 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrashFormer: A Multimodal Architecture to Predict the Risk of Crash
Paper and Code
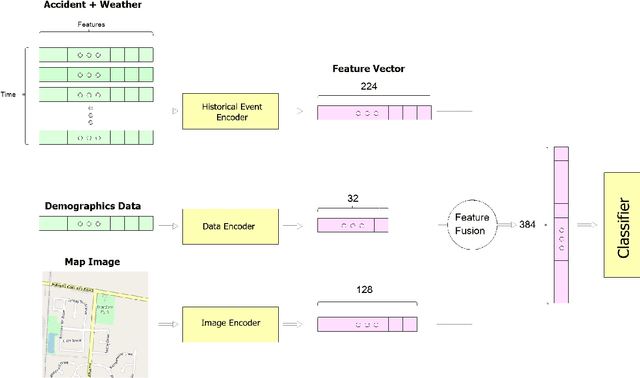

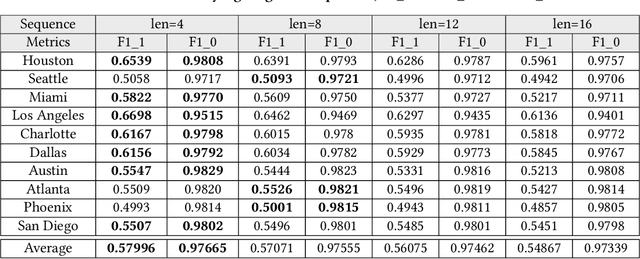
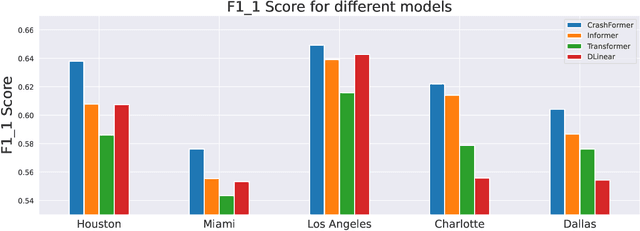
Reducing traffic accidents is a crucial global public safety concern. Accident prediction is key to improving traffic safety, enabling proactive measures to be taken before a crash occurs, and informing safety policies, regulations, and targeted interventions. Despite numerous studies on accident prediction over the past decades, many have limitations in terms of generalizability, reproducibility, or feasibility for practical use due to input data or problem formulation. To address existing shortcomings, we propose CrashFormer, a multi-modal architecture that utilizes comprehensive (but relatively easy to obtain) inputs such as the history of accidents, weather information, map images, and demographic information. The model predicts the future risk of accidents on a reasonably acceptable cadence (i.e., every six hours) for a geographical location of 5.161 square kilometers. CrashFormer is composed of five components: a sequential encoder to utilize historical accidents and weather data, an image encoder to use map imagery data, a raw data encoder to utilize demographic information, a feature fusion module for aggregating the encoded features, and a classifier that accepts the aggregated data and makes predictions accordingly. Results from extensive real-world experiments in 10 major US cities show that CrashFormer outperforms state-of-the-art sequential and non-sequential models by 1.8% in F1-score on average when using ``sparse'' input data.