 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxaAdapter: Vision Taxonomy Models are Key to Fine-grained Image Generation over the Tree of Life
Mar 27, 2026Accurately generating images across the Tree of Life is difficult: there are over 10M distinct species on Earth, many of which differ only by subtle visual traits. Despite the remarkable progress in text-to-image synthesis, existing models often fail to capture the fine-grained visual cues that define species identity, even when their outputs appear photo-realistic. To this end, we propose TaxaAdapter, a simple and lightweight approach that incorporates Vision Taxonomy Models (VTMs) such as BioCLIP to guide fine-grained species generation. Our method injects VTM embeddings into a frozen text-to-image diffusion model, improving species-level fidelity while preserving flexible text control over attributes such as pose, style, and background. Extensive experiments demonstrate that TaxaAdapter consistently improves morphology fidelity and species-identity accuracy over strong baselines, with a cleaner architecture and training recipe. To better evaluate these improvements, we also introduce a multimodal Large Language Model-based metric that summarizes trait-level descriptions from generated and real images, providing a more interpretable measure of morphological consistency. Beyond this, we observe that TaxaAdapter exhibits strong generalization capabilities, enabling species synthesis in challenging regimes such as few-shot species with only a handful of training images and even species unseen during training. Overall, our results highlight that VTMs are a key ingredient for scalable, fine-grained species generation.
DiReCT: Disentangled Regularization of Contrastive Trajectories for Physics-Refined Video Generation
Mar 26, 2026Flow-matching video generators produce temporally coherent, high-fidelity outputs yet routinely violate elementary physics because their reconstruction objectives penalize per-frame deviations without distinguishing physically consistent dynamics from impossible ones. Contrastive flow matching offers a principled remedy by pushing apart velocity-field trajectories of differing conditions, but we identify a fundamental obstacle in the text-conditioned video setting: semantic-physics entanglement. Because natural-language prompts couple scene content with physical behavior, naive negative sampling draws conditions whose velocity fields largely overlap with the positive sample's, causing the contrastive gradient to directly oppose the flow-matching objective. We formalize this gradient conflict, deriving a precise alignment condition that reveals when contrastive learning helps versus harms training. Guided by this analysis, we introduce DiReCT (Disentangled Regularization of Contrastive Trajectories), a lightweight post-training framework that decomposes the contrastive signal into two complementary scales: a macro-contrastive term that draws partition-exclusive negatives from semantically distant regions for interference-free global trajectory separation, and a micro-contrastive term that constructs hard negatives sharing full scene semantics with the positive sample but differing along a single, LLM-perturbed axis of physical behavior; spanning kinematics, forces, materials, interactions, and magnitudes. A velocity-space distributional regularizer helps to prevent catastrophic forgetting of pretrained visual quality. When applied to Wan 2.1-1.3B, our method improves the physical commonsense score on VideoPhy by 16.7% and 11.3% compared to the baseline and SFT, respectively, without increasing training time.
KnobGen: Controlling the Sophistication of Artwork in Sketch-Based Diffusion Models
Oct 02, 2024


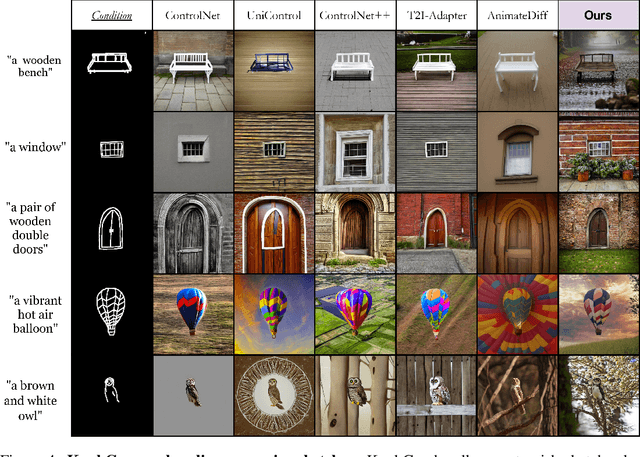
Recent advances in diffusion models have significantly improved text-to-image (T2I) generation, but they often struggle to balance fine-grained precision with high-level control. Methods like ControlNet and T2I-Adapter excel at following sketches by seasoned artists but tend to be overly rigid, replicating unintentional flaws in sketches from novice users. Meanwhile, coarse-grained methods, such as sketch-based abstraction frameworks, offer more accessible input handling but lack the precise control needed for detailed, professional use. To address these limitations, we propose KnobGen, a dual-pathway framework that democratizes sketch-based image generation by seamlessly adapting to varying levels of sketch complexity and user skill. KnobGen uses a Coarse-Grained Controller (CGC) module for high-level semantics and a Fine-Grained Controller (FGC) module for detailed refinement. The relative strength of these two modules can be adjusted through our knob inference mechanism to align with the user's specific needs. These mechanisms ensure that KnobGen can flexibly generate images from both novice sketches and those drawn by seasoned artists. This maintains control over the final output while preserving the natural appearance of the image, as evidenced on the MultiGen-20M dataset and a newly collected sketch dataset.
Frequency-Guided Masking for Enhanced Vision Self-Supervised Learning
Sep 16, 2024We present a novel frequency-based Self-Supervised Learning (SSL) approach that significantly enhances its efficacy for pre-training. Prior work in this direction masks out pre-defined frequencies in the input image and employs a reconstruction loss to pre-train the model. While achieving promising results, such an implementation has two fundamental limitations as identified in our paper. First, using pre-defined frequencies overlooks the variability of image frequency responses. Second, pre-trained with frequency-filtered images, the resulting model needs relatively more data to adapt to naturally looking images during fine-tuning. To address these drawbacks, we propose FOurier transform compression with seLf-Knowledge distillation (FOLK), integrating two dedicated ideas. First, inspired by image compression, we adaptively select the masked-out frequencies based on image frequency responses, creating more suitable SSL tasks for pre-training. Second, we employ a two-branch framework empowered by knowledge distillation, enabling the model to take both the filtered and original images as input, largely reducing the burden of downstream tasks. Our experimental results demonstrate the effectiveness of FOLK in achieving competitive performance to many state-of-the-art SSL methods across various downstream tasks, including image classification, few-shot learning, and semantic segmentation.
DetailCLIP: Detail-Oriented CLIP for Fine-Grained Tasks
Sep 10, 2024



In this paper, we introduce DetailCLIP: A Detail-Oriented CLIP to address the limitations of contrastive learning-based vision-language models, particularly CLIP, in handling detail-oriented and fine-grained tasks like segmentation. While CLIP and its variants excel in the global alignment of image and text representations, they often struggle to capture the fine-grained details necessary for precise segmentation. To overcome these challenges, we propose a novel framework that employs patch-level comparison of self-distillation and pixel-level reconstruction losses, enhanced with an attention-based token removal mechanism. This approach selectively retains semantically relevant tokens, enabling the model to focus on the image's critical regions aligned with the specific functions of our model, including textual information processing, patch comparison, and image reconstruction, ensuring that the model learns high-level semantics and detailed visual features. Our experiments demonstrate that DetailCLIP surpasses existing CLIP-based and traditional self-supervised learning (SSL) models in segmentation accuracy and exhibits superior generalization across diverse datasets. DetailCLIP represents a significant advancement in vision-language modeling, offering a robust solution for tasks that demand high-level semantic understanding and detailed feature extraction. https://github.com/KishoreP1/DetailCLIP.
Masked LoGoNet: Fast and Accurate 3D Image Analysis for Medical Domain
Feb 09, 2024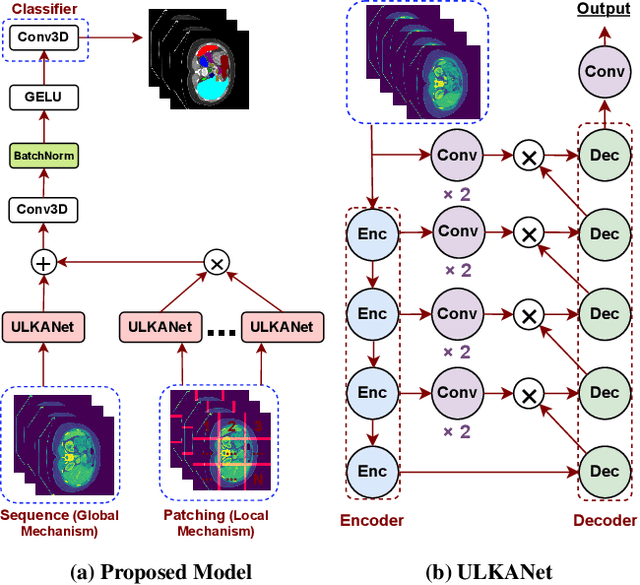
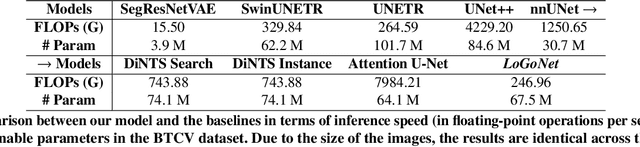
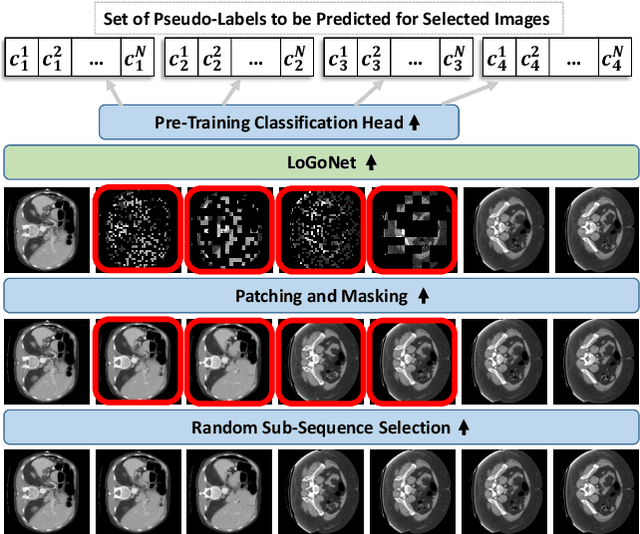
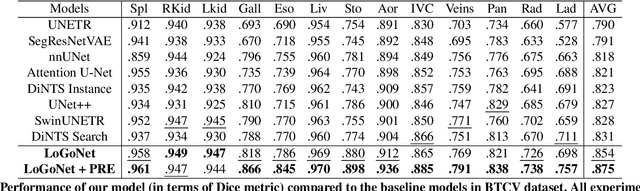
Standard modern machine-learning-based imaging methods have faced challenges in medical applications due to the high cost of dataset construction and, thereby, the limited labeled training data available. Additionally, upon deployment, these methods are usually used to process a large volume of data on a daily basis, imposing a high maintenance cost on medical facilities. In this paper, we introduce a new neural network architecture, termed LoGoNet, with a tailored self-supervised learning (SSL) method to mitigate such challenges. LoGoNet integrates a novel feature extractor within a U-shaped architecture, leveraging Large Kernel Attention (LKA) and a dual encoding strategy to capture both long-range and short-range feature dependencies adeptly. This is in contrast to existing methods that rely on increasing network capacity to enhance feature extraction. This combination of novel techniques in our model is especially beneficial in medical image segmentation, given the difficulty of learning intricate and often irregular body organ shapes, such as the spleen. Complementary, we propose a novel SSL method tailored for 3D images to compensate for the lack of large labeled datasets. The method combines masking and contrastive learning techniques within a multi-task learning framework and is compatible with both Vision Transformer (ViT) and CNN-based models. We demonstrate the efficacy of our methods in numerous tasks across two standard datasets (i.e., BTCV and MSD). Benchmark comparisons with eight state-of-the-art models highlight LoGoNet's superior performance in both inference time and accuracy.
CrashFormer: A Multimodal Architecture to Predict the Risk of Crash
Feb 07, 2024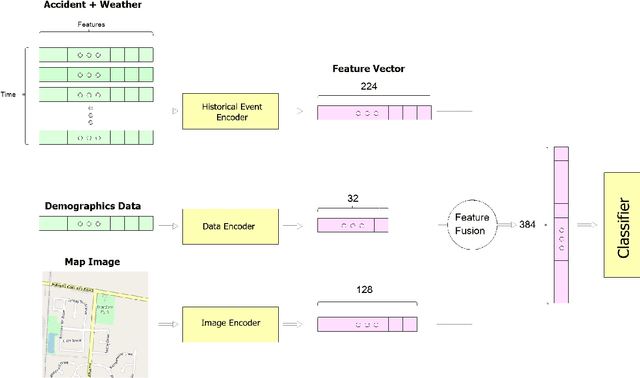

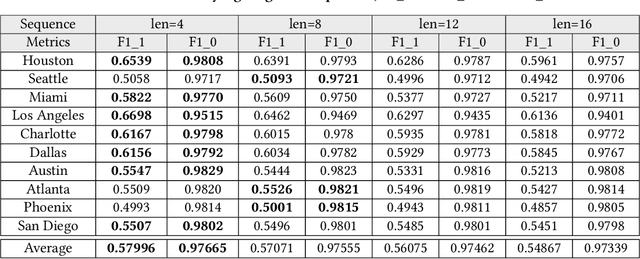
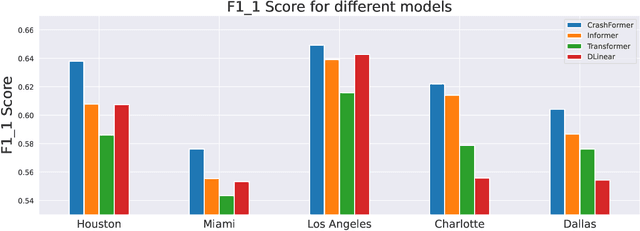
Reducing traffic accidents is a crucial global public safety concern. Accident prediction is key to improving traffic safety, enabling proactive measures to be taken before a crash occurs, and informing safety policies, regulations, and targeted interventions. Despite numerous studies on accident prediction over the past decades, many have limitations in terms of generalizability, reproducibility, or feasibility for practical use due to input data or problem formulation. To address existing shortcomings, we propose CrashFormer, a multi-modal architecture that utilizes comprehensive (but relatively easy to obtain) inputs such as the history of accidents, weather information, map images, and demographic information. The model predicts the future risk of accidents on a reasonably acceptable cadence (i.e., every six hours) for a geographical location of 5.161 square kilometers. CrashFormer is composed of five components: a sequential encoder to utilize historical accidents and weather data, an image encoder to use map imagery data, a raw data encoder to utilize demographic information, a feature fusion module for aggregating the encoded features, and a classifier that accepts the aggregated data and makes predictions accordingly. Results from extensive real-world experiments in 10 major US cities show that CrashFormer outperforms state-of-the-art sequential and non-sequential models by 1.8% in F1-score on average when using ``sparse'' input data.
Novel Physics-Based Machine-Learning Models for Indoor Air Quality Approximations
Aug 02, 2023
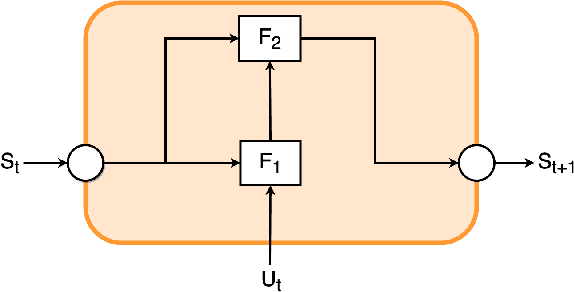
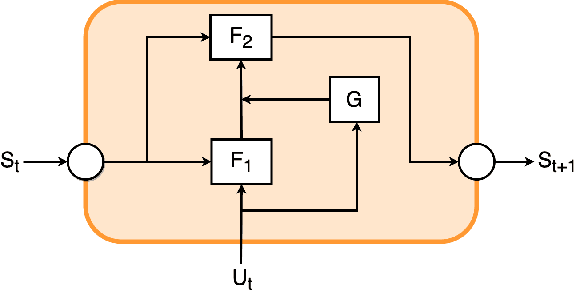
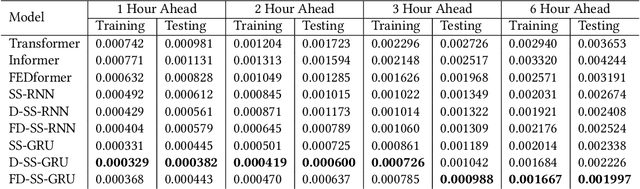
Cost-effective sensors are capable of real-time capturing a variety of air quality-related modalities from different pollutant concentrations to indoor/outdoor humidity and temperature. Machine learning (ML) models are capable of performing air-quality "ahead-of-time" approximations. Undoubtedly, accurate indoor air quality approximation significantly helps provide a healthy indoor environment, optimize associated energy consumption, and offer human comfort. However, it is crucial to design an ML architecture to capture the domain knowledge, so-called problem physics. In this study, we propose six novel physics-based ML models for accurate indoor pollutant concentration approximations. The proposed models include an adroit combination of state-space concepts in physics, Gated Recurrent Units, and Decomposition techniques. The proposed models were illustrated using data collected from five offices in a commercial building in California. The proposed models are shown to be less complex, computationally more efficient, and more accurate than similar state-of-the-art transformer-based models. The superiority of the proposed models is due to their relatively light architecture (computational efficiency) and, more importantly, their ability to capture the underlying highly nonlinear patterns embedded in the often contaminated sensor-collected indoor air quality temporal data.
Will there be a construction? Predicting road constructions based on heterogeneous spatiotemporal data
Sep 14, 2022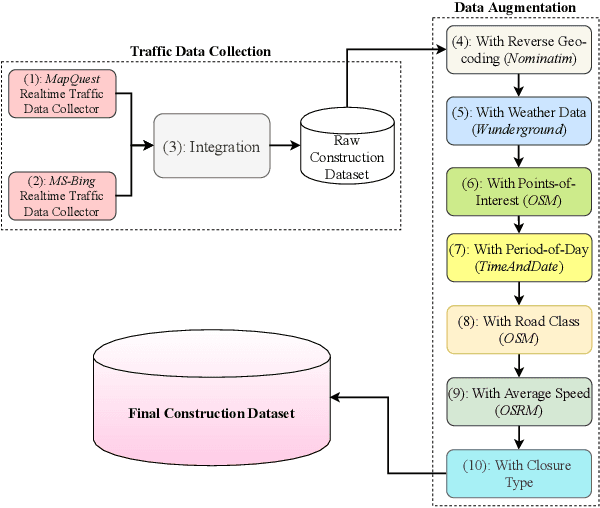
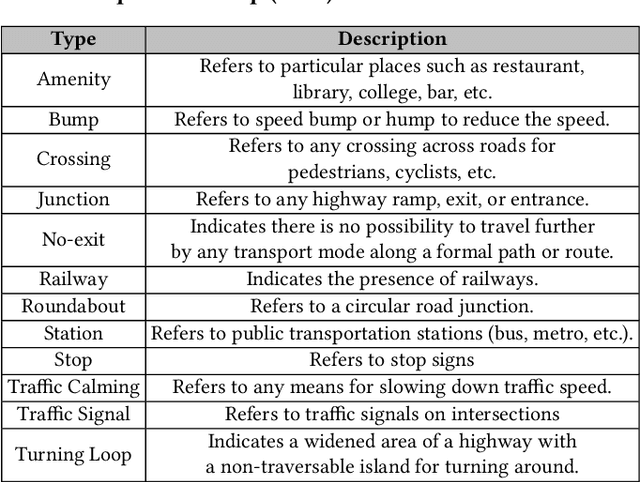
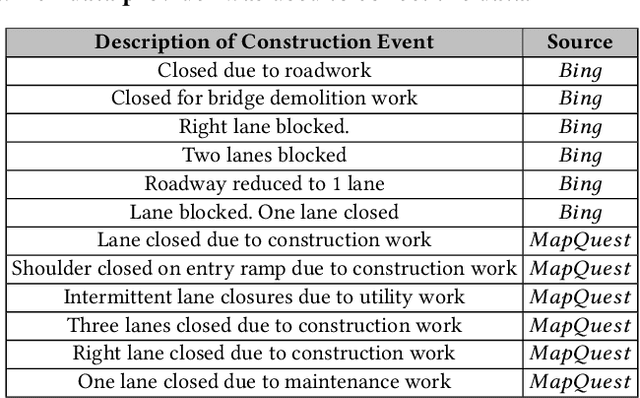
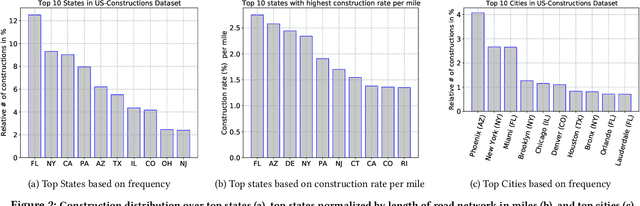
Road construction projects maintain transportation infrastructures. These projects range from the short-term (e.g., resurfacing or fixing potholes) to the long-term (e.g., adding a shoulder or building a bridge). Deciding what the next construction project is and when it is to be scheduled is traditionally done through inspection by humans using special equipment. This approach is costly and difficult to scale. An alternative is the use of computational approaches that integrate and analyze multiple types of past and present spatiotemporal data to predict location and time of future road constructions. This paper reports on such an approach, one that uses a deep-neural-network-based model to predict future constructions. Our model applies both convolutional and recurrent components on a heterogeneous dataset consisting of construction, weather, map and road-network data. We also report on how we addressed the lack of adequate publicly available data - by building a large scale dataset named "US-Constructions", that includes 6.2 million cases of road constructions augmented by a variety of spatiotemporal attributes and road-network features, collected in the contiguous United States (US) between 2016 and 2021. Using extensive experiments on several major cities in the US, we show the applicability of our work in accurately predicting future constructions - an average f1-score of 0.85 and accuracy 82.2% - that outperform baselines. Additionally, we show how our training pipeline addresses spatial sparsity of data.
Solving the Reaction-Diffusion equation based on analytical methods and deep learning algorithm; the Case study of sulfate attack to concrete
Dec 07, 2019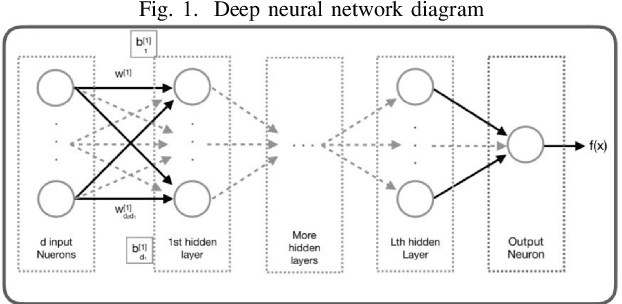
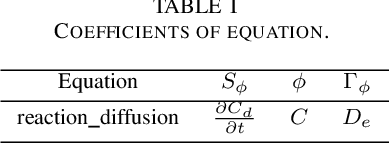

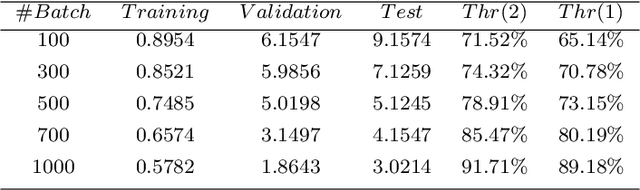
The reaction-diffusion equation is one of the cornerstones equations in applied science and engineering. In the present study, a deep neural network has been trained in order to predict the solution of the equation with different coefficients using the numerical solution of this equation and the utility of deep learning. Analytical solution of the Reaction-Diffusion equation also has been conducted by taking advantage of the Danckwerts method. The accuracy of deep learning results was compared with the analytical solutions. In order to decrease the learning time and to find out similar equations solutions, such as pure diffusion and pure reaction, dimensional analysis technique has been performed. It was demonstrated that deep learning can accurately estimate the Partial Differential Equations solutionin the case of the reaction-diffusion equation with a constant coefficient.