 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Guided Masking for Enhanced Vision Self-Supervised Learning
Sep 16, 2024We present a novel frequency-based Self-Supervised Learning (SSL) approach that significantly enhances its efficacy for pre-training. Prior work in this direction masks out pre-defined frequencies in the input image and employs a reconstruction loss to pre-train the model. While achieving promising results, such an implementation has two fundamental limitations as identified in our paper. First, using pre-defined frequencies overlooks the variability of image frequency responses. Second, pre-trained with frequency-filtered images, the resulting model needs relatively more data to adapt to naturally looking images during fine-tuning. To address these drawbacks, we propose FOurier transform compression with seLf-Knowledge distillation (FOLK), integrating two dedicated ideas. First, inspired by image compression, we adaptively select the masked-out frequencies based on image frequency responses, creating more suitable SSL tasks for pre-training. Second, we employ a two-branch framework empowered by knowledge distillation, enabling the model to take both the filtered and original images as input, largely reducing the burden of downstream tasks. Our experimental results demonstrate the effectiveness of FOLK in achieving competitive performance to many state-of-the-art SSL methods across various downstream tasks, including image classification, few-shot learning, and semantic segmentation.
CrashFormer: A Multimodal Architecture to Predict the Risk of Crash
Feb 07, 2024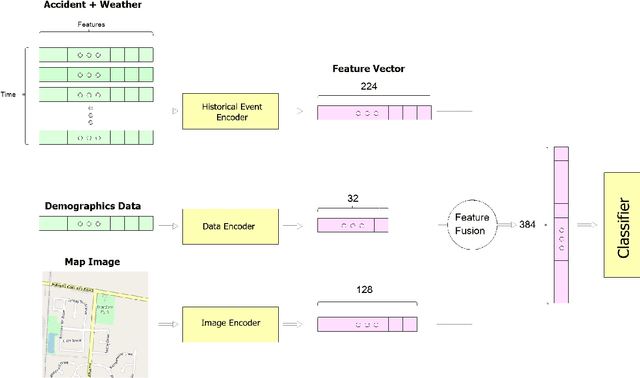

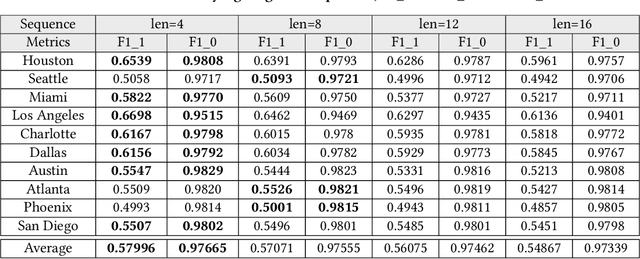
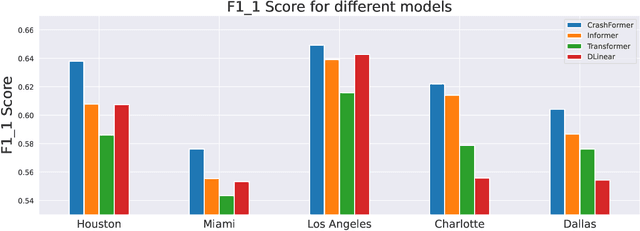
Reducing traffic accidents is a crucial global public safety concern. Accident prediction is key to improving traffic safety, enabling proactive measures to be taken before a crash occurs, and informing safety policies, regulations, and targeted interventions. Despite numerous studies on accident prediction over the past decades, many have limitations in terms of generalizability, reproducibility, or feasibility for practical use due to input data or problem formulation. To address existing shortcomings, we propose CrashFormer, a multi-modal architecture that utilizes comprehensive (but relatively easy to obtain) inputs such as the history of accidents, weather information, map images, and demographic information. The model predicts the future risk of accidents on a reasonably acceptable cadence (i.e., every six hours) for a geographical location of 5.161 square kilometers. CrashFormer is composed of five components: a sequential encoder to utilize historical accidents and weather data, an image encoder to use map imagery data, a raw data encoder to utilize demographic information, a feature fusion module for aggregating the encoded features, and a classifier that accepts the aggregated data and makes predictions accordingly. Results from extensive real-world experiments in 10 major US cities show that CrashFormer outperforms state-of-the-art sequential and non-sequential models by 1.8% in F1-score on average when using ``sparse'' input data.