 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccident Impact Prediction based on a deep convolutional and recurrent neural network model
Nov 12, 2024



Traffic accidents pose a significant threat to public safety, resulting in numerous fatalities, injuries, and a substantial economic burden each year. The development of predictive models capable of real-time forecasting of post-accident impact using readily available data can play a crucial role in preventing adverse outcomes and enhancing overall safety. However, existing accident predictive models encounter two main challenges: first, reliance on either costly or non-real-time data, and second the absence of a comprehensive metric to measure post-accident impact accurately. To address these limitations, this study proposes a deep neural network model known as the cascade model. It leverages readily available real-world data from Los Angeles County to predict post-accident impacts. The model consists of two components: Long Short-Term Memory (LSTM) and Convolutional Neural Network (CNN). The LSTM model captures temporal patterns, while the CNN extracts patterns from the sparse accident dataset. Furthermore, an external traffic congestion dataset is incorporated to derive a new feature called the "accident impact" factor, which quantifies the influence of an accident on surrounding traffic flow. Extensive experiments were conducted to demonstrate the effectiveness of the proposed hybrid machine learning method in predicting the post-accident impact compared to state-of-the-art baselines. The results reveal a higher precision in predicting minimal impacts (i.e., cases with no reported accidents) and a higher recall in predicting more significant impacts (i.e., cases with reported accidents).
Recent Advances in Traffic Accident Analysis and Prediction: A Comprehensive Review of Machine Learning Techniques
Jun 20, 2024



Traffic accidents pose a severe global public health issue, leading to 1.19 million fatalities annually, with the greatest impact on individuals aged 5 to 29 years old. This paper addresses the critical need for advanced predictive methods in road safety by conducting a comprehensive review of recent advancements in applying machine learning (ML) techniques to traffic accident analysis and prediction. It examines 191 studies from the last five years, focusing on predicting accident risk, frequency, severity, duration, as well as general statistical analysis of accident data. To our knowledge, this study is the first to provide such a comprehensive review, covering the state-of-the-art across a wide range of domains related to accident analysis and prediction. The review highlights the effectiveness of integrating diverse data sources and advanced ML techniques to improve prediction accuracy and handle the complexities of traffic data. By mapping the current landscape and identifying gaps in the literature, this study aims to guide future research towards significantly reducing traffic-related deaths and injuries by 2030, aligning with the World Health Organization (WHO) targets.
CrashFormer: A Multimodal Architecture to Predict the Risk of Crash
Feb 07, 2024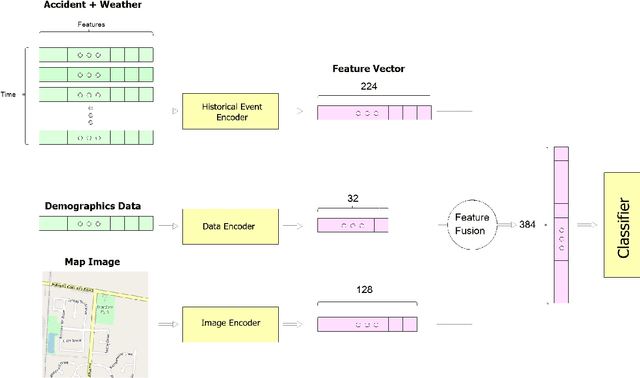

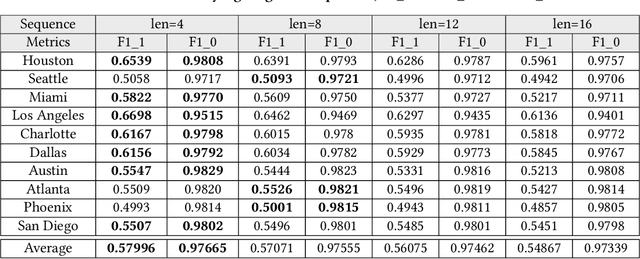
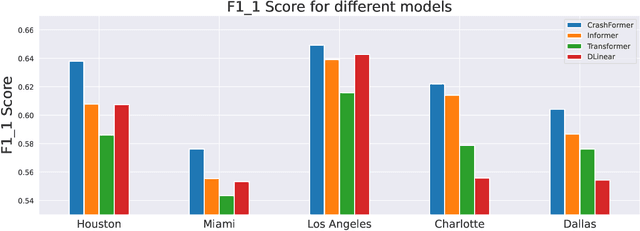
Reducing traffic accidents is a crucial global public safety concern. Accident prediction is key to improving traffic safety, enabling proactive measures to be taken before a crash occurs, and informing safety policies, regulations, and targeted interventions. Despite numerous studies on accident prediction over the past decades, many have limitations in terms of generalizability, reproducibility, or feasibility for practical use due to input data or problem formulation. To address existing shortcomings, we propose CrashFormer, a multi-modal architecture that utilizes comprehensive (but relatively easy to obtain) inputs such as the history of accidents, weather information, map images, and demographic information. The model predicts the future risk of accidents on a reasonably acceptable cadence (i.e., every six hours) for a geographical location of 5.161 square kilometers. CrashFormer is composed of five components: a sequential encoder to utilize historical accidents and weather data, an image encoder to use map imagery data, a raw data encoder to utilize demographic information, a feature fusion module for aggregating the encoded features, and a classifier that accepts the aggregated data and makes predictions accordingly. Results from extensive real-world experiments in 10 major US cities show that CrashFormer outperforms state-of-the-art sequential and non-sequential models by 1.8% in F1-score on average when using ``sparse'' input data.
Judge Me in Context: A Telematics-Based Driving Risk Prediction Framework in Presence of Weak Risk Labels
May 05, 2023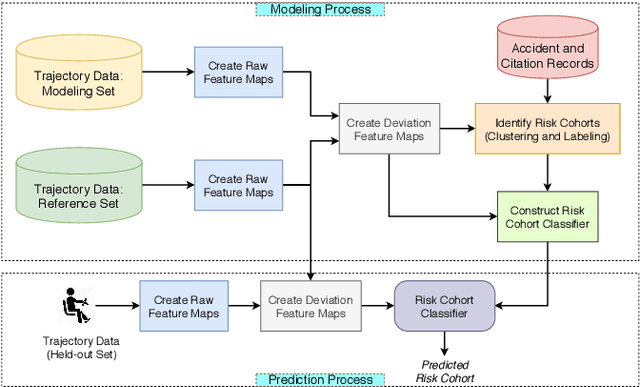



Driving risk prediction has been a topic of much research over the past few decades to minimize driving risk and increase safety. The use of demographic information in risk prediction is a traditional solution with applications in insurance planning, however, it is difficult to capture true driving behavior via such coarse-grained factors. Therefor, the use of telematics data has gained a widespread popularity over the past decade. While most of the existing studies leverage demographic information in addition to telematics data, our objective is to maximize the use of telematics as well as contextual information (e.g., road-type) to build a risk prediction framework with real-world applications. We contextualize telematics data in a variety of forms, and then use it to develop a risk classifier, assuming that there are some weak risk labels available (e.g., past traffic citation records). Before building a risk classifier though, we employ a novel data-driven process to augment weak risk labels. Extensive analysis and results based on real-world data from multiple major cities in the United States demonstrate usefulness of the proposed framework.
Will there be a construction? Predicting road constructions based on heterogeneous spatiotemporal data
Sep 14, 2022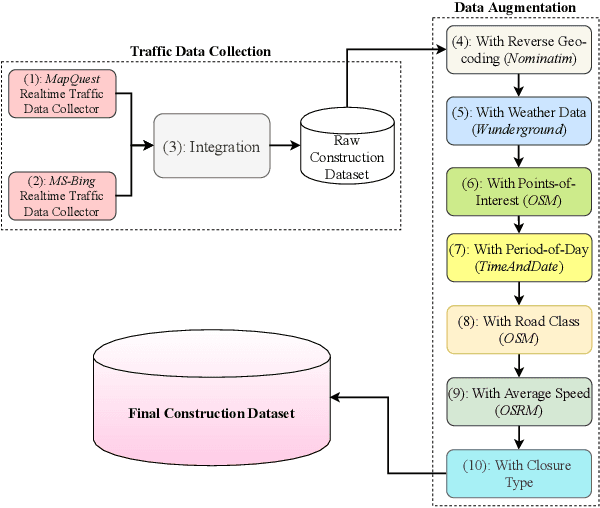
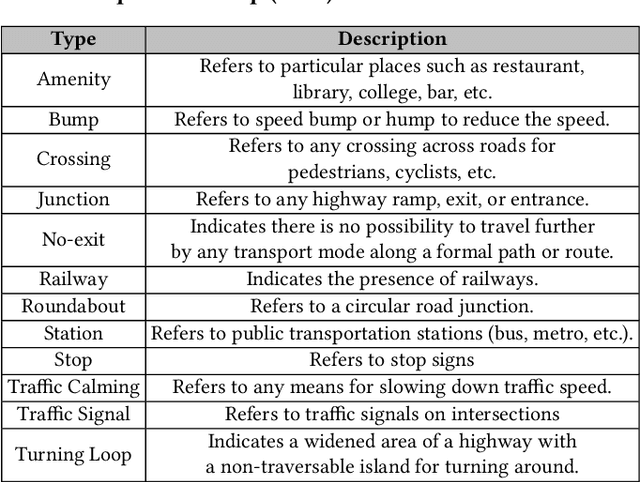
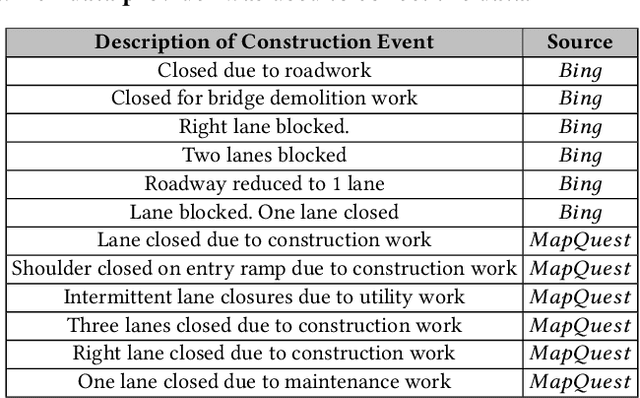
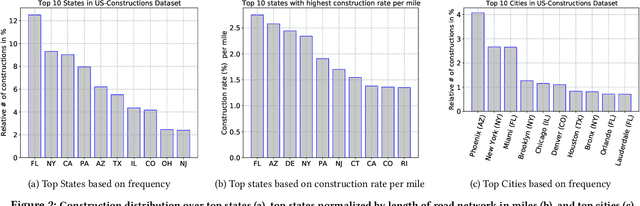
Road construction projects maintain transportation infrastructures. These projects range from the short-term (e.g., resurfacing or fixing potholes) to the long-term (e.g., adding a shoulder or building a bridge). Deciding what the next construction project is and when it is to be scheduled is traditionally done through inspection by humans using special equipment. This approach is costly and difficult to scale. An alternative is the use of computational approaches that integrate and analyze multiple types of past and present spatiotemporal data to predict location and time of future road constructions. This paper reports on such an approach, one that uses a deep-neural-network-based model to predict future constructions. Our model applies both convolutional and recurrent components on a heterogeneous dataset consisting of construction, weather, map and road-network data. We also report on how we addressed the lack of adequate publicly available data - by building a large scale dataset named "US-Constructions", that includes 6.2 million cases of road constructions augmented by a variety of spatiotemporal attributes and road-network features, collected in the contiguous United States (US) between 2016 and 2021. Using extensive experiments on several major cities in the US, we show the applicability of our work in accurately predicting future constructions - an average f1-score of 0.85 and accuracy 82.2% - that outperform baselines. Additionally, we show how our training pipeline addresses spatial sparsity of data.
Driving Style Representation in Convolutional Recurrent Neural Network Model of Driver Identification
Feb 11, 2021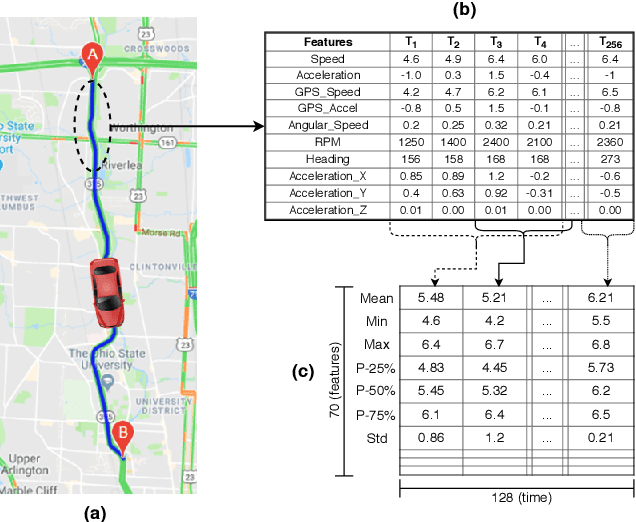
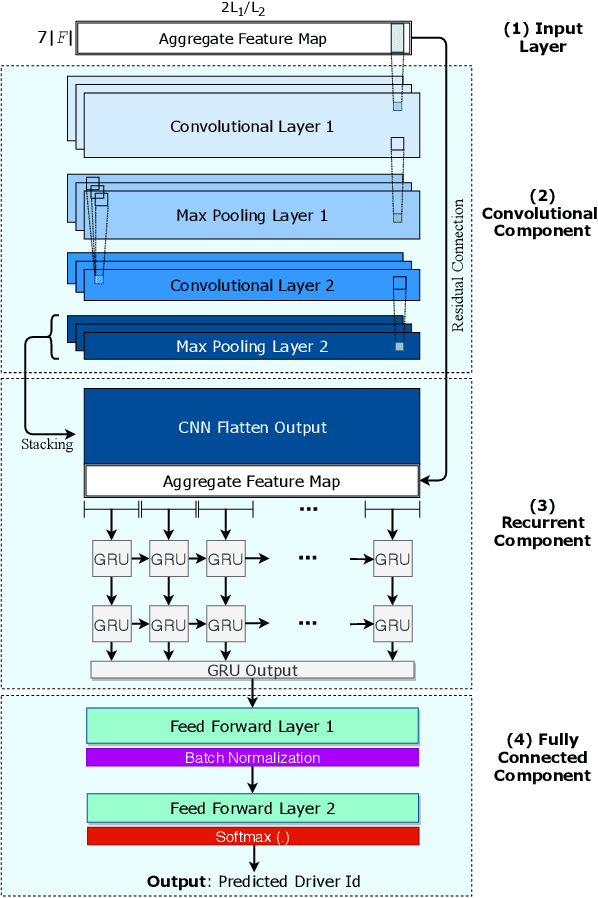
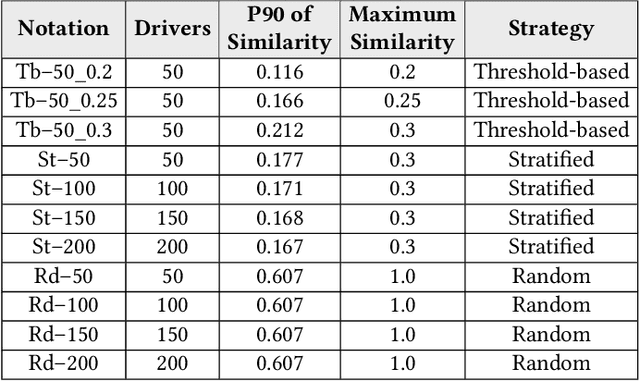
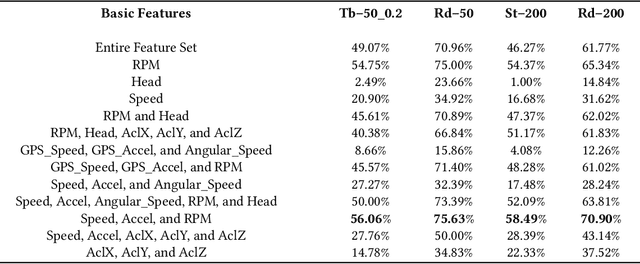
Identifying driving styles is the task of analyzing the behavior of drivers in order to capture variations that will serve to discriminate different drivers from each other. This task has become a prerequisite for a variety of applications, including usage-based insurance, driver coaching, driver action prediction, and even in designing autonomous vehicles; because driving style encodes essential information needed by these applications. In this paper, we present a deep-neural-network architecture, we term D-CRNN, for building high-fidelity representations for driving style, that combine the power of convolutional neural networks (CNN) and recurrent neural networks (RNN). Using CNN, we capture semantic patterns of driver behavior from trajectories (such as a turn or a braking event). We then find temporal dependencies between these semantic patterns using RNN to encode driving style. We demonstrate the effectiveness of these techniques for driver identification by learning driving style through extensive experiments conducted on several large, real-world datasets, and comparing the results with the state-of-the-art deep-learning and non-deep-learning solutions. These experiments also demonstrate a useful example of bias removal, by presenting how we preprocess the input data by sampling dissimilar trajectories for each driver to prevent spatial memorization. Finally, this paper presents an analysis of the contribution of different attributes for driver identification; we find that engine RPM, Speed, and Acceleration are the best combination of features.
Accident Risk Prediction based on Heterogeneous Sparse Data: New Dataset and Insights
Sep 19, 2019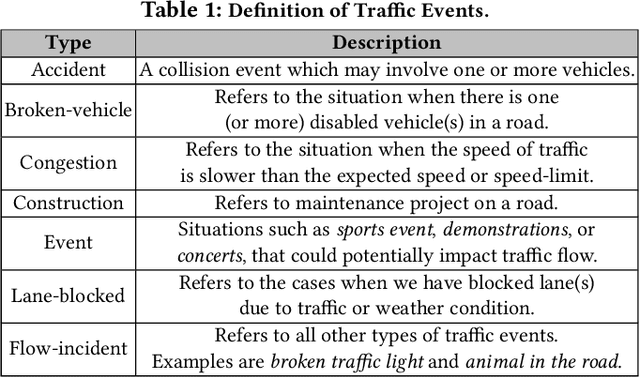
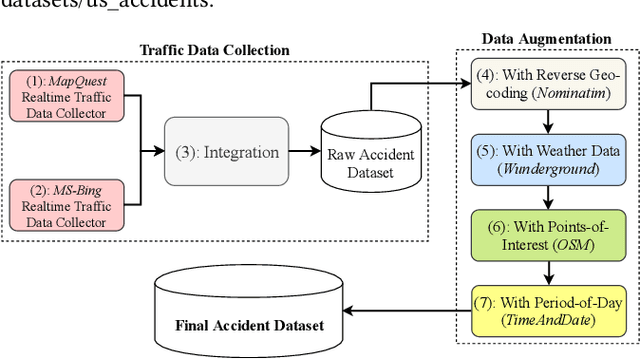
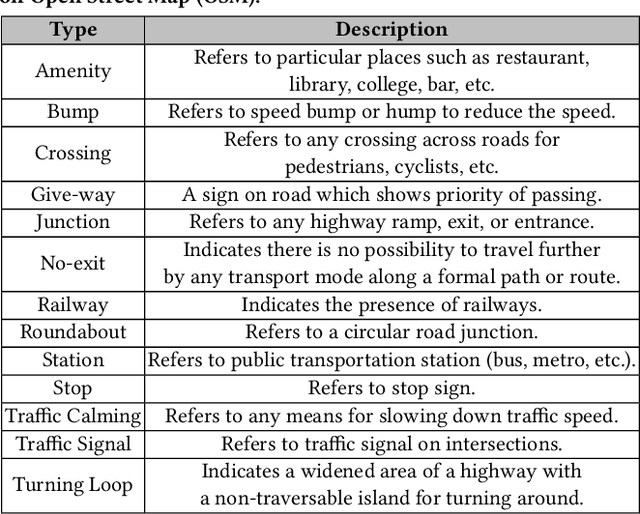
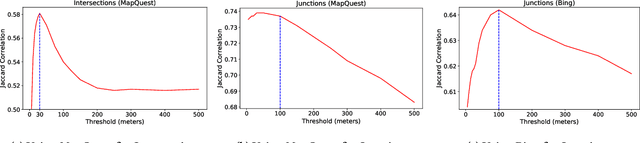
Reducing traffic accidents is an important public safety challenge, therefore, accident analysis and prediction has been a topic of much research over the past few decades. Using small-scale datasets with limited coverage, being dependent on extensive set of data, and being not applicable for real-time purposes are the important shortcomings of the existing studies. To address these challenges, we propose a new solution for real-time traffic accident prediction using easy-to-obtain, but sparse data. Our solution relies on a deep-neural-network model (which we have named DAP, for Deep Accident Prediction); which utilizes a variety of data attributes such as traffic events, weather data, points-of-interest, and time. DAP incorporates multiple components including a recurrent (for time-sensitive data), a fully connected (for time-insensitive data), and a trainable embedding component (to capture spatial heterogeneity). To fill the data gap, we have - through a comprehensive process of data collection, integration, and augmentation - created a large-scale publicly available database of accident information named US-Accidents. By employing the US-Accidents dataset and through an extensive set of experiments across several large cities, we have evaluated our proposal against several baselines. Our analysis and results show significant improvements to predict rare accident events. Further, we have shown the impact of traffic information, time, and points-of-interest data for real-time accident prediction.
Discovery of Driving Patterns by Trajectory Segmentation
Apr 23, 2018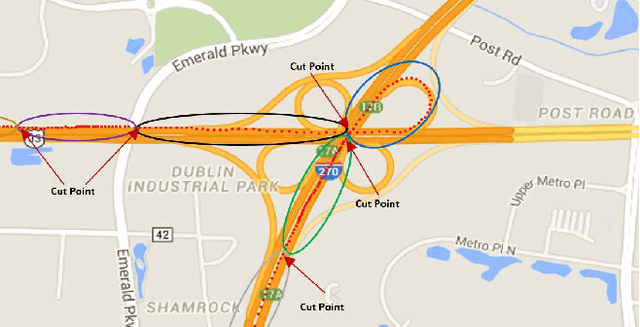
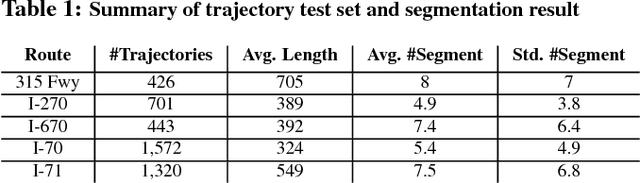
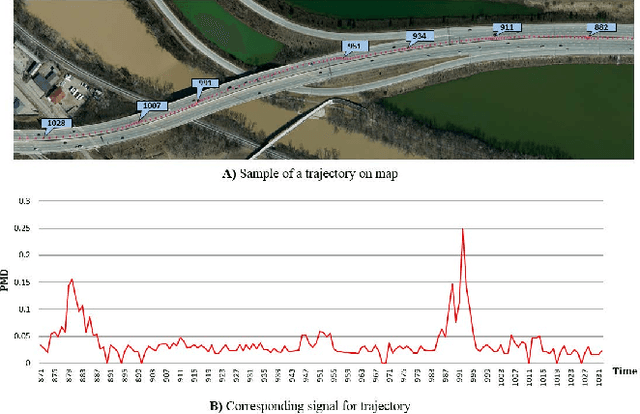
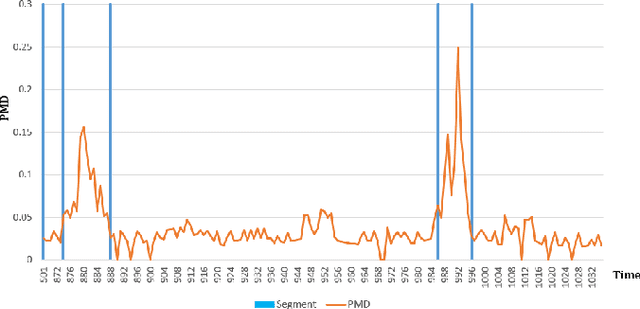
Telematics data is becoming increasingly available due to the ubiquity of devices that collect data during drives, for different purposes, such as usage based insurance (UBI), fleet management, navigation of connected vehicles, etc. Consequently, a variety of data-analytic applications have become feasible that extract valuable insights from the data. In this paper, we address the especially challenging problem of discovering behavior-based driving patterns from only externally observable phenomena (e.g. vehicle's speed). We present a trajectory segmentation approach capable of discovering driving patterns as separate segments, based on the behavior of drivers. This segmentation approach includes a novel transformation of trajectories along with a dynamic programming approach for segmentation. We apply the segmentation approach on a real-word, rich dataset of personal car trajectories provided by a major insurance company based in Columbus, Ohio. Analysis and preliminary results show the applicability of approach for finding significant driving patterns.
QDEE: Question Difficulty and Expertise Estimation in Community Question Answering Sites
Apr 20, 2018
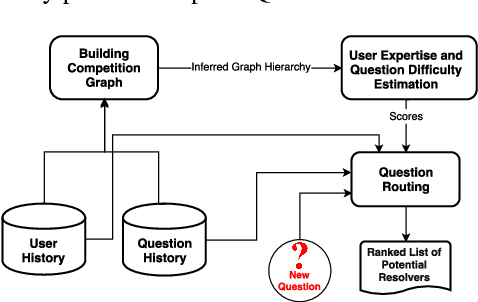
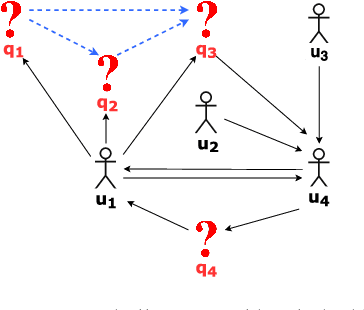
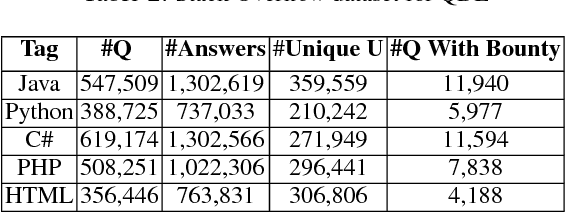
In this paper, we present a framework for Question Difficulty and Expertise Estimation (QDEE) in Community Question Answering sites (CQAs) such as Yahoo! Answers and Stack Overflow, which tackles a fundamental challenge in crowdsourcing: how to appropriately route and assign questions to users with the suitable expertise. This problem domain has been the subject of much research and includes both language-agnostic as well as language conscious solutions. We bring to bear a key language-agnostic insight: that users gain expertise and therefore tend to ask as well as answer more difficult questions over time. We use this insight within the popular competition (directed) graph model to estimate question difficulty and user expertise by identifying key hierarchical structure within said model. An important and novel contribution here is the application of "social agony" to this problem domain. Difficulty levels of newly posted questions (the cold-start problem) are estimated by using our QDEE framework and additional textual features. We also propose a model to route newly posted questions to appropriate users based on the difficulty level of the question and the expertise of the user. Extensive experiments on real world CQAs such as Yahoo! Answers and Stack Overflow data demonstrate the improved efficacy of our approach over contemporary state-of-the-art models. The QDEE framework also allows us to characterize user expertise in novel ways by identifying interesting patterns and roles played by different users in such CQAs.
Predicting protein-protein interactions based on rotation of proteins in 3D-space
Dec 22, 2017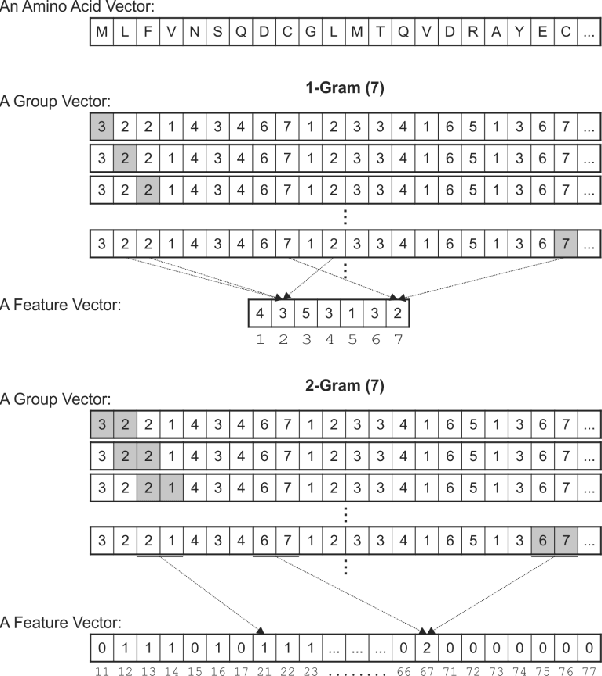
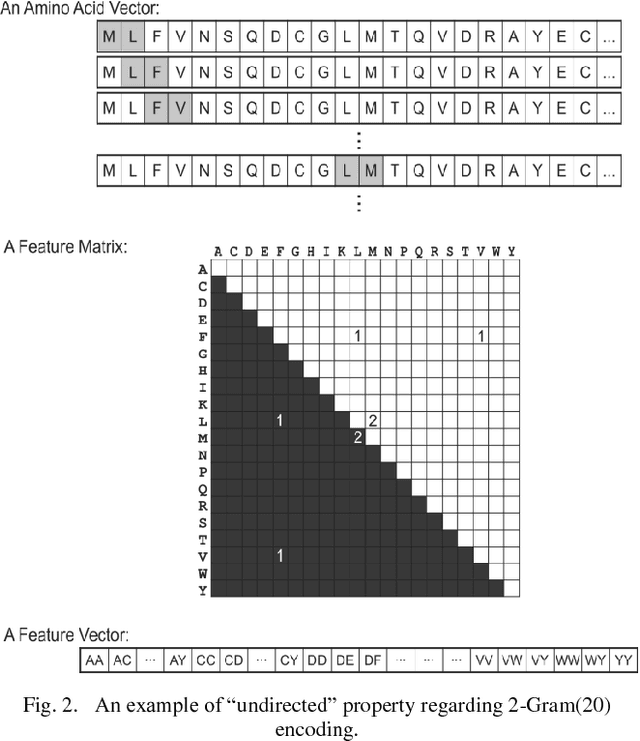
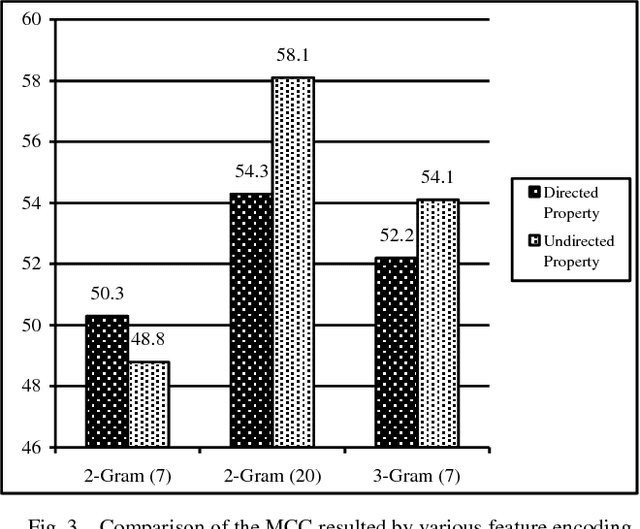
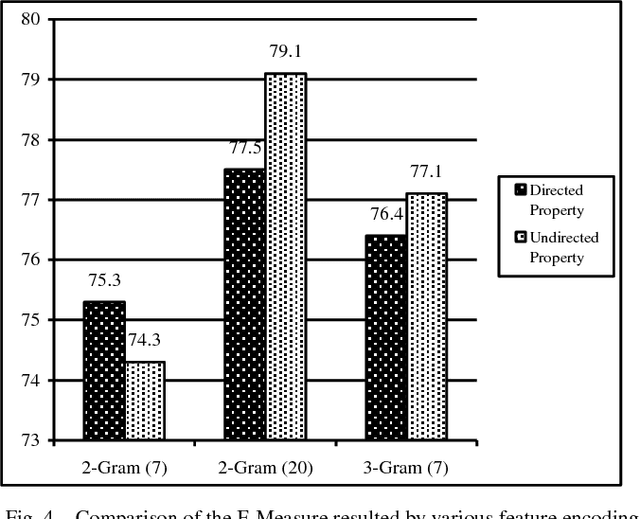
Protein-Protein Interactions (PPIs) perform essential roles in biological functions. Although some experimental techniques have been developed to detect PPIs, they suffer from high false positive and high false negative rates. Consequently, efforts have been devoted during recent years to develop computational approaches to predict the interactions utilizing various sources of information. Therefore, a unique category of prediction approaches has been devised which is based on the protein sequence information. However, finding an appropriate feature encoding to characterize the sequence of proteins is a major challenge in such methods. In presented work, a sequence based method is proposed to predict protein-protein interactions using N-Gram encoding approaches to describe amino acids and a Relaxed Variable Kernel Density Estimator (RVKDE) as a machine learning tool. Moreover, since proteins can rotate in 3D-space, amino acid compositions have been considered with "undirected" property which leads to reduce dimensions of the vector space. The results show that our proposed method achieves the superiority of prediction performance with improving an F-measure of 2.5% on Human Protein Reference Dataset (HPRD).