 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models to Analyze Emotional and Contextual Drivers of Teen Substance Use in Online Discussions
Jan 23, 2025



Adolescence is a critical stage often linked to risky behaviors, including substance use, with significant developmental and public health implications. Social media provides a lens into adolescent self-expression, but interpreting emotional and contextual signals remains complex. This study applies Large Language Models (LLMs) to analyze adolescents' social media posts, uncovering emotional patterns (e.g., sadness, guilt, fear, joy) and contextual factors (e.g., family, peers, school) related to substance use. Heatmap and machine learning analyses identified key predictors of substance use-related posts. Negative emotions like sadness and guilt were significantly more frequent in substance use contexts, with guilt acting as a protective factor, while shame and peer influence heightened substance use risk. Joy was more common in non-substance use discussions. Peer influence correlated strongly with sadness, fear, and disgust, while family and school environments aligned with non-substance use. Findings underscore the importance of addressing emotional vulnerabilities and contextual influences, suggesting that collaborative interventions involving families, schools, and communities can reduce risk factors and foster healthier adolescent development.
Analysis of Multivariate Scoring Functions for Automatic Unbiased Learning to Rank
Aug 20, 2020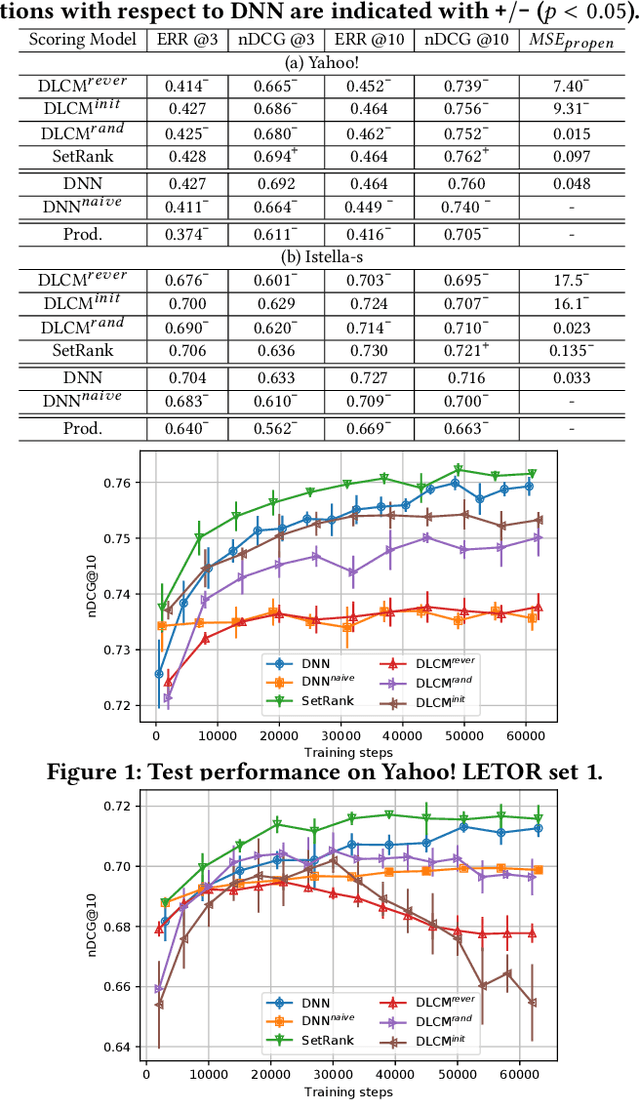
Leveraging biased click data for optimizing learning to rank systems has been a popular approach in information retrieval. Because click data is often noisy and biased, a variety of methods have been proposed to construct unbiased learning to rank (ULTR) algorithms for the learning of unbiased ranking models. Among them, automatic unbiased learning to rank (AutoULTR) algorithms that jointly learn user bias models (i.e., propensity models) with unbiased rankers have received a lot of attention due to their superior performance and low deployment cost in practice. Despite their differences in theories and algorithm design, existing studies on ULTR usually use uni-variate ranking functions to score each document or result independently. On the other hand, recent advances in context-aware learning-to-rank models have shown that multivariate scoring functions, which read multiple documents together and predict their ranking scores jointly, are more powerful than uni-variate ranking functions in ranking tasks with human-annotated relevance labels. Whether such superior performance would hold in ULTR with noisy data, however, is mostly unknown. In this paper, we investigate existing multivariate scoring functions and AutoULTR algorithms in theory and prove that permutation invariance is a crucial factor that determines whether a context-aware learning-to-rank model could be applied to existing AutoULTR framework. Our experiments with synthetic clicks on two large-scale benchmark datasets show that AutoULTR models with permutation-invariant multivariate scoring functions significantly outperform those with uni-variate scoring functions and permutation-variant multivariate scoring functions.