 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnobGen: Controlling the Sophistication of Artwork in Sketch-Based Diffusion Models
Oct 02, 2024


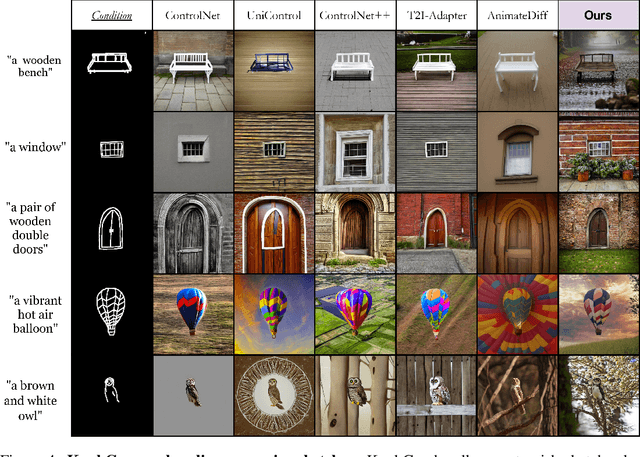
Recent advances in diffusion models have significantly improved text-to-image (T2I) generation, but they often struggle to balance fine-grained precision with high-level control. Methods like ControlNet and T2I-Adapter excel at following sketches by seasoned artists but tend to be overly rigid, replicating unintentional flaws in sketches from novice users. Meanwhile, coarse-grained methods, such as sketch-based abstraction frameworks, offer more accessible input handling but lack the precise control needed for detailed, professional use. To address these limitations, we propose KnobGen, a dual-pathway framework that democratizes sketch-based image generation by seamlessly adapting to varying levels of sketch complexity and user skill. KnobGen uses a Coarse-Grained Controller (CGC) module for high-level semantics and a Fine-Grained Controller (FGC) module for detailed refinement. The relative strength of these two modules can be adjusted through our knob inference mechanism to align with the user's specific needs. These mechanisms ensure that KnobGen can flexibly generate images from both novice sketches and those drawn by seasoned artists. This maintains control over the final output while preserving the natural appearance of the image, as evidenced on the MultiGen-20M dataset and a newly collected sketch dataset.
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
Apr 15, 2024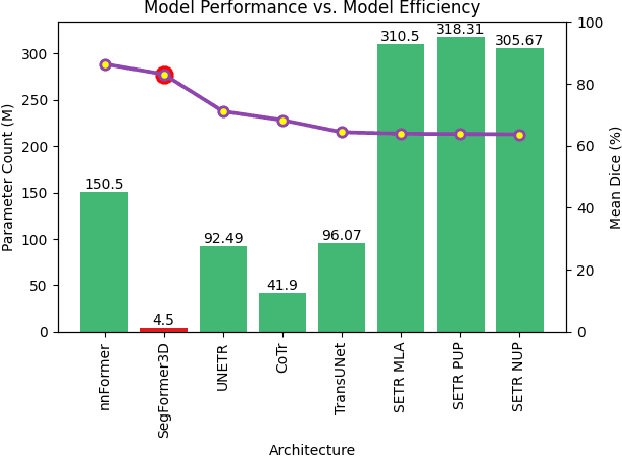
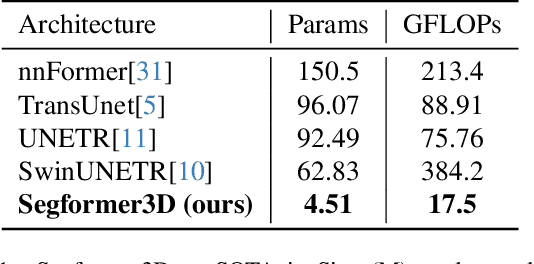
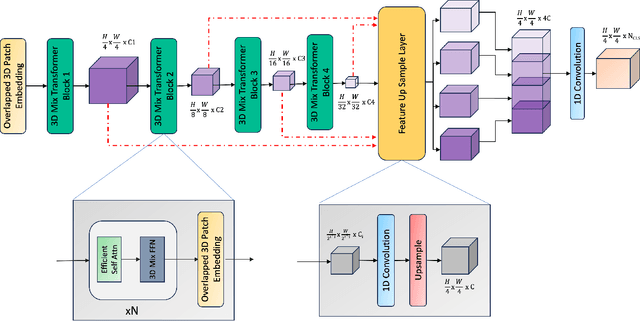
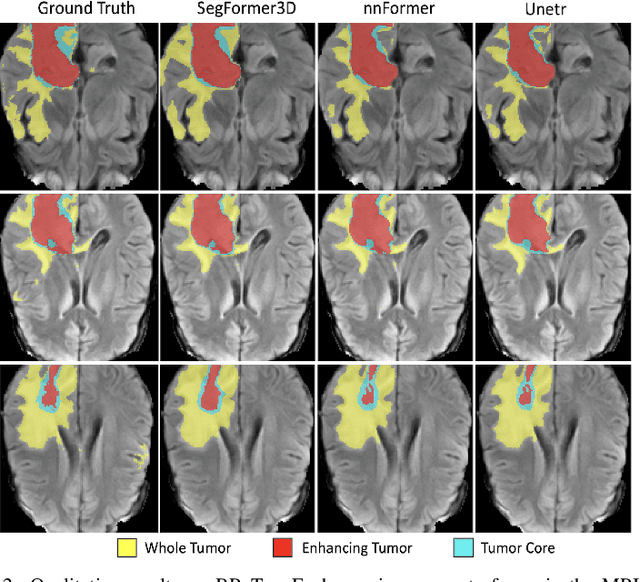
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
A Probabilistic-based Drift Correction Module for Visual Inertial SLAMs
Apr 15, 2024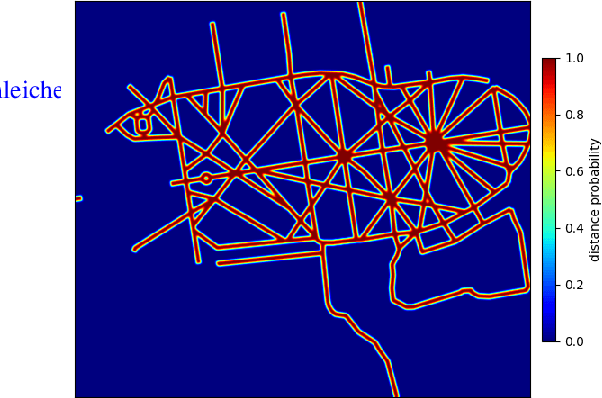

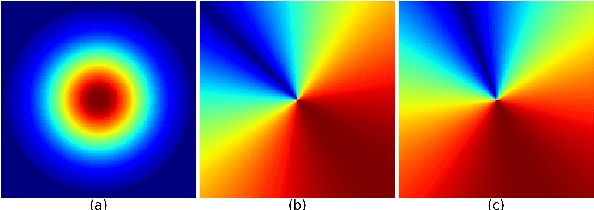
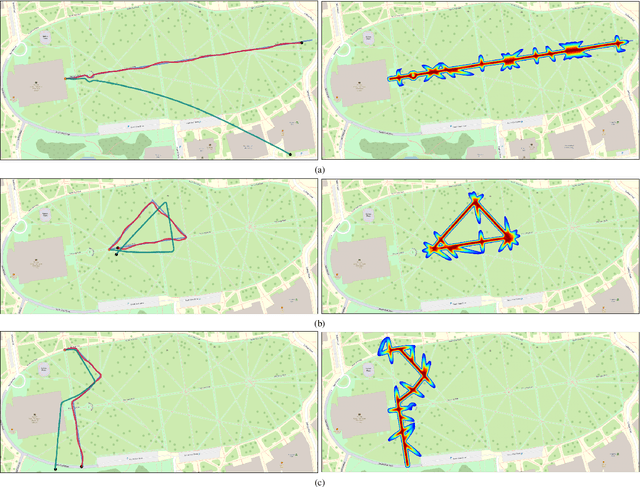
Positioning is a prominent field of study, notably focusing on Visual Inertial Odometry (VIO) and Simultaneous Localization and Mapping (SLAM) methods. Despite their advancements, these methods often encounter dead-reckoning errors that leads to considerable drift in estimated platform motion especially during long traverses. In such cases, the drift error is not negligible and should be rectified. Our proposed approach minimizes the drift error by correcting the estimated motion generated by any SLAM method at each epoch. Our methodology treats positioning measurements rendered by the SLAM solution as random variables formulated jointly in a multivariate distribution. In this setting, The correction of the drift becomes equivalent to finding the mode of this multivariate distribution which jointly maximizes the likelihood of a set of relevant geo-spatial priors about the platform motion and environment. Our method is integrable into any SLAM/VIO method as an correction module. Our experimental results shows the effectiveness of our approach in minimizing the drift error by 10x in long treverses.