 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnobGen: Controlling the Sophistication of Artwork in Sketch-Based Diffusion Models
Oct 02, 2024


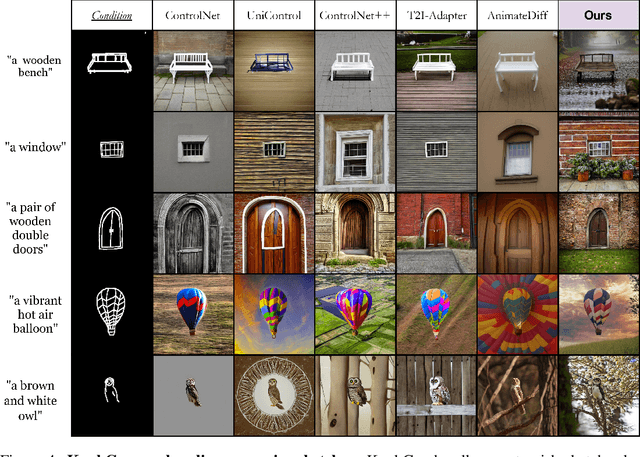
Recent advances in diffusion models have significantly improved text-to-image (T2I) generation, but they often struggle to balance fine-grained precision with high-level control. Methods like ControlNet and T2I-Adapter excel at following sketches by seasoned artists but tend to be overly rigid, replicating unintentional flaws in sketches from novice users. Meanwhile, coarse-grained methods, such as sketch-based abstraction frameworks, offer more accessible input handling but lack the precise control needed for detailed, professional use. To address these limitations, we propose KnobGen, a dual-pathway framework that democratizes sketch-based image generation by seamlessly adapting to varying levels of sketch complexity and user skill. KnobGen uses a Coarse-Grained Controller (CGC) module for high-level semantics and a Fine-Grained Controller (FGC) module for detailed refinement. The relative strength of these two modules can be adjusted through our knob inference mechanism to align with the user's specific needs. These mechanisms ensure that KnobGen can flexibly generate images from both novice sketches and those drawn by seasoned artists. This maintains control over the final output while preserving the natural appearance of the image, as evidenced on the MultiGen-20M dataset and a newly collected sketch dataset.
Frequency-Guided Masking for Enhanced Vision Self-Supervised Learning
Sep 16, 2024We present a novel frequency-based Self-Supervised Learning (SSL) approach that significantly enhances its efficacy for pre-training. Prior work in this direction masks out pre-defined frequencies in the input image and employs a reconstruction loss to pre-train the model. While achieving promising results, such an implementation has two fundamental limitations as identified in our paper. First, using pre-defined frequencies overlooks the variability of image frequency responses. Second, pre-trained with frequency-filtered images, the resulting model needs relatively more data to adapt to naturally looking images during fine-tuning. To address these drawbacks, we propose FOurier transform compression with seLf-Knowledge distillation (FOLK), integrating two dedicated ideas. First, inspired by image compression, we adaptively select the masked-out frequencies based on image frequency responses, creating more suitable SSL tasks for pre-training. Second, we employ a two-branch framework empowered by knowledge distillation, enabling the model to take both the filtered and original images as input, largely reducing the burden of downstream tasks. Our experimental results demonstrate the effectiveness of FOLK in achieving competitive performance to many state-of-the-art SSL methods across various downstream tasks, including image classification, few-shot learning, and semantic segmentation.
DocParseNet: Advanced Semantic Segmentation and OCR Embeddings for Efficient Scanned Document Annotation
Jun 25, 2024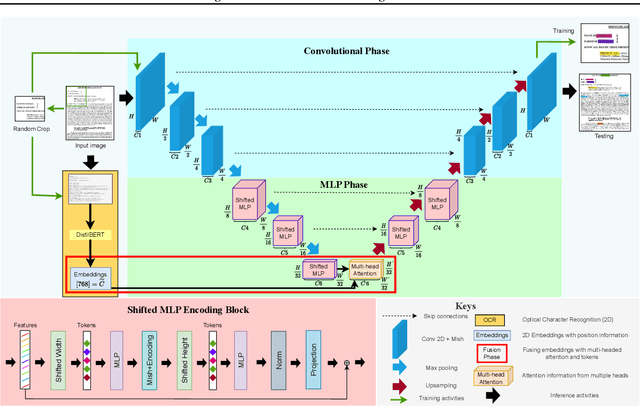

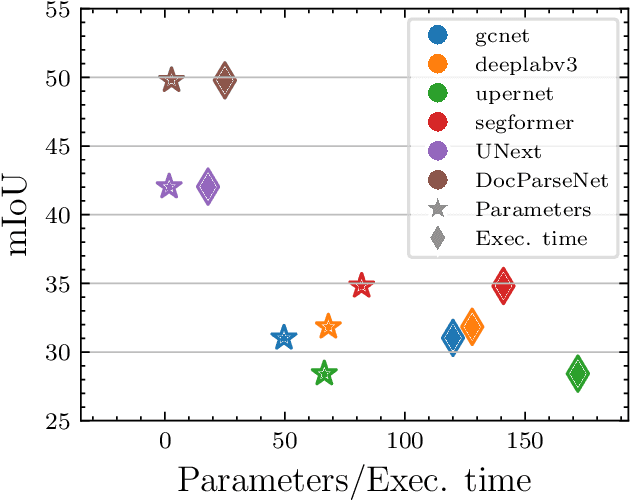
Automating the annotation of scanned documents is challenging, requiring a balance between computational efficiency and accuracy. DocParseNet addresses this by combining deep learning and multi-modal learning to process both text and visual data. This model goes beyond traditional OCR and semantic segmentation, capturing the interplay between text and images to preserve contextual nuances in complex document structures. Our evaluations show that DocParseNet significantly outperforms conventional models, achieving mIoU scores of 49.12 on validation and 49.78 on the test set. This reflects a 58% accuracy improvement over state-of-the-art baseline models and an 18% gain compared to the UNext baseline. Remarkably, DocParseNet achieves these results with only 2.8 million parameters, reducing the model size by approximately 25 times and speeding up training by 5 times compared to other models. These metrics, coupled with a computational efficiency of 0.034 TFLOPs (BS=1), highlight DocParseNet's high performance in document annotation. The model's adaptability and scalability make it well-suited for real-world corporate document processing applications. The code is available at https://github.com/ahmad-shirazi/DocParseNet
A First Step in Using Machine Learning Methods to Enhance Interaction Analysis for Embodied Learning Environments
May 10, 2024


Investigating children's embodied learning in mixed-reality environments, where they collaboratively simulate scientific processes, requires analyzing complex multimodal data to interpret their learning and coordination behaviors. Learning scientists have developed Interaction Analysis (IA) methodologies for analyzing such data, but this requires researchers to watch hours of videos to extract and interpret students' learning patterns. Our study aims to simplify researchers' tasks, using Machine Learning and Multimodal Learning Analytics to support the IA processes. Our study combines machine learning algorithms and multimodal analyses to support and streamline researcher efforts in developing a comprehensive understanding of students' scientific engagement through their movements, gaze, and affective responses in a simulated scenario. To facilitate an effective researcher-AI partnership, we present an initial case study to determine the feasibility of visually representing students' states, actions, gaze, affect, and movement on a timeline. Our case study focuses on a specific science scenario where students learn about photosynthesis. The timeline allows us to investigate the alignment of critical learning moments identified by multimodal and interaction analysis, and uncover insights into students' temporal learning progressions.
Masked LoGoNet: Fast and Accurate 3D Image Analysis for Medical Domain
Feb 09, 2024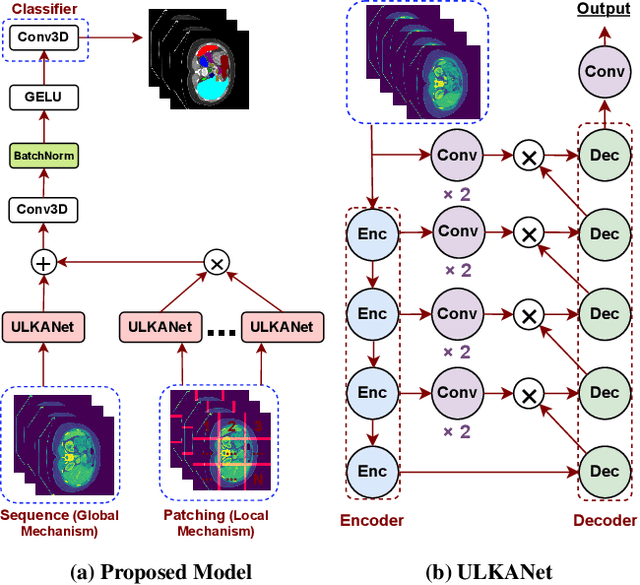
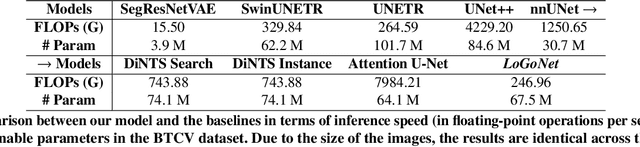
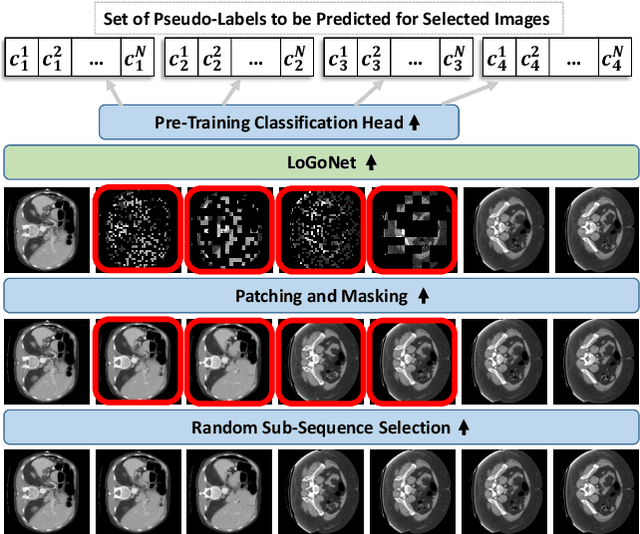
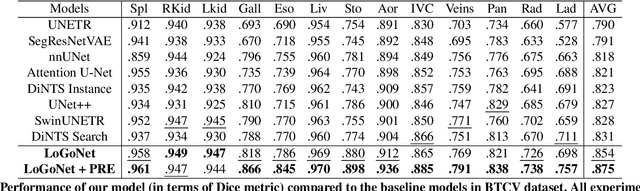
Standard modern machine-learning-based imaging methods have faced challenges in medical applications due to the high cost of dataset construction and, thereby, the limited labeled training data available. Additionally, upon deployment, these methods are usually used to process a large volume of data on a daily basis, imposing a high maintenance cost on medical facilities. In this paper, we introduce a new neural network architecture, termed LoGoNet, with a tailored self-supervised learning (SSL) method to mitigate such challenges. LoGoNet integrates a novel feature extractor within a U-shaped architecture, leveraging Large Kernel Attention (LKA) and a dual encoding strategy to capture both long-range and short-range feature dependencies adeptly. This is in contrast to existing methods that rely on increasing network capacity to enhance feature extraction. This combination of novel techniques in our model is especially beneficial in medical image segmentation, given the difficulty of learning intricate and often irregular body organ shapes, such as the spleen. Complementary, we propose a novel SSL method tailored for 3D images to compensate for the lack of large labeled datasets. The method combines masking and contrastive learning techniques within a multi-task learning framework and is compatible with both Vision Transformer (ViT) and CNN-based models. We demonstrate the efficacy of our methods in numerous tasks across two standard datasets (i.e., BTCV and MSD). Benchmark comparisons with eight state-of-the-art models highlight LoGoNet's superior performance in both inference time and accuracy.