 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Aware Training of Layout-Aware Language Models
Mar 30, 2024



A visually rich document (VRD) utilizes visual features along with linguistic cues to disseminate information. Training a custom extractor that identifies named entities from a document requires a large number of instances of the target document type annotated at textual and visual modalities. This is an expensive bottleneck in enterprise scenarios, where we want to train custom extractors for thousands of different document types in a scalable way. Pre-training an extractor model on unlabeled instances of the target document type, followed by a fine-tuning step on human-labeled instances does not work in these scenarios, as it surpasses the maximum allowable training time allocated for the extractor. We address this scenario by proposing a Noise-Aware Training method or NAT in this paper. Instead of acquiring expensive human-labeled documents, NAT utilizes weakly labeled documents to train an extractor in a scalable way. To avoid degradation in the model's quality due to noisy, weakly labeled samples, NAT estimates the confidence of each training sample and incorporates it as uncertainty measure during training. We train multiple state-of-the-art extractor models using NAT. Experiments on a number of publicly available and in-house datasets show that NAT-trained models are not only robust in performance -- it outperforms a transfer-learning baseline by up to 6% in terms of macro-F1 score, but it is also more label-efficient -- it reduces the amount of human-effort required to obtain comparable performance by up to 73%.
Cross-Modal Entity Matching for Visually Rich Documents
Mar 01, 2023Visually rich documents (VRD) are physical/digital documents that utilize visual cues to augment their semantics. The information contained in these documents are often incomplete. Existing works that enable automated querying on VRDs do not take this aspect into account. Consequently, they support a limited set of queries. In this paper, we describe Juno -- a multimodal framework that identifies a set of tuples from a relational database to augment an incomplete VRD with supplementary information. Our main contribution in this is an end-to-end-trainable neural network with bi-directional attention that executes this cross-modal entity matching task without any prior knowledge about the document type or the underlying database-schema. Exhaustive experiments on two heteroegeneous datasets show that Juno outperforms state-of-the-art baselines by more than 6% in F1-score, while reducing the amount of human-effort in its workflow by more than 80%. To the best of our knowledge, ours is the first work that investigates the incompleteness of VRDs and proposes a robust framework to address it in a seamless way.
Transfer Learning for Abstractive Summarization at Controllable Budgets
Feb 18, 2020
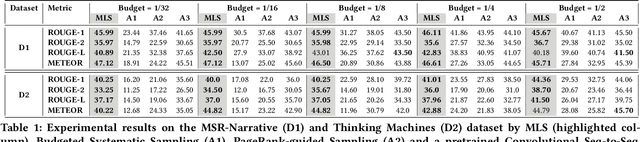
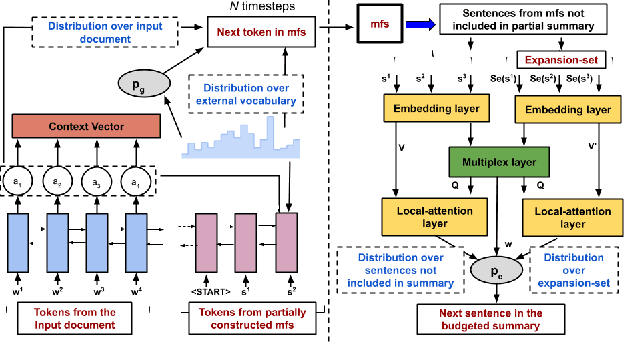
Summarizing a document within an allocated budget while maintaining its major concepts is a challenging task. If the budget can take any arbitrary value and not known beforehand, it becomes even more difficult. Most of the existing methods for abstractive summarization, including state-of-the-art neural networks are data intensive. If the number of available training samples becomes limited, they fail to construct high-quality summaries. We propose MLS, an end-to-end framework to generate abstractive summaries with limited training data at arbitrary compression budgets. MLS employs a pair of supervised sequence-to-sequence networks. The first network called the \textit{MFS-Net} constructs a minimal feasible summary by identifying the key concepts of the input document. The second network called the Pointer-Magnifier then generates the final summary from the minimal feasible summary by leveraging an interpretable multi-headed attention model. Experiments on two cross-domain datasets show that MLS outperforms baseline methods over a range of success metrics including ROUGE and METEOR. We observed an improvement of approximately 4% in both metrics over the state-of-art convolutional network at lower budgets. Results from a human evaluation study also establish the effectiveness of MLS in generating complete coherent summaries at arbitrary compression budgets.
Discovery of Driving Patterns by Trajectory Segmentation
Apr 23, 2018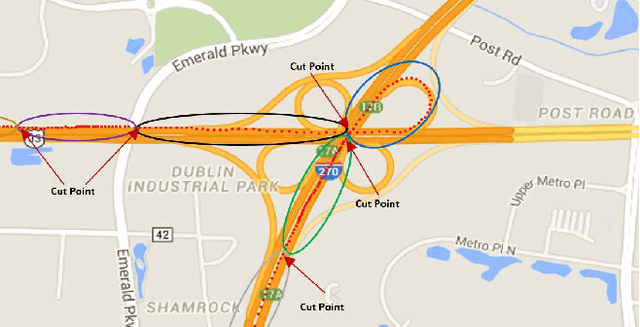
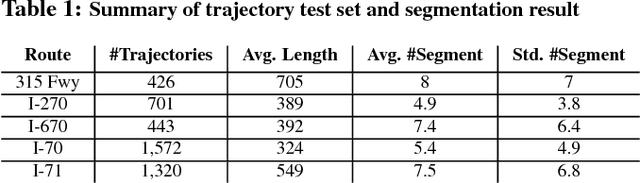
Telematics data is becoming increasingly available due to the ubiquity of devices that collect data during drives, for different purposes, such as usage based insurance (UBI), fleet management, navigation of connected vehicles, etc. Consequently, a variety of data-analytic applications have become feasible that extract valuable insights from the data. In this paper, we address the especially challenging problem of discovering behavior-based driving patterns from only externally observable phenomena (e.g. vehicle's speed). We present a trajectory segmentation approach capable of discovering driving patterns as separate segments, based on the behavior of drivers. This segmentation approach includes a novel transformation of trajectories along with a dynamic programming approach for segmentation. We apply the segmentation approach on a real-word, rich dataset of personal car trajectories provided by a major insurance company based in Columbus, Ohio. Analysis and preliminary results show the applicability of approach for finding significant driving patterns.
Characterizing Driving Context from Driver Behavior
Nov 17, 2017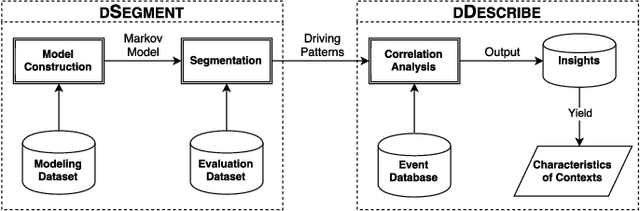
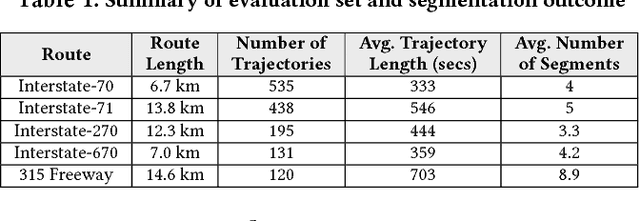
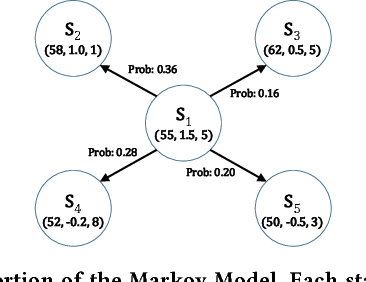
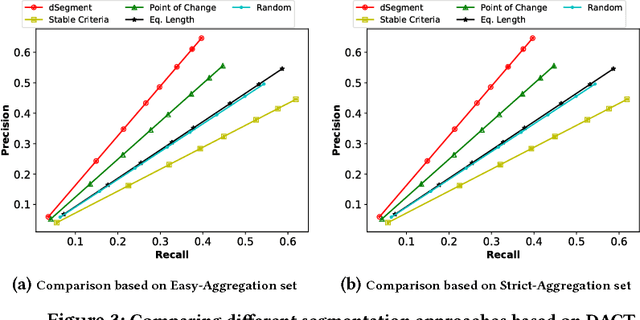
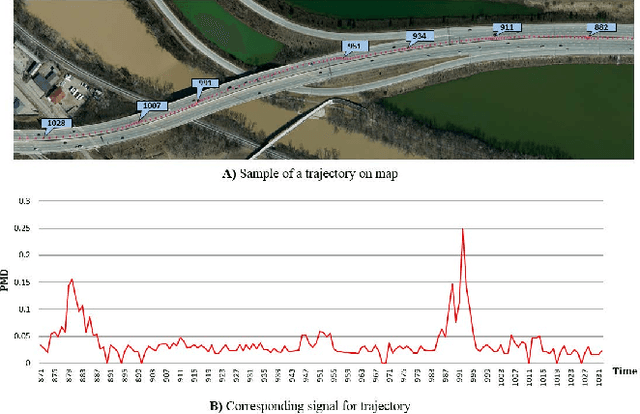
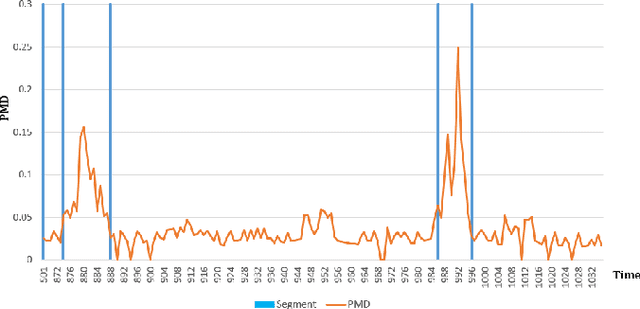
Because of the increasing availability of spatiotemporal data, a variety of data-analytic applications have become possible. Characterizing driving context, where context may be thought of as a combination of location and time, is a new challenging application. An example of such a characterization is finding the correlation between driving behavior and traffic conditions. This contextual information enables analysts to validate observation-based hypotheses about the driving of an individual. In this paper, we present DriveContext, a novel framework to find the characteristics of a context, by extracting significant driving patterns (e.g., a slow-down), and then identifying the set of potential causes behind patterns (e.g., traffic congestion). Our experimental results confirm the feasibility of the framework in identifying meaningful driving patterns, with improvements in comparison with the state-of-the-art. We also demonstrate how the framework derives interesting characteristics for different contexts, through real-world examples.