 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSSRNN: Decomposition-Enhanced State-Space Recurrent Neural Network for Time-Series Analysis
Dec 01, 2024
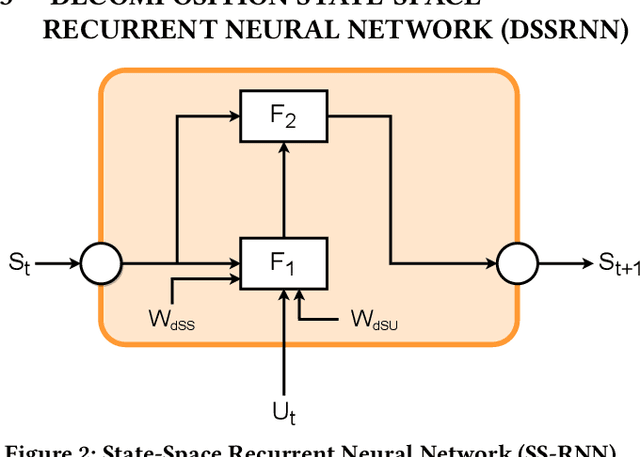
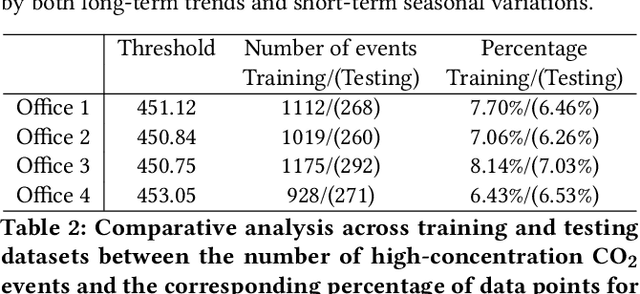
Time series forecasting is a crucial yet challenging task in machine learning, requiring domain-specific knowledge due to its wide-ranging applications. While recent Transformer models have improved forecasting capabilities, they come with high computational costs. Linear-based models have shown better accuracy than Transformers but still fall short of ideal performance. To address these challenges, we introduce the Decomposition State-Space Recurrent Neural Network (DSSRNN), a novel framework designed for both long-term and short-term time series forecasting. DSSRNN uniquely combines decomposition analysis to capture seasonal and trend components with state-space models and physics-based equations. We evaluate DSSRNN's performance on indoor air quality datasets, focusing on CO2 concentration prediction across various forecasting horizons. Results demonstrate that DSSRNN consistently outperforms state-of-the-art models, including transformer-based architectures, in terms of both Mean Squared Error (MSE) and Mean Absolute Error (MAE). For example, at the shortest horizon (T=96) in Office 1, DSSRNN achieved an MSE of 0.378 and an MAE of 0.401, significantly lower than competing models. Additionally, DSSRNN exhibits superior computational efficiency compared to more complex models. While not as lightweight as the DLinear model, DSSRNN achieves a balance between performance and efficiency, with only 0.11G MACs and 437MiB memory usage, and an inference time of 0.58ms for long-term forecasting. This work not only showcases DSSRNN's success but also establishes a new benchmark for physics-informed machine learning in environmental forecasting and potentially other domains.
DLaVA: Document Language and Vision Assistant for Answer Localization with Enhanced Interpretability and Trustworthiness
Nov 29, 2024

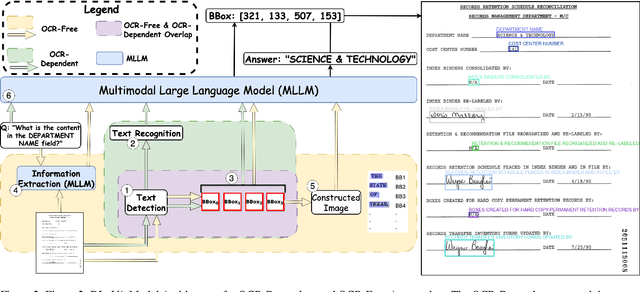

Document Visual Question Answering (VQA) requires models to interpret textual information within complex visual layouts and comprehend spatial relationships to answer questions based on document images. Existing approaches often lack interpretability and fail to precisely localize answers within the document, hindering users' ability to verify responses and understand the reasoning process. Moreover, standard metrics like Average Normalized Levenshtein Similarity (ANLS) focus on text accuracy but overlook spatial correctness. We introduce DLaVA, a novel method that enhances Multimodal Large Language Models (MLLMs) with answer localization capabilities for Document VQA. Our approach integrates image annotation directly into the MLLM pipeline, improving interpretability by enabling users to trace the model's reasoning. We present both OCR-dependent and OCR-free architectures, with the OCR-free approach eliminating the need for separate text recognition components, thus reducing complexity. To the best of our knowledge, DLaVA is the first approach to introduce answer localization within multimodal QA, marking a significant step forward in enhancing user trust and reducing the risk of AI hallucinations. Our contributions include enhancing interpretability and reliability by grounding responses in spatially annotated visual content, introducing answer localization in MLLMs, proposing a streamlined pipeline that combines an MLLM with a text detection module, and conducting comprehensive evaluations using both textual and spatial accuracy metrics, including Intersection over Union (IoU). Experimental results on standard datasets demonstrate that DLaVA achieves SOTA performance, significantly enhancing model transparency and reliability. Our approach sets a new benchmark for Document VQA, highlighting the critical importance of precise answer localization and model interpretability.
DocParseNet: Advanced Semantic Segmentation and OCR Embeddings for Efficient Scanned Document Annotation
Jun 25, 2024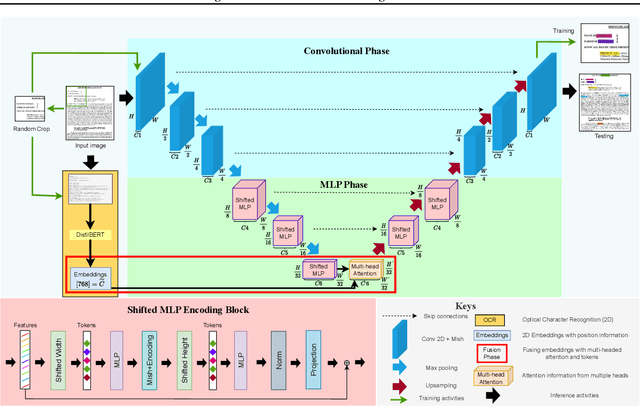

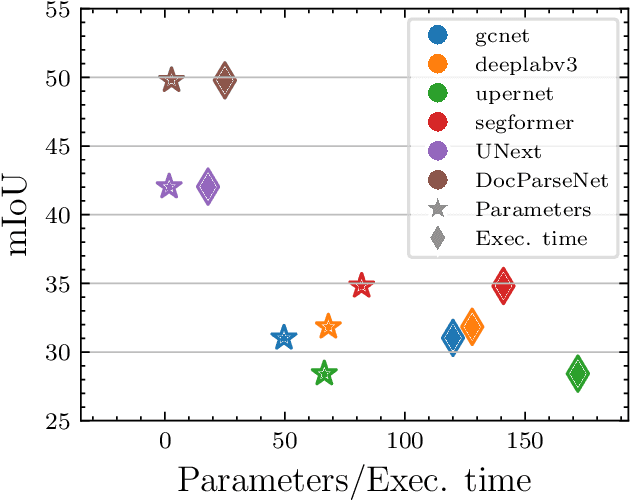
Automating the annotation of scanned documents is challenging, requiring a balance between computational efficiency and accuracy. DocParseNet addresses this by combining deep learning and multi-modal learning to process both text and visual data. This model goes beyond traditional OCR and semantic segmentation, capturing the interplay between text and images to preserve contextual nuances in complex document structures. Our evaluations show that DocParseNet significantly outperforms conventional models, achieving mIoU scores of 49.12 on validation and 49.78 on the test set. This reflects a 58% accuracy improvement over state-of-the-art baseline models and an 18% gain compared to the UNext baseline. Remarkably, DocParseNet achieves these results with only 2.8 million parameters, reducing the model size by approximately 25 times and speeding up training by 5 times compared to other models. These metrics, coupled with a computational efficiency of 0.034 TFLOPs (BS=1), highlight DocParseNet's high performance in document annotation. The model's adaptability and scalability make it well-suited for real-world corporate document processing applications. The code is available at https://github.com/ahmad-shirazi/DocParseNet
CrashFormer: A Multimodal Architecture to Predict the Risk of Crash
Feb 07, 2024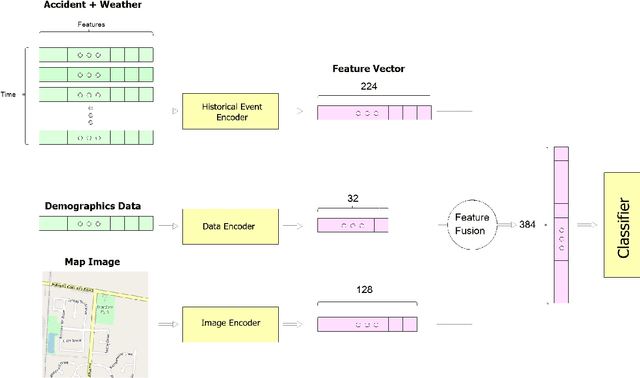

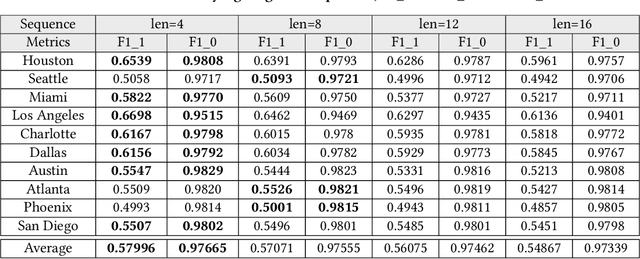
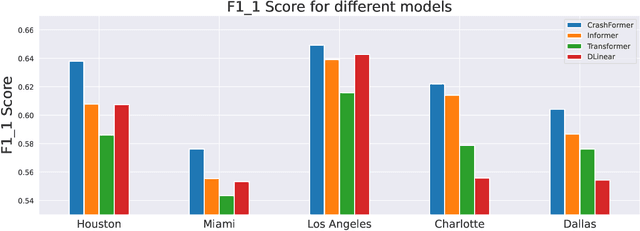
Reducing traffic accidents is a crucial global public safety concern. Accident prediction is key to improving traffic safety, enabling proactive measures to be taken before a crash occurs, and informing safety policies, regulations, and targeted interventions. Despite numerous studies on accident prediction over the past decades, many have limitations in terms of generalizability, reproducibility, or feasibility for practical use due to input data or problem formulation. To address existing shortcomings, we propose CrashFormer, a multi-modal architecture that utilizes comprehensive (but relatively easy to obtain) inputs such as the history of accidents, weather information, map images, and demographic information. The model predicts the future risk of accidents on a reasonably acceptable cadence (i.e., every six hours) for a geographical location of 5.161 square kilometers. CrashFormer is composed of five components: a sequential encoder to utilize historical accidents and weather data, an image encoder to use map imagery data, a raw data encoder to utilize demographic information, a feature fusion module for aggregating the encoded features, and a classifier that accepts the aggregated data and makes predictions accordingly. Results from extensive real-world experiments in 10 major US cities show that CrashFormer outperforms state-of-the-art sequential and non-sequential models by 1.8% in F1-score on average when using ``sparse'' input data.
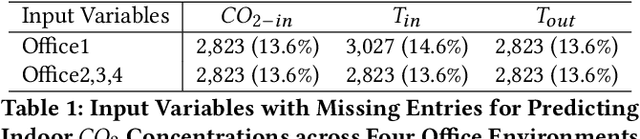
Novel Physics-Based Machine-Learning Models for Indoor Air Quality Approximations
Aug 02, 2023
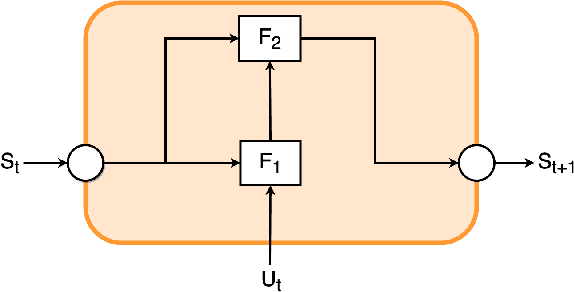
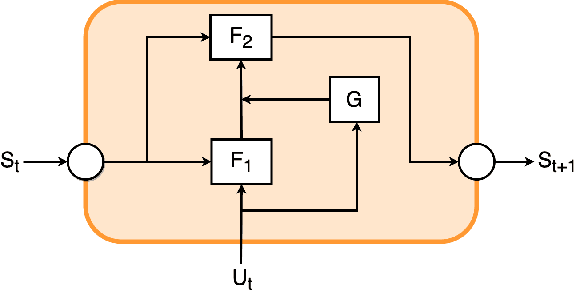
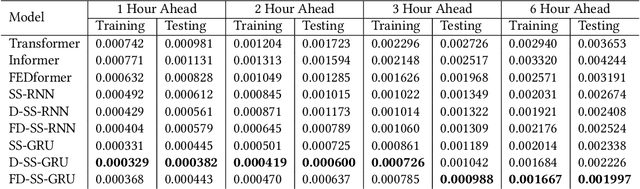
Cost-effective sensors are capable of real-time capturing a variety of air quality-related modalities from different pollutant concentrations to indoor/outdoor humidity and temperature. Machine learning (ML) models are capable of performing air-quality "ahead-of-time" approximations. Undoubtedly, accurate indoor air quality approximation significantly helps provide a healthy indoor environment, optimize associated energy consumption, and offer human comfort. However, it is crucial to design an ML architecture to capture the domain knowledge, so-called problem physics. In this study, we propose six novel physics-based ML models for accurate indoor pollutant concentration approximations. The proposed models include an adroit combination of state-space concepts in physics, Gated Recurrent Units, and Decomposition techniques. The proposed models were illustrated using data collected from five offices in a commercial building in California. The proposed models are shown to be less complex, computationally more efficient, and more accurate than similar state-of-the-art transformer-based models. The superiority of the proposed models is due to their relatively light architecture (computational efficiency) and, more importantly, their ability to capture the underlying highly nonlinear patterns embedded in the often contaminated sensor-collected indoor air quality temporal data.