 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Bayesian Tensor Completion Meets Multioutput Gaussian Processes: Functional Universality and Rank Learning
Dec 25, 2025Functional tensor decomposition can analyze multi-dimensional data with real-valued indices, paving the path for applications in machine learning and signal processing. A limitation of existing approaches is the assumption that the tensor rank-a critical parameter governing model complexity-is known. However, determining the optimal rank is a non-deterministic polynomial-time hard (NP-hard) task and there is a limited understanding regarding the expressive power of functional low-rank tensor models for continuous signals. We propose a rank-revealing functional Bayesian tensor completion (RR-FBTC) method. Modeling the latent functions through carefully designed multioutput Gaussian processes, RR-FBTC handles tensors with real-valued indices while enabling automatic tensor rank determination during the inference process. We establish the universal approximation property of the model for continuous multi-dimensional signals, demonstrating its expressive power in a concise format. To learn this model, we employ the variational inference framework and derive an efficient algorithm with closed-form updates. Experiments on both synthetic and real-world datasets demonstrate the effectiveness and superiority of the RR-FBTC over state-of-the-art approaches. The code is available at https://github.com/OceanSTARLab/RR-FBTC.
Less Is More: Generating Time Series with LLaMA-Style Autoregression in Simple Factorized Latent Spaces
Nov 07, 2025Generative models for multivariate time series are essential for data augmentation, simulation, and privacy preservation, yet current state-of-the-art diffusion-based approaches are slow and limited to fixed-length windows. We propose FAR-TS, a simple yet effective framework that combines disentangled factorization with an autoregressive Transformer over a discrete, quantized latent space to generate time series. Each time series is decomposed into a data-adaptive basis that captures static cross-channel correlations and temporal coefficients that are vector-quantized into discrete tokens. A LLaMA-style autoregressive Transformer then models these token sequences, enabling fast and controllable generation of sequences with arbitrary length. Owing to its streamlined design, FAR-TS achieves orders-of-magnitude faster generation than Diffusion-TS while preserving cross-channel correlations and an interpretable latent space, enabling high-quality and flexible time series synthesis.
R&D-Agent: Automating Data-Driven AI Solution Building Through LLM-Powered Automated Research, Development, and Evolution
May 20, 2025Recent advances in AI and ML have transformed data science, yet increasing complexity and expertise requirements continue to hinder progress. While crowdsourcing platforms alleviate some challenges, high-level data science tasks remain labor-intensive and iterative. To overcome these limitations, we introduce R&D-Agent, a dual-agent framework for iterative exploration. The Researcher agent uses performance feedback to generate ideas, while the Developer agent refines code based on error feedback. By enabling multiple parallel exploration traces that merge and enhance one another, R&D-Agent narrows the gap between automated solutions and expert-level performance. Evaluated on MLE-Bench, R&D-Agent emerges as the top-performing machine learning engineering agent, demonstrating its potential to accelerate innovation and improve precision across diverse data science applications. We have open-sourced R&D-Agent on GitHub: https://github.com/microsoft/RD-Agent.
Physics-Guided Learning of Meteorological Dynamics for Weather Downscaling and Forecasting
May 20, 2025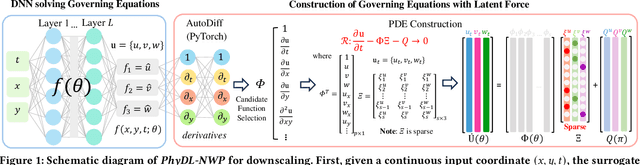

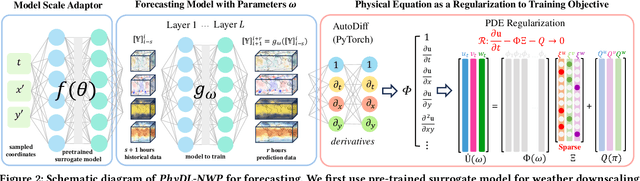
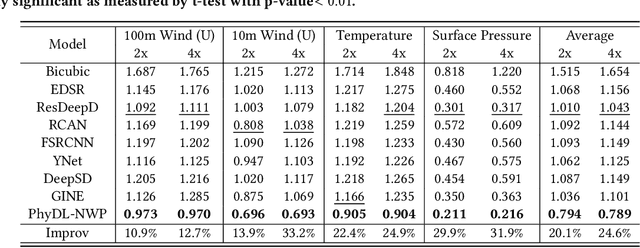
Weather forecasting is essential but remains computationally intensive and physically incomplete in traditional numerical weather prediction (NWP) methods. Deep learning (DL) models offer efficiency and accuracy but often ignore physical laws, limiting interpretability and generalization. We propose PhyDL-NWP, a physics-guided deep learning framework that integrates physical equations with latent force parameterization into data-driven models. It predicts weather variables from arbitrary spatiotemporal coordinates, computes physical terms via automatic differentiation, and uses a physics-informed loss to align predictions with governing dynamics. PhyDL-NWP enables resolution-free downscaling by modeling weather as a continuous function and fine-tunes pre-trained models with minimal overhead, achieving up to 170x faster inference with only 55K parameters. Experiments show that PhyDL-NWP improves both forecasting performance and physical consistency.
Generating Full-field Evolution of Physical Dynamics from Irregular Sparse Observations
May 14, 2025Modeling and reconstructing multidimensional physical dynamics from sparse and off-grid observations presents a fundamental challenge in scientific research. Recently, diffusion-based generative modeling shows promising potential for physical simulation. However, current approaches typically operate on on-grid data with preset spatiotemporal resolution, but struggle with the sparsely observed and continuous nature of real-world physical dynamics. To fill the gaps, we present SDIFT, Sequential DIffusion in Functional Tucker space, a novel framework that generates full-field evolution of physical dynamics from irregular sparse observations. SDIFT leverages the functional Tucker model as the latent space representer with proven universal approximation property, and represents observations as latent functions and Tucker core sequences. We then construct a sequential diffusion model with temporally augmented UNet in the functional Tucker space, denoising noise drawn from a Gaussian process to generate the sequence of core tensors. At the posterior sampling stage, we propose a Message-Passing Posterior Sampling mechanism, enabling conditional generation of the entire sequence guided by observations at limited time steps. We validate SDIFT on three physical systems spanning astronomical (supernova explosions, light-year scale), environmental (ocean sound speed fields, kilometer scale), and molecular (organic liquid, millimeter scale) domains, demonstrating significant improvements in both reconstruction accuracy and computational efficiency compared to state-of-the-art approaches.
Generalized Temporal Tensor Decomposition with Rank-revealing Latent-ODE
Feb 10, 2025Tensor decomposition is a fundamental tool for analyzing multi-dimensional data by learning low-rank factors to represent high-order interactions. While recent works on temporal tensor decomposition have made significant progress by incorporating continuous timestamps in latent factors, they still struggle with general tensor data with continuous indexes not only in the temporal mode but also in other modes, such as spatial coordinates in climate data. Additionally, the problem of determining the tensor rank remains largely unexplored in temporal tensor models. To address these limitations, we propose \underline{G}eneralized temporal tensor decomposition with \underline{R}ank-r\underline{E}vealing laten\underline{T}-ODE (GRET). Our approach encodes continuous spatial indexes as learnable Fourier features and employs neural ODEs in latent space to learn the temporal trajectories of factors. To automatically reveal the rank of temporal tensors, we introduce a rank-revealing Gaussian-Gamma prior over the factor trajectories. We develop an efficient variational inference scheme with an analytical evidence lower bound, enabling sampling-free optimization. Through extensive experiments on both synthetic and real-world datasets, we demonstrate that GRET not only reveals the underlying ranks of temporal tensors but also significantly outperforms existing methods in prediction performance and robustness against noise.
Diffusion-Generative Multi-Fidelity Learning for Physical Simulation
Nov 09, 2023



Multi-fidelity surrogate learning is important for physical simulation related applications in that it avoids running numerical solvers from scratch, which is known to be costly, and it uses multi-fidelity examples for training and greatly reduces the cost of data collection. Despite the variety of existing methods, they all build a model to map the input parameters outright to the solution output. Inspired by the recent breakthrough in generative models, we take an alternative view and consider the solution output as generated from random noises. We develop a diffusion-generative multi-fidelity (DGMF) learning method based on stochastic differential equations (SDE), where the generation is a continuous denoising process. We propose a conditional score model to control the solution generation by the input parameters and the fidelity. By conditioning on additional inputs (temporal or spacial variables), our model can efficiently learn and predict multi-dimensional solution arrays. Our method naturally unifies discrete and continuous fidelity modeling. The advantage of our method in several typical applications shows a promising new direction for multi-fidelity learning.
Solving High Frequency and Multi-Scale PDEs with Gaussian Processes
Nov 08, 2023



Machine learning based solvers have garnered much attention in physical simulation and scientific computing, with a prominent example, physics-informed neural networks (PINNs). However, PINNs often struggle to solve high-frequency and multi-scale PDEs, which can be due to spectral bias during neural network training. To address this problem, we resort to the Gaussian process (GP) framework. To flexibly capture the dominant frequencies, we model the power spectrum of the PDE solution with a student t mixture or Gaussian mixture. We then apply the inverse Fourier transform to obtain the covariance function (according to the Wiener-Khinchin theorem). The covariance derived from the Gaussian mixture spectrum corresponds to the known spectral mixture kernel. We are the first to discover its rationale and effectiveness for PDE solving. Next,we estimate the mixture weights in the log domain, which we show is equivalent to placing a Jeffreys prior. It automatically induces sparsity, prunes excessive frequencies, and adjusts the remaining toward the ground truth. Third, to enable efficient and scalable computation on massive collocation points, which are critical to capture high frequencies, we place the collocation points on a grid, and multiply our covariance function at each input dimension. We use the GP conditional mean to predict the solution and its derivatives so as to fit the boundary condition and the equation itself. As a result, we can derive a Kronecker product structure in the covariance matrix. We use Kronecker product properties and multilinear algebra to greatly promote computational efficiency and scalability, without any low-rank approximations. We show the advantage of our method in systematic experiments.
Functional Bayesian Tucker Decomposition for Continuous-indexed Tensor Data
Nov 08, 2023



Tucker decomposition is a powerful tensor model to handle multi-aspect data. It demonstrates the low-rank property by decomposing the grid-structured data as interactions between a core tensor and a set of object representations (factors). A fundamental assumption of such decomposition is that there were finite objects in each aspect or mode, corresponding to discrete indexes of data entries. However, many real-world data are not naturally posed in the setting. For example, geographic data is represented as continuous indexes of latitude and longitude coordinates, and cannot fit tensor models directly. To generalize Tucker decomposition to such scenarios, we propose Functional Bayesian Tucker Decomposition (FunBaT). We treat the continuous-indexed data as the interaction between the Tucker core and a group of latent functions. We use Gaussian processes (GP) as functional priors to model the latent functions, and then convert the GPs into a state-space prior by constructing an equivalent stochastic differential equation (SDE) to reduce computational cost. An efficient inference algorithm is further developed for scalable posterior approximation based on advanced message-passing techniques. The advantage of our method is shown in both synthetic data and several real-world applications.
Streaming Factor Trajectory Learning for Temporal Tensor Decomposition
Nov 07, 2023



Practical tensor data is often along with time information. Most existing temporal decomposition approaches estimate a set of fixed factors for the objects in each tensor mode, and hence cannot capture the temporal evolution of the objects' representation. More important, we lack an effective approach to capture such evolution from streaming data, which is common in real-world applications. To address these issues, we propose Streaming Factor Trajectory Learning for temporal tensor decomposition. We use Gaussian processes (GPs) to model the trajectory of factors so as to flexibly estimate their temporal evolution. To address the computational challenges in handling streaming data, we convert the GPs into a state-space prior by constructing an equivalent stochastic differential equation (SDE). We develop an efficient online filtering algorithm to estimate a decoupled running posterior of the involved factor states upon receiving new data. The decoupled estimation enables us to conduct standard Rauch-Tung-Striebel smoothing to compute the full posterior of all the trajectories in parallel, without the need for revisiting any previous data. We have shown the advantage of SFTL in both synthetic tasks and real-world applications. The code is available at {https://github.com/xuangu-fang/Streaming-Factor-Trajectory-Learning}.