 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Financial Data and News Articles for Stock Price Movement Prediction Using Large Language Models
Nov 02, 2024

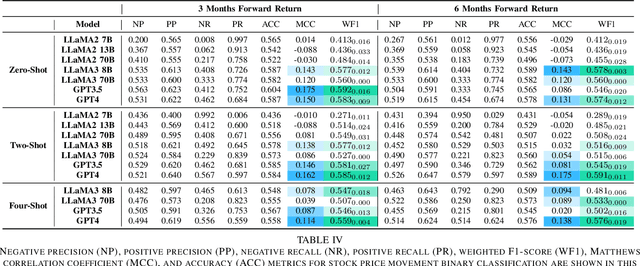
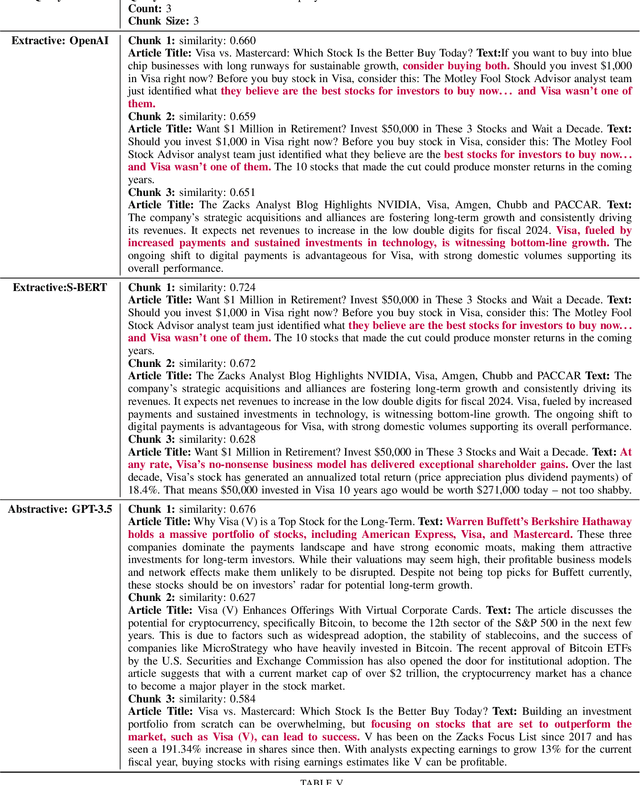
Predicting financial markets and stock price movements requires analyzing a company's performance, historic price movements, industry-specific events alongside the influence of human factors such as social media and press coverage. We assume that financial reports (such as income statements, balance sheets, and cash flow statements), historical price data, and recent news articles can collectively represent aforementioned factors. We combine financial data in tabular format with textual news articles and employ pre-trained Large Language Models (LLMs) to predict market movements. Recent research in LLMs has demonstrated that they are able to perform both tabular and text classification tasks, making them our primary model to classify the multi-modal data. We utilize retrieval augmentation techniques to retrieve and attach relevant chunks of news articles to financial metrics related to a company and prompt the LLMs in zero, two, and four-shot settings. Our dataset contains news articles collected from different sources, historic stock price, and financial report data for 20 companies with the highest trading volume across different industries in the stock market. We utilized recently released language models for our LLM-based classifier, including GPT- 3 and 4, and LLaMA- 2 and 3 models. We introduce an LLM-based classifier capable of performing classification tasks using combination of tabular (structured) and textual (unstructured) data. By using this model, we predicted the movement of a given stock's price in our dataset with a weighted F1-score of 58.5% and 59.1% and Matthews Correlation Coefficient of 0.175 for both 3-month and 6-month periods.
Online and Offline Evaluations of Collaborative Filtering and Content Based Recommender Systems
Nov 02, 2024Recommender systems are widely used AI applications designed to help users efficiently discover relevant items. The effectiveness of such systems is tied to the satisfaction of both users and providers. However, user satisfaction is complex and cannot be easily framed mathematically using information retrieval and accuracy metrics. While many studies evaluate accuracy through offline tests, a growing number of researchers argue that online evaluation methods such as A/B testing are better suited for this purpose. We have employed a variety of algorithms on different types of datasets divergent in size and subject, producing recommendations in various platforms, including media streaming services, digital publishing websites, e-commerce systems, and news broadcasting networks. Notably, our target websites and datasets are in Persian (Farsi) language. This study provides a comparative analysis of a large-scale recommender system that has been operating for the past year across about 70 websites in Iran, processing roughly 300 requests per second collectively. The system employs user-based and item-based recommendations using content-based, collaborative filtering, trend-based methods, and hybrid approaches. Through both offline and online evaluations, we aim to identify where these algorithms perform most efficiently and determine the best method for our specific needs, considering the dataset and system scale. Our methods of evaluation include manual evaluation, offline tests including accuracy and ranking metrics like hit-rate@k and nDCG, and online tests consisting of click-through rate (CTR). Additionally we analyzed and proposed methods to address cold-start and popularity bias.
Real-time Travel Time Estimation Using Matrix Factorization
Dec 01, 2019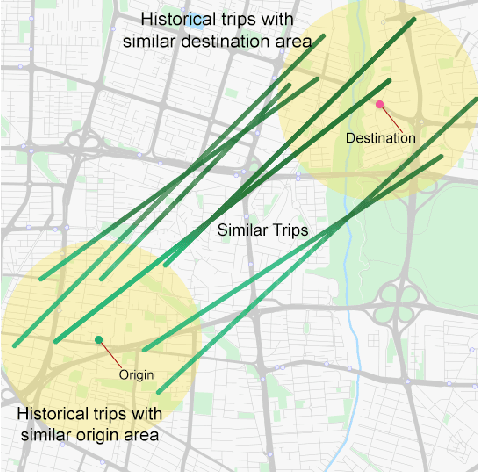
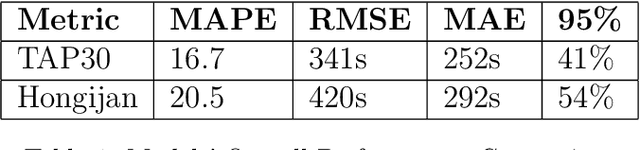
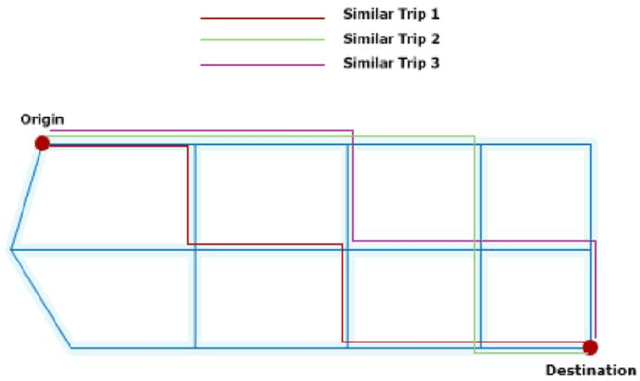
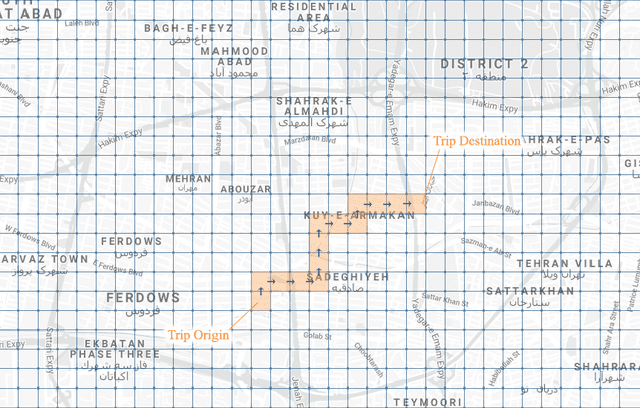
Estimating the travel time of any route is of great importance for trip planners, traffic operators, online taxi dispatching and ride-sharing platforms, and navigation provider systems. With the advance of technology, many traveling cars, including online taxi dispatch systems' vehicles are equipped with Global Positioning System (GPS) devices that can report the location of the vehicle every few seconds. This paper uses GPS data and the Matrix Factorization techniques to estimate the travel times on all road segments and time intervals simultaneously. We aggregate GPS data into a matrix, where each cell of the original matrix contains the average vehicle speed for a segment and a specific time interval. One of the problems with this matrix is its high sparsity. We use Alternating Least Squares (ALS) method along with a regularization term to factorize the matrix. Since this approach can solve the sparsity problem that arises from the absence of cars in many road segments in a specific time interval, matrix factorization is suitable for estimating the travel time. Our comprehensive evaluation results using real data provided by one of the largest online taxi dispatching systems in Iran, shows the strength of our proposed method.