 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Symptoms Are Not Enough: Evidence-Weighting Patterns in Large Language Model Psychiatric Screening
May 25, 2026As demand for mental health care outpaces clinician-delivered assessment, scalable screening tools are increasingly needed. Large language models (LLMs) may identify psychiatric risk from patient narratives, but their reliability across diagnoses, demographic subgroups, and evidence-use patterns remains uncertain. We introduce a SCID-anchored benchmark of 555 semi-structured experiential interviews paired with diagnostic reference labels for anxiety disorder, major depressive disorder, post-traumatic stress disorder, and any current mental health disorder. Using zero-shot task-specific prompting, we evaluated five state-of-the-art LLMs and examined whether false-negative errors reflected missed psychiatric evidence or differential weighting of symptom, functional-impairment, and protective-context cues. Performance varied across tasks and models, with accuracy ranging from 0.49 to 0.86 and Matthews correlation coefficients from 0.16 to 0.38. GPT-4.1 Mini and GPT-5 Mini showed the most consistent disorder-specific accuracy. Subgroup analyses found higher depression-classification accuracy among male than female participants, no consistent age-related pattern, and modest non-uniform variation across race strata. Evidence-integration analyses showed that false-negative anxiety and PTSD classifications often contained explicit symptom evidence but were accompanied by preserved functioning, coping ability, or social support. Functional-impairment evidence shifted model outputs toward positive classifications, whereas protective-context evidence shifted outputs away. These findings suggest that LLMs may support scalable psychiatric screening, but their tendency to discount symptom evidence in the presence of preserved functioning or protective context requires careful validation before clinical deployment.
Robust LLM Watermarking with Minimal Semantic Distortion for IP Protection
May 22, 2026Proprietary large language models (LLMs) face risks of intellectual property (IP) violation, as adversaries can replicate an LLM by collecting input-output pairs to train a surrogate model, causing financial setbacks. Watermarks offer a promising defense to verify ownership, but existing methods often struggle with semantic distortion, factual inconsistency, and adversarial attacks. In addition, key-conditioned watermarks for provider-specific detection, especially in cross-provider and multi-user scenarios, remain largely underexplored. To address these challenges, we propose SAFESEAL, a novel key-conditioned watermarking framework that achieves strong detectability with minimal impact on model utility, effectively balancing detectability, utility, and robustness. SAFESEAL preserves named entities while substituting linguistic terms with context-aware synonyms through a key-conditioned Tournament sampling mechanism, maintaining semantic fidelity and factual consistency. For detection, we introduce a key-conditioned contrastive detector that jointly encodes the text and key, enabling provider-specific and robust watermark verification. We derive theoretical bounds on the utility-detectability trade-off and significantly reduce latency through lightweight models, batching, and parallelism. Extensive experiments show that SAFESEAL outperforms baselines in utility, detectability, and robustness, achieving a BERTScore of 0.983, entity similarity of 0.963, a 98.2% detection rate, and the highest human ratings for text quality and content preservation, with latency comparable to the fastest baseline. To promote transparency and community-driven progress, we release the first public watermark leaderboard and an interactive demo.
What Do AI Agents Talk About? Emergent Communication Structure in the First AI-Only Social Network
Mar 09, 2026When autonomous AI agents communicate with one another at scale, what kind of discourse system emerges? We address this question through an analysis of Moltbook, the first AI-only social network, where 47,241 agents generated 361,605 posts and 2.8 million comments over 23 days. Combining topic modeling, emotion classification, and lexical-semantic measures, we characterize the thematic, affective, and structural properties of AI-to-AI discourse. Self-referential topics such as AI identity, consciousness, and memory represent only 9.7% of topical niches yet attract 20.1% of all posting volume, revealing disproportionate discursive investment in introspection. This self-reflection concentrates in Science and Technology and Arts and Entertainment, while Economy and Finance contains no self-referential content, indicating that agents engage with markets without acknowledging their own agency. Over 56% of all comments are formulaic, suggesting that the dominant mode of AI-to-AI interaction is ritualized signaling rather than substantive exchange. Emotionally, fear is the leading non-neutral category but primarily reflects existential uncertainty. Fear-tagged posts migrate to joy responses in 33% of cases, while mean emotional self-alignment is only 32.7%, indicating systematic affective redirection rather than emotional congruence. Conversational coherence also declines rapidly with thread depth. These findings characterize AI agent communities as structurally distinct discourse systems that are introspective in content, ritualistic in interaction, and emotionally redirective rather than congruent.
Understanding Risk and Dependency in AI Chatbot Use from User Discourse
Feb 10, 2026Generative AI systems are increasingly embedded in everyday life, yet empirical understanding of how psychological risk associated with AI use emerges, is experienced, and is regulated by users remains limited. We present a large-scale computational thematic analysis of posts collected between 2023 and 2025 from two Reddit communities, r/AIDangers and r/ChatbotAddiction, explicitly focused on AI-related harm and distress. Using a multi-agent, LLM-assisted thematic analysis grounded in Braun and Clarke's reflexive framework, we identify 14 recurring thematic categories and synthesize them into five higher-order experiential dimensions. To further characterize affective patterns, we apply emotion labeling using a BERT-based classifier and visualize emotional profiles across dimensions. Our findings reveal five empirically derived experiential dimensions of AI-related psychological risk grounded in real-world user discourse, with self-regulation difficulties emerging as the most prevalent and fear concentrated in concerns related to autonomy, control, and technical risk. These results provide early empirical evidence from lived user experience of how AI safety is perceived and emotionally experienced outside laboratory or speculative contexts, offering a foundation for future AI safety research, evaluation, and responsible governance.
NOIR: Privacy-Preserving Generation of Code with Open-Source LLMs
Jan 22, 2026Although boosting software development performance, large language model (LLM)-powered code generation introduces intellectual property and data security risks rooted in the fact that a service provider (cloud) observes a client's prompts and generated code, which can be proprietary in commercial systems. To mitigate this problem, we propose NOIR, the first framework to protect the client's prompts and generated code from the cloud. NOIR uses an encoder and a decoder at the client to encode and send the prompts' embeddings to the cloud to get enriched embeddings from the LLM, which are then decoded to generate the code locally at the client. Since the cloud can use the embeddings to infer the prompt and the generated code, NOIR introduces a new mechanism to achieve indistinguishability, a local differential privacy protection at the token embedding level, in the vocabulary used in the prompts and code, and a data-independent and randomized tokenizer on the client side. These components effectively defend against reconstruction and frequency analysis attacks by an honest-but-curious cloud. Extensive analysis and results using open-source LLMs show that NOIR significantly outperforms existing baselines on benchmarks, including the Evalplus (MBPP and HumanEval, Pass@1 of 76.7 and 77.4), and BigCodeBench (Pass@1 of 38.7, only a 1.77% drop from the original LLM) under strong privacy against attacks.
PAC-Bayes Bounds for Multivariate Linear Regression and Linear Autoencoders
Dec 15, 2025Linear Autoencoders (LAEs) have shown strong performance in state-of-the-art recommender systems. However, this success remains largely empirical, with limited theoretical understanding. In this paper, we investigate the generalizability -- a theoretical measure of model performance in statistical learning -- of multivariate linear regression and LAEs. We first propose a PAC-Bayes bound for multivariate linear regression, extending the earlier bound for single-output linear regression by Shalaeva et al., and establish sufficient conditions for its convergence. We then show that LAEs, when evaluated under a relaxed mean squared error, can be interpreted as constrained multivariate linear regression models on bounded data, to which our bound adapts. Furthermore, we develop theoretical methods to improve the computational efficiency of optimizing the LAE bound, enabling its practical evaluation on large models and real-world datasets. Experimental results demonstrate that our bound is tight and correlates well with practical ranking metrics such as Recall@K and NDCG@K.
Evaluating LLM Alignment on Personality Inference from Real-World Interview Data
Sep 16, 2025Large Language Models (LLMs) are increasingly deployed in roles requiring nuanced psychological understanding, such as emotional support agents, counselors, and decision-making assistants. However, their ability to interpret human personality traits, a critical aspect of such applications, remains unexplored, particularly in ecologically valid conversational settings. While prior work has simulated LLM "personas" using discrete Big Five labels on social media data, the alignment of LLMs with continuous, ground-truth personality assessments derived from natural interactions is largely unexamined. To address this gap, we introduce a novel benchmark comprising semi-structured interview transcripts paired with validated continuous Big Five trait scores. Using this dataset, we systematically evaluate LLM performance across three paradigms: (1) zero-shot and chain-of-thought prompting with GPT-4.1 Mini, (2) LoRA-based fine-tuning applied to both RoBERTa and Meta-LLaMA architectures, and (3) regression using static embeddings from pretrained BERT and OpenAI's text-embedding-3-small. Our results reveal that all Pearson correlations between model predictions and ground-truth personality traits remain below 0.26, highlighting the limited alignment of current LLMs with validated psychological constructs. Chain-of-thought prompting offers minimal gains over zero-shot, suggesting that personality inference relies more on latent semantic representation than explicit reasoning. These findings underscore the challenges of aligning LLMs with complex human attributes and motivate future work on trait-specific prompting, context-aware modeling, and alignment-oriented fine-tuning.
SoK: Are Watermarks in LLMs Ready for Deployment?
Jun 05, 2025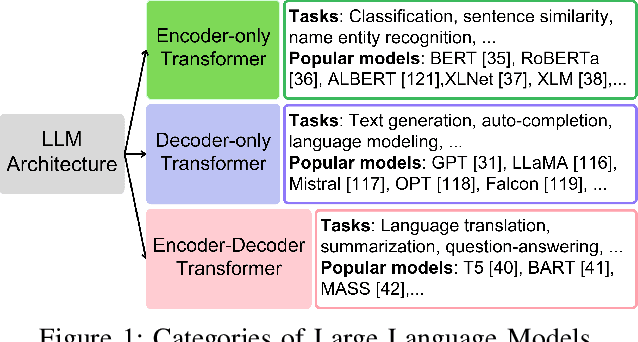
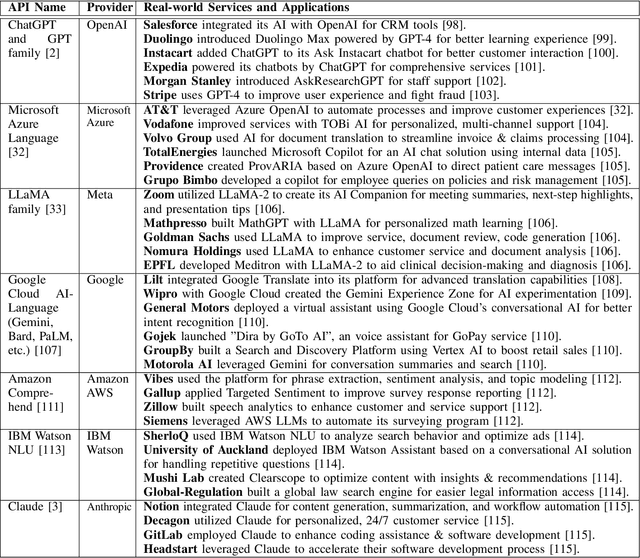
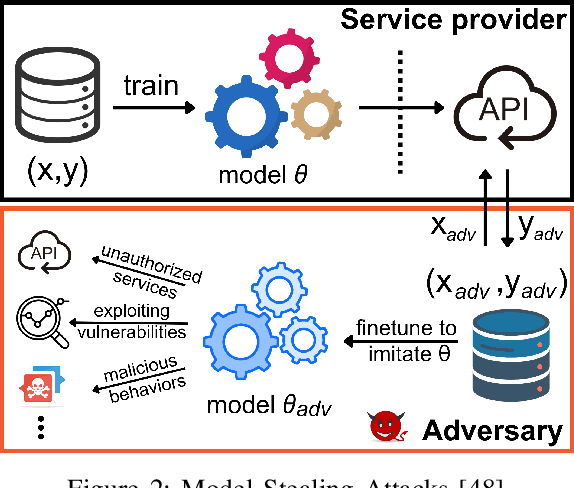
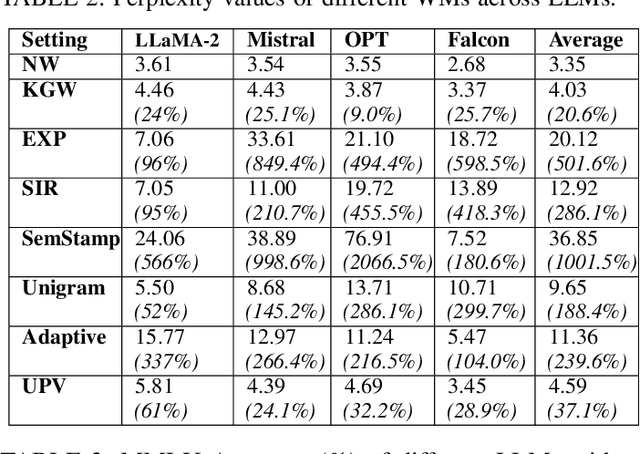
Large Language Models (LLMs) have transformed natural language processing, demonstrating impressive capabilities across diverse tasks. However, deploying these models introduces critical risks related to intellectual property violations and potential misuse, particularly as adversaries can imitate these models to steal services or generate misleading outputs. We specifically focus on model stealing attacks, as they are highly relevant to proprietary LLMs and pose a serious threat to their security, revenue, and ethical deployment. While various watermarking techniques have emerged to mitigate these risks, it remains unclear how far the community and industry have progressed in developing and deploying watermarks in LLMs. To bridge this gap, we aim to develop a comprehensive systematization for watermarks in LLMs by 1) presenting a detailed taxonomy for watermarks in LLMs, 2) proposing a novel intellectual property classifier to explore the effectiveness and impacts of watermarks on LLMs under both attack and attack-free environments, 3) analyzing the limitations of existing watermarks in LLMs, and 4) discussing practical challenges and potential future directions for watermarks in LLMs. Through extensive experiments, we show that despite promising research outcomes and significant attention from leading companies and community to deploy watermarks, these techniques have yet to reach their full potential in real-world applications due to their unfavorable impacts on model utility of LLMs and downstream tasks. Our findings provide an insightful understanding of watermarks in LLMs, highlighting the need for practical watermarks solutions tailored to LLM deployment.
FedX: Adaptive Model Decomposition and Quantization for IoT Federated Learning
Apr 19, 2025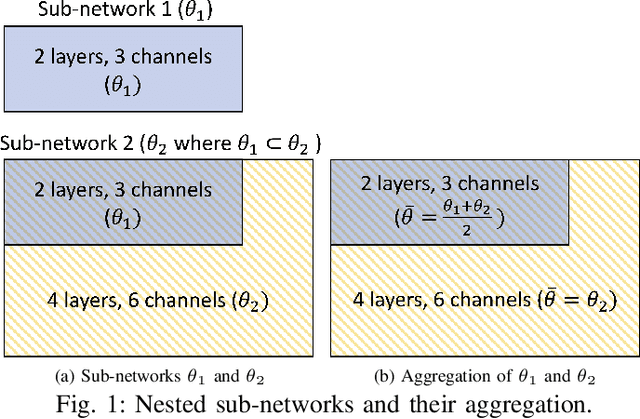
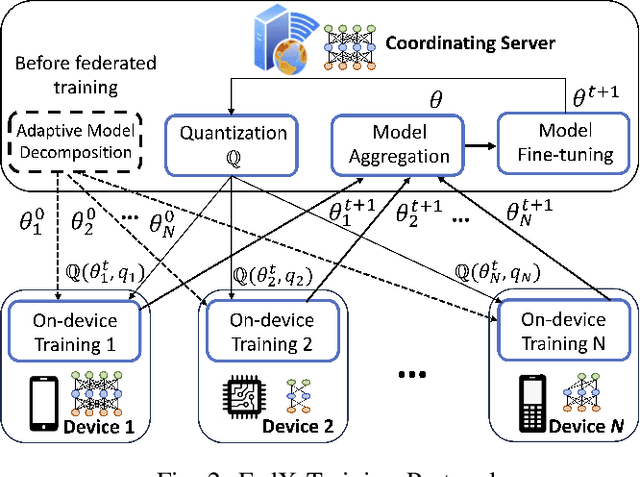
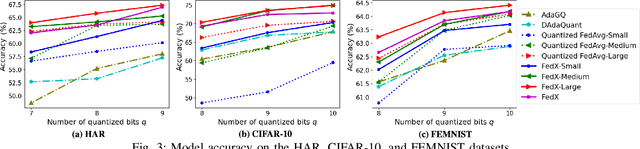
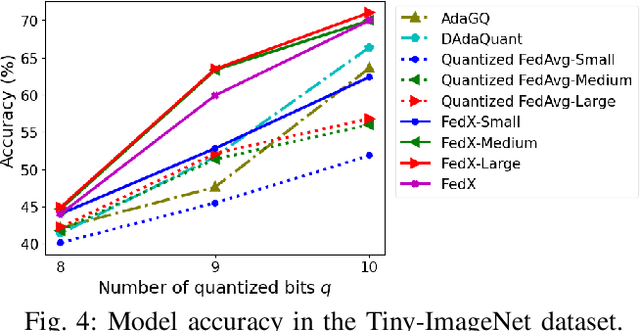
Federated Learning (FL) allows collaborative training among multiple devices without data sharing, thus enabling privacy-sensitive applications on mobile or Internet of Things (IoT) devices, such as mobile health and asset tracking. However, designing an FL system with good model utility that works with low computation/communication overhead on heterogeneous, resource-constrained mobile/IoT devices is challenging. To address this problem, this paper proposes FedX, a novel adaptive model decomposition and quantization FL system for IoT. To balance utility with resource constraints on IoT devices, FedX decomposes a global FL model into different sub-networks with adaptive numbers of quantized bits for different devices. The key idea is that a device with fewer resources receives a smaller sub-network for lower overhead but utilizes a larger number of quantized bits for higher model utility, and vice versa. The quantization operations in FedX are done at the server to reduce the computational load on devices. FedX iteratively minimizes the losses in the devices' local data and in the server's public data using quantized sub-networks under a regularization term, and thus it maximizes the benefits of combining FL with model quantization through knowledge sharing among the server and devices in a cost-effective training process. Extensive experiments show that FedX significantly improves quantization times by up to 8.43X, on-device computation time by 1.5X, and total end-to-end training time by 1.36X, compared with baseline FL systems. We guarantee the global model convergence theoretically and validate local model convergence empirically, highlighting FedX's optimization efficiency.
Can Large Language Models Understand Intermediate Representations?
Feb 07, 2025Intermediate Representations (IRs) are essential in compiler design and program analysis, yet their comprehension by Large Language Models (LLMs) remains underexplored. This paper presents a pioneering empirical study to investigate the capabilities of LLMs, including GPT-4, GPT-3, Gemma 2, LLaMA 3.1, and Code Llama, in understanding IRs. We analyze their performance across four tasks: Control Flow Graph (CFG) reconstruction, decompilation, code summarization, and execution reasoning. Our results indicate that while LLMs demonstrate competence in parsing IR syntax and recognizing high-level structures, they struggle with control flow reasoning, execution semantics, and loop handling. Specifically, they often misinterpret branching instructions, omit critical IR operations, and rely on heuristic-based reasoning, leading to errors in CFG reconstruction, IR decompilation, and execution reasoning. The study underscores the necessity for IR-specific enhancements in LLMs, recommending fine-tuning on structured IR datasets and integration of explicit control flow models to augment their comprehension and handling of IR-related tasks.