation framework built to interface directly with complex, domain-specific simulation tools while supporting flexible geometric and parametric representations of scientific hardware. ECLIPSE provides a modular architecture consisting of (1) Individuals, which encode hardware designs using domain-aware, physically constrained representations; (2) Evaluators, which prepare simulation inputs, invoke external simulators, and translate the simulator's outputs into fitness measures; and (3) Evolvers, which implement EC algorithms suitable for high-cost, limited-throughput environments. We demonstrate the utility of ECLIPSE across several active space-science applications, including evolved 3D antennas and spacecraft geometries optimized for drag reduction in very low Earth orbit. We further discuss the practical challenges encountered when coupling EC with scientific simulation workflows, including interoperability constraints, parallelization limits, and extreme evaluation costs, and outline ongoing efforts to combat these challenges. ECLIPSE enables interdisciplinary teams of physicists, engineers, and EC researchers to collaboratively explore unconventional designs for scientific hardware while leveraging existing domain-specific simulation software.
DSSRNN: Decomposition-Enhanced State-Space Recurrent Neural Network for Time-Series Analysis
Dec 01, 2024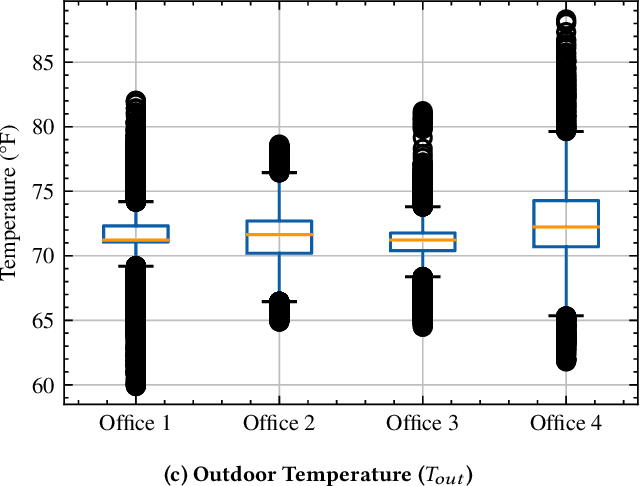
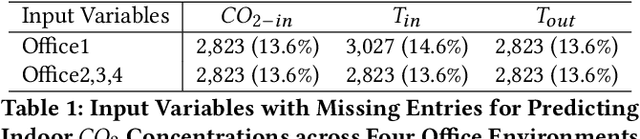
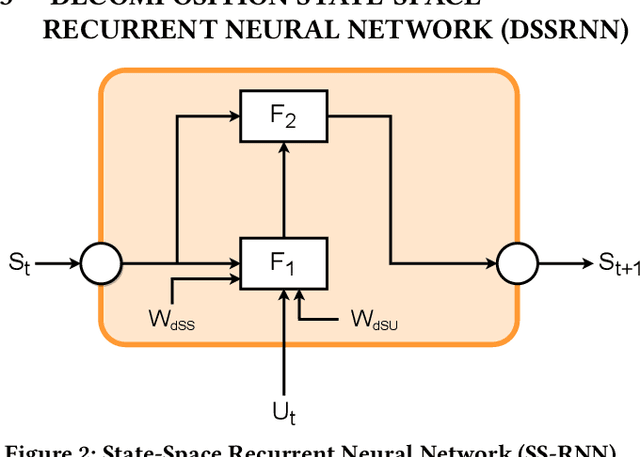
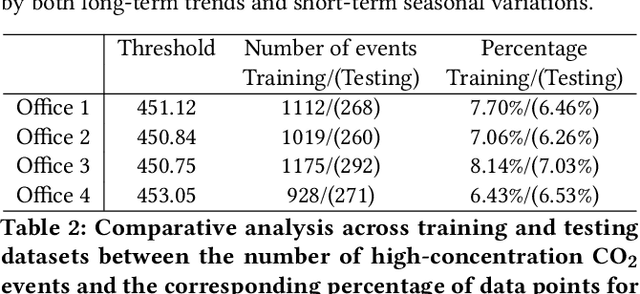
Time series forecasting is a crucial yet challenging task in machine learning, requiring domain-specific knowledge due to its wide-ranging applications. While recent Transformer models have improved forecasting capabilities, they come with high computational costs. Linear-based models have shown better accuracy than Transformers but still fall short of ideal performance. To address these challenges, we introduce the Decomposition State-Space Recurrent Neural Network (DSSRNN), a novel framework designed for both long-term and short-term time series forecasting. DSSRNN uniquely combines decomposition analysis to capture seasonal and trend components with state-space models and physics-based equations. We evaluate DSSRNN's performance on indoor air quality datasets, focusing on CO2 concentration prediction across various forecasting horizons. Results demonstrate that DSSRNN consistently outperforms state-of-the-art models, including transformer-based architectures, in terms of both Mean Squared Error (MSE) and Mean Absolute Error (MAE). For example, at the shortest horizon (T=96) in Office 1, DSSRNN achieved an MSE of 0.378 and an MAE of 0.401, significantly lower than competing models. Additionally, DSSRNN exhibits superior computational efficiency compared to more complex models. While not as lightweight as the DLinear model, DSSRNN achieves a balance between performance and efficiency, with only 0.11G MACs and 437MiB memory usage, and an inference time of 0.58ms for long-term forecasting. This work not only showcases DSSRNN's success but also establishes a new benchmark for physics-informed machine learning in environmental forecasting and potentially other domains.
DLaVA: Document Language and Vision Assistant for Answer Localization with Enhanced Interpretability and Trustworthiness
Nov 29, 2024Document Visual Question Answering (VQA) requires models to interpret textual information within complex visual layouts and comprehend spatial relationships to answer questions based on document images. Existing approaches often lack interpretability and fail to precisely localize answers within the document, hindering users' ability to verify responses and understand the reasoning process. Moreover, standard metrics like Average Normalized Levenshtein Similarity (ANLS) focus on text accuracy but overlook spatial correctness. We introduce DLaVA, a novel method that enhances Multimodal Large Language Models (MLLMs) with answer localization capabilities for Document VQA. Our approach integrates image annotation directly into the MLLM pipeline, improving interpretability by enabling users to trace the model's reasoning. We present both OCR-dependent and OCR-free architectures, with the OCR-free approach eliminating the need for separate text recognition components, thus reducing complexity. To the best of our knowledge, DLaVA is the first approach to introduce answer localization within multimodal QA, marking a significant step forward in enhancing user trust and reducing the risk of AI hallucinations. Our contributions include enhancing interpretability and reliability by grounding responses in spatially annotated visual content, introducing answer localization in MLLMs, proposing a streamlined pipeline that combines an MLLM with a text detection module, and conducting comprehensive evaluations using both textual and spatial accuracy metrics, including Intersection over Union (IoU). Experimental results on standard datasets demonstrate that DLaVA achieves SOTA performance, significantly enhancing model transparency and reliability. Our approach sets a new benchmark for Document VQA, highlighting the critical importance of precise answer localization and model interpretability.
Scalable Deep Metric Learning on Attributed Graphs
Nov 20, 2024We consider the problem of constructing embeddings of large attributed graphs and supporting multiple downstream learning tasks. We develop a graph embedding method, which is based on extending deep metric and unbiased contrastive learning techniques to 1) work with attributed graphs, 2) enabling a mini-batch based approach, and 3) achieving scalability. Based on a multi-class tuplet loss function, we present two algorithms -- DMT for semi-supervised learning and DMAT-i for the unsupervised case. Analyzing our methods, we provide a generalization bound for the downstream node classification task and for the first time relate tuplet loss to contrastive learning. Through extensive experiments, we show high scalability of representation construction, and in applying the method for three downstream tasks (node clustering, node classification, and link prediction) better consistency over any single existing method.
Federated Contrastive Learning of Graph-Level Representations
Nov 18, 2024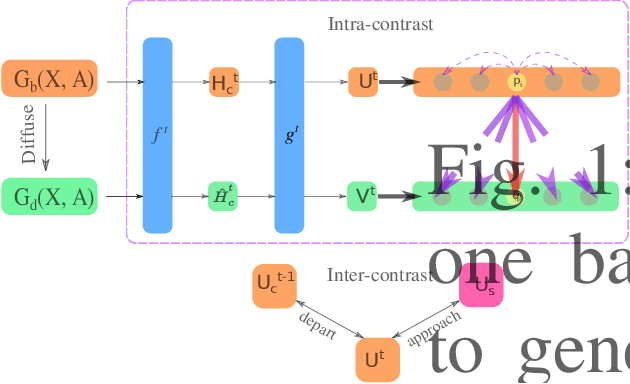
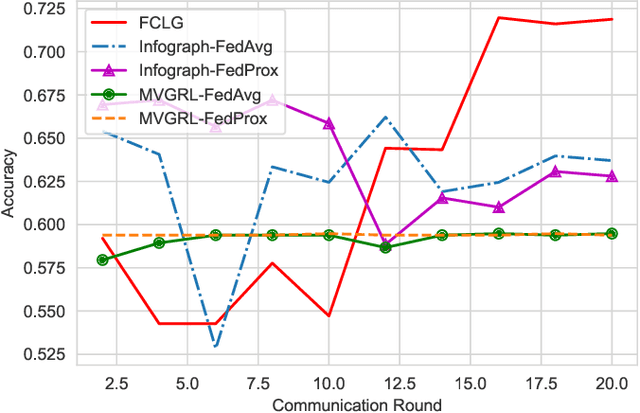

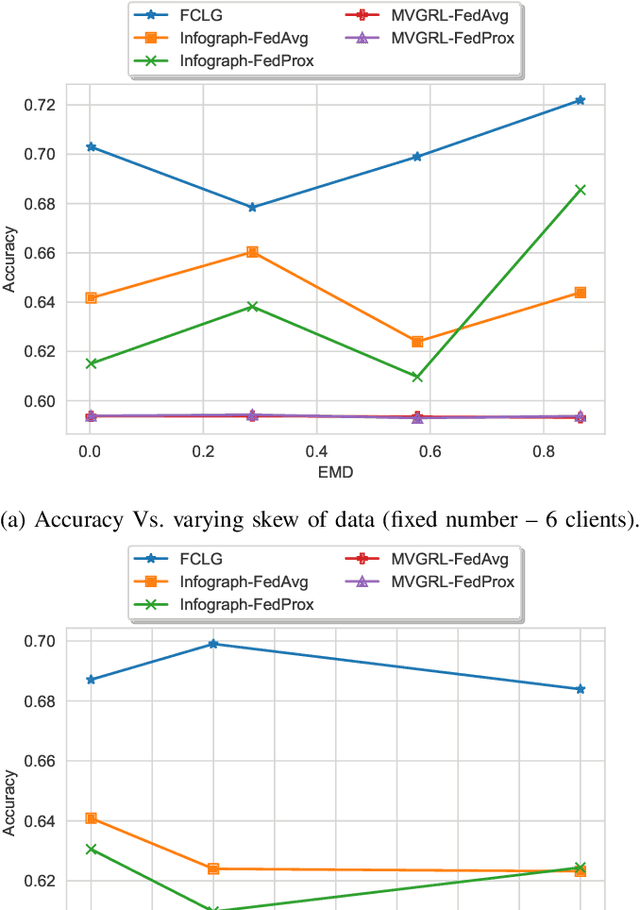
Graph-level representations (and clustering/classification based on these representations) are required in a variety of applications. Examples include identifying malicious network traffic, prediction of protein properties, and many others. Often, data has to stay in isolated local systems (i.e., cannot be centrally shared for analysis) due to a variety of considerations like privacy concerns, lack of trust between the parties, regulations, or simply because the data is too large to be shared sufficiently quickly. This points to the need for federated learning for graph-level representations, a topic that has not been explored much, especially in an unsupervised setting. Addressing this problem, this paper presents a new framework we refer to as Federated Contrastive Learning of Graph-level Representations (FCLG). As the name suggests, our approach builds on contrastive learning. However, what is unique is that we apply contrastive learning at two levels. The first application is for local unsupervised learning of graph representations. The second level is to address the challenge associated with data distribution variation (i.e. the ``Non-IID issue") when combining local models. Through extensive experiments on the downstream task of graph-level clustering, we demonstrate FCLG outperforms baselines (which apply existing federated methods on existing graph-level clustering methods) with significant margins.
KnobGen: Controlling the Sophistication of Artwork in Sketch-Based Diffusion Models
Oct 02, 2024


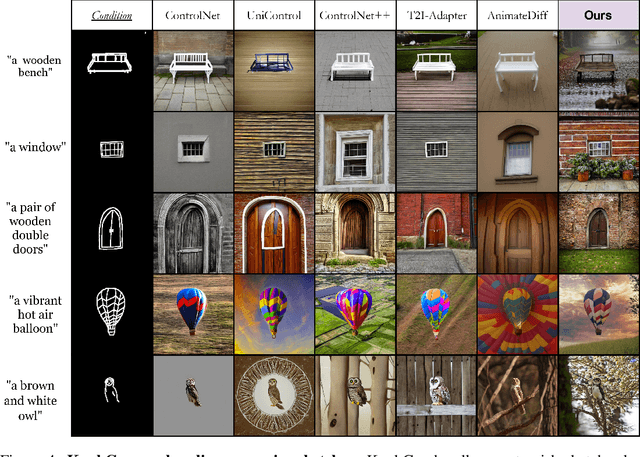
Recent advances in diffusion models have significantly improved text-to-image (T2I) generation, but they often struggle to balance fine-grained precision with high-level control. Methods like ControlNet and T2I-Adapter excel at following sketches by seasoned artists but tend to be overly rigid, replicating unintentional flaws in sketches from novice users. Meanwhile, coarse-grained methods, such as sketch-based abstraction frameworks, offer more accessible input handling but lack the precise control needed for detailed, professional use. To address these limitations, we propose KnobGen, a dual-pathway framework that democratizes sketch-based image generation by seamlessly adapting to varying levels of sketch complexity and user skill. KnobGen uses a Coarse-Grained Controller (CGC) module for high-level semantics and a Fine-Grained Controller (FGC) module for detailed refinement. The relative strength of these two modules can be adjusted through our knob inference mechanism to align with the user's specific needs. These mechanisms ensure that KnobGen can flexibly generate images from both novice sketches and those drawn by seasoned artists. This maintains control over the final output while preserving the natural appearance of the image, as evidenced on the MultiGen-20M dataset and a newly collected sketch dataset.
Frequency-Guided Masking for Enhanced Vision Self-Supervised Learning
Sep 16, 2024We present a novel frequency-based Self-Supervised Learning (SSL) approach that significantly enhances its efficacy for pre-training. Prior work in this direction masks out pre-defined frequencies in the input image and employs a reconstruction loss to pre-train the model. While achieving promising results, such an implementation has two fundamental limitations as identified in our paper. First, using pre-defined frequencies overlooks the variability of image frequency responses. Second, pre-trained with frequency-filtered images, the resulting model needs relatively more data to adapt to naturally looking images during fine-tuning. To address these drawbacks, we propose FOurier transform compression with seLf-Knowledge distillation (FOLK), integrating two dedicated ideas. First, inspired by image compression, we adaptively select the masked-out frequencies based on image frequency responses, creating more suitable SSL tasks for pre-training. Second, we employ a two-branch framework empowered by knowledge distillation, enabling the model to take both the filtered and original images as input, largely reducing the burden of downstream tasks. Our experimental results demonstrate the effectiveness of FOLK in achieving competitive performance to many state-of-the-art SSL methods across various downstream tasks, including image classification, few-shot learning, and semantic segmentation.
DetailCLIP: Detail-Oriented CLIP for Fine-Grained Tasks
Sep 10, 2024



In this paper, we introduce DetailCLIP: A Detail-Oriented CLIP to address the limitations of contrastive learning-based vision-language models, particularly CLIP, in handling detail-oriented and fine-grained tasks like segmentation. While CLIP and its variants excel in the global alignment of image and text representations, they often struggle to capture the fine-grained details necessary for precise segmentation. To overcome these challenges, we propose a novel framework that employs patch-level comparison of self-distillation and pixel-level reconstruction losses, enhanced with an attention-based token removal mechanism. This approach selectively retains semantically relevant tokens, enabling the model to focus on the image's critical regions aligned with the specific functions of our model, including textual information processing, patch comparison, and image reconstruction, ensuring that the model learns high-level semantics and detailed visual features. Our experiments demonstrate that DetailCLIP surpasses existing CLIP-based and traditional self-supervised learning (SSL) models in segmentation accuracy and exhibits superior generalization across diverse datasets. DetailCLIP represents a significant advancement in vision-language modeling, offering a robust solution for tasks that demand high-level semantic understanding and detailed feature extraction. https://github.com/KishoreP1/DetailCLIP.
DocParseNet: Advanced Semantic Segmentation and OCR Embeddings for Efficient Scanned Document Annotation
Jun 25, 2024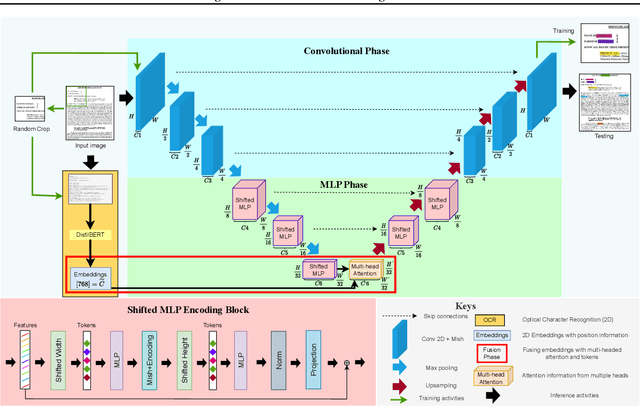

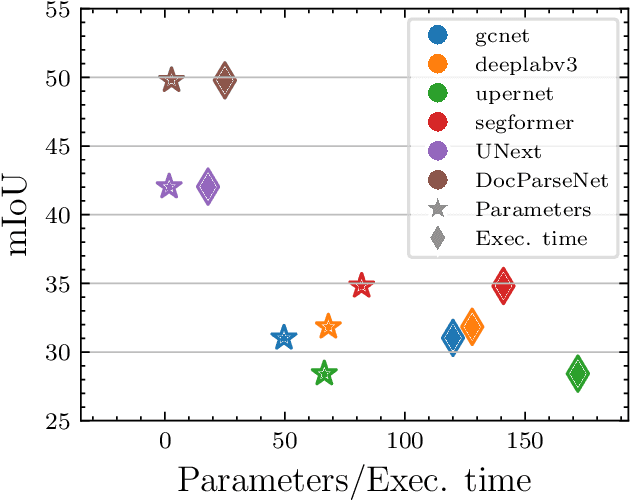
Automating the annotation of scanned documents is challenging, requiring a balance between computational efficiency and accuracy. DocParseNet addresses this by combining deep learning and multi-modal learning to process both text and visual data. This model goes beyond traditional OCR and semantic segmentation, capturing the interplay between text and images to preserve contextual nuances in complex document structures. Our evaluations show that DocParseNet significantly outperforms conventional models, achieving mIoU scores of 49.12 on validation and 49.78 on the test set. This reflects a 58% accuracy improvement over state-of-the-art baseline models and an 18% gain compared to the UNext baseline. Remarkably, DocParseNet achieves these results with only 2.8 million parameters, reducing the model size by approximately 25 times and speeding up training by 5 times compared to other models. These metrics, coupled with a computational efficiency of 0.034 TFLOPs (BS=1), highlight DocParseNet's high performance in document annotation. The model's adaptability and scalability make it well-suited for real-world corporate document processing applications. The code is available at https://github.com/ahmad-shirazi/DocParseNet
Recent Advances in Traffic Accident Analysis and Prediction: A Comprehensive Review of Machine Learning Techniques
Jun 20, 2024



Traffic accidents pose a severe global public health issue, leading to 1.19 million fatalities annually, with the greatest impact on individuals aged 5 to 29 years old. This paper addresses the critical need for advanced predictive methods in road safety by conducting a comprehensive review of recent advancements in applying machine learning (ML) techniques to traffic accident analysis and prediction. It examines 191 studies from the last five years, focusing on predicting accident risk, frequency, severity, duration, as well as general statistical analysis of accident data. To our knowledge, this study is the first to provide such a comprehensive review, covering the state-of-the-art across a wide range of domains related to accident analysis and prediction. The review highlights the effectiveness of integrating diverse data sources and advanced ML techniques to improve prediction accuracy and handle the complexities of traffic data. By mapping the current landscape and identifying gaps in the literature, this study aims to guide future research towards significantly reducing traffic-related deaths and injuries by 2030, aligning with the World Health Organization (WHO) targets.