 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLE-CapsNet: A Light and Enhanced Capsule Network
Nov 12, 2025



Capsule Network (CapsNet) classifier has several advantages over CNNs, including better detection of images containing overlapping categories and higher accuracy on transformed images. Despite the advantages, CapsNet is slow due to its different structure. In addition, CapsNet is resource-hungry, includes many parameters and lags in accuracy compared to CNNs. In this work, we propose LE-CapsNet as a light, enhanced and more accurate variant of CapsNet. Using 3.8M weights, LECapsNet obtains 76.73% accuracy on the CIFAR-10 dataset while performing inference 4x faster than CapsNet. In addition, our proposed network is more robust at detecting images with affine transformations compared to CapsNet. We achieve 94.3% accuracy on the AffNIST dataset (compared to CapsNet 90.52%).
Convolutional Fully-Connected Capsule Network (CFC-CapsNet): A Novel and Fast Capsule Network
Nov 06, 2025A Capsule Network (CapsNet) is a relatively new classifier and one of the possible successors of Convolutional Neural Networks (CNNs). CapsNet maintains the spatial hierarchies between the features and outperforms CNNs at classifying images including overlapping categories. Even though CapsNet works well on small-scale datasets such as MNIST, it fails to achieve a similar level of performance on more complicated datasets and real applications. In addition, CapsNet is slow compared to CNNs when performing the same task and relies on a higher number of parameters. In this work, we introduce Convolutional Fully-Connected Capsule Network (CFC-CapsNet) to address the shortcomings of CapsNet by creating capsules using a different method. We introduce a new layer (CFC layer) as an alternative solution to creating capsules. CFC-CapsNet produces fewer, yet more powerful capsules resulting in higher network accuracy. Our experiments show that CFC-CapsNet achieves competitive accuracy, faster training and inference and uses less number of parameters on the CIFAR-10, SVHN and Fashion-MNIST datasets compared to conventional CapsNet.
Generating Synthetic Contrast-Enhanced Chest CT Images from Non-Contrast Scans Using Slice-Consistent Brownian Bridge Diffusion Network
Aug 23, 2025

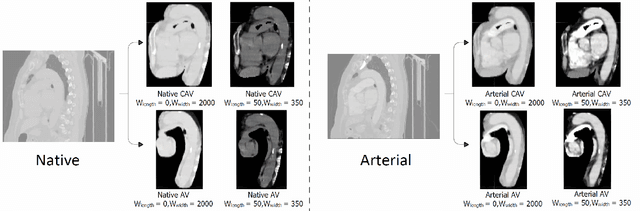
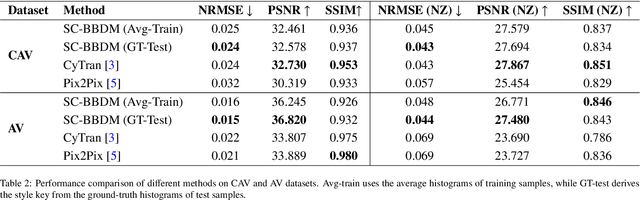
Contrast-enhanced computed tomography (CT) imaging is essential for diagnosing and monitoring thoracic diseases, including aortic pathologies. However, contrast agents pose risks such as nephrotoxicity and allergic-like reactions. The ability to generate high-fidelity synthetic contrast-enhanced CT angiography (CTA) images without contrast administration would be transformative, enhancing patient safety and accessibility while reducing healthcare costs. In this study, we propose the first bridge diffusion-based solution for synthesizing contrast-enhanced CTA images from non-contrast CT scans. Our approach builds on the Slice-Consistent Brownian Bridge Diffusion Model (SC-BBDM), leveraging its ability to model complex mappings while maintaining consistency across slices. Unlike conventional slice-wise synthesis methods, our framework preserves full 3D anatomical integrity while operating in a high-resolution 2D fashion, allowing seamless volumetric interpretation under a low memory budget. To ensure robust spatial alignment, we implement a comprehensive preprocessing pipeline that includes resampling, registration using the Symmetric Normalization method, and a sophisticated dilated segmentation mask to extract the aorta and surrounding structures. We create two datasets from the Coltea-Lung dataset: one containing only the aorta and another including both the aorta and heart, enabling a detailed analysis of anatomical context. We compare our approach against baseline methods on both datasets, demonstrating its effectiveness in preserving vascular structures while enhancing contrast fidelity.
CrashFormer: A Multimodal Architecture to Predict the Risk of Crash
Feb 07, 2024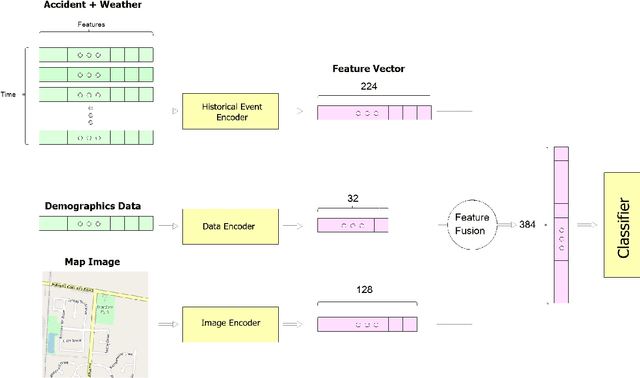

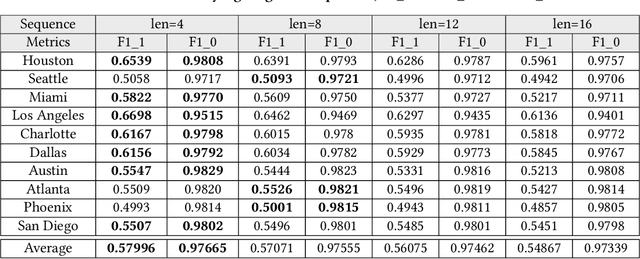
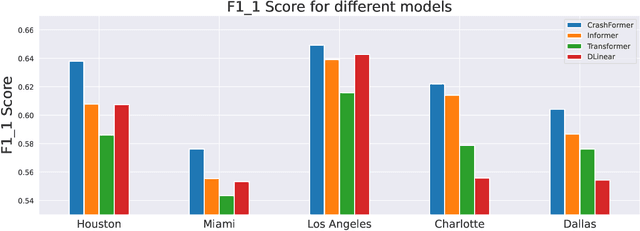
Reducing traffic accidents is a crucial global public safety concern. Accident prediction is key to improving traffic safety, enabling proactive measures to be taken before a crash occurs, and informing safety policies, regulations, and targeted interventions. Despite numerous studies on accident prediction over the past decades, many have limitations in terms of generalizability, reproducibility, or feasibility for practical use due to input data or problem formulation. To address existing shortcomings, we propose CrashFormer, a multi-modal architecture that utilizes comprehensive (but relatively easy to obtain) inputs such as the history of accidents, weather information, map images, and demographic information. The model predicts the future risk of accidents on a reasonably acceptable cadence (i.e., every six hours) for a geographical location of 5.161 square kilometers. CrashFormer is composed of five components: a sequential encoder to utilize historical accidents and weather data, an image encoder to use map imagery data, a raw data encoder to utilize demographic information, a feature fusion module for aggregating the encoded features, and a classifier that accepts the aggregated data and makes predictions accordingly. Results from extensive real-world experiments in 10 major US cities show that CrashFormer outperforms state-of-the-art sequential and non-sequential models by 1.8% in F1-score on average when using ``sparse'' input data.