 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Visual Computing in Materials Science (Shonan Seminar 189)
Jun 20, 2024Materials science has a significant impact on society and its quality of life, e.g., through the development of safer, more durable, more economical, environmentally friendly, and sustainable materials. Visual computing in materials science integrates computer science disciplines from image processing, visualization, computer graphics, pattern recognition, computer vision, virtual and augmented reality, machine learning, to human-computer interaction, to support the acquisition, analysis, and synthesis of (visual) materials science data with computer resources. Therefore, visual computing may provide fundamentally new insights into materials science problems by facilitating the understanding, discovery, design, and usage of complex material systems. This seminar is considered as a follow-up of the Dagstuhl Seminar 19151 Visual Computing in Materials Sciences, held in April 2019. Since then, the field has kept evolving and many novel challenges have emerged, with regard to more traditional topics in visual computing, such as topology analysis or image processing and analysis, to recently emerging topics, such as uncertainty and ensemble analysis, and to the integration of new research disciplines and exploratory technologies, such machine learning and immersive analytics. With the current seminar, we target to strengthen and extend the collaboration between the domains of visual computing and materials science (and across visual computing disciplines), by foreseeing challenges and identifying novel directions of interdisciplinary work. We brought visual computing and visualization experts from academia, research centers, and industry together with domain experts, to uncover the overlaps of visual computing and materials science and to discover yet-unsolved challenges, on which we can collaborate to achieve a higher societal impact.
Functional Bayesian Tucker Decomposition for Continuous-indexed Tensor Data
Nov 08, 2023



Tucker decomposition is a powerful tensor model to handle multi-aspect data. It demonstrates the low-rank property by decomposing the grid-structured data as interactions between a core tensor and a set of object representations (factors). A fundamental assumption of such decomposition is that there were finite objects in each aspect or mode, corresponding to discrete indexes of data entries. However, many real-world data are not naturally posed in the setting. For example, geographic data is represented as continuous indexes of latitude and longitude coordinates, and cannot fit tensor models directly. To generalize Tucker decomposition to such scenarios, we propose Functional Bayesian Tucker Decomposition (FunBaT). We treat the continuous-indexed data as the interaction between the Tucker core and a group of latent functions. We use Gaussian processes (GP) as functional priors to model the latent functions, and then convert the GPs into a state-space prior by constructing an equivalent stochastic differential equation (SDE) to reduce computational cost. An efficient inference algorithm is further developed for scalable posterior approximation based on advanced message-passing techniques. The advantage of our method is shown in both synthetic data and several real-world applications.
Multi-Resolution Active Learning of Fourier Neural Operators
Oct 08, 2023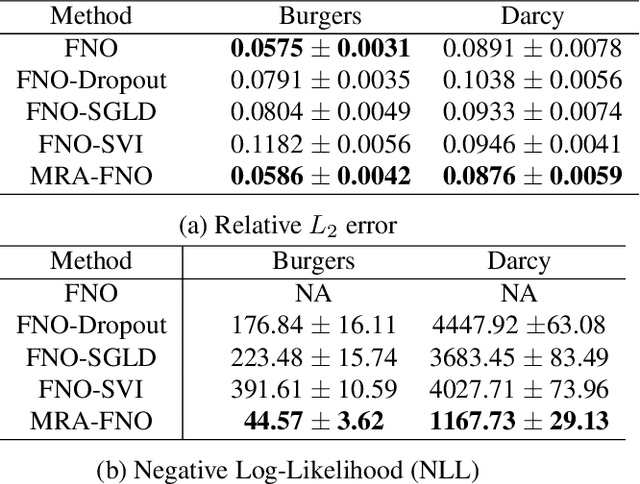
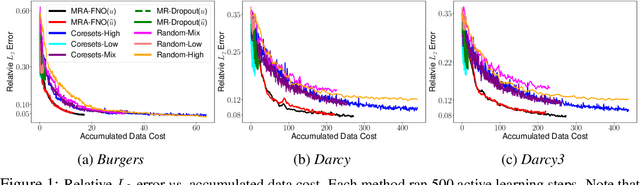

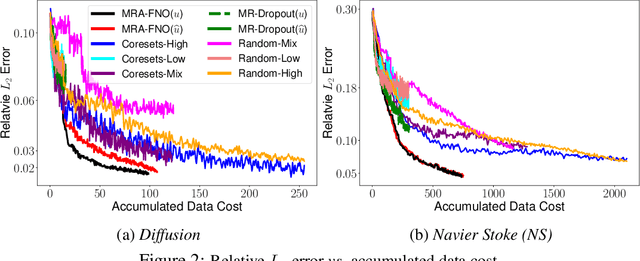
Fourier Neural Operator (FNO) is a popular operator learning framework, which not only achieves the state-of-the-art performance in many tasks, but also is highly efficient in training and prediction. However, collecting training data for the FNO is a costly bottleneck in practice, because it often demands expensive physical simulations. To overcome this problem, we propose Multi-Resolution Active learning of FNO (MRA-FNO), which can dynamically select the input functions and resolutions to lower the data cost as much as possible while optimizing the learning efficiency. Specifically, we propose a probabilistic multi-resolution FNO and use ensemble Monte-Carlo to develop an effective posterior inference algorithm. To conduct active learning, we maximize a utility-cost ratio as the acquisition function to acquire new examples and resolutions at each step. We use moment matching and the matrix determinant lemma to enable tractable, efficient utility computation. Furthermore, we develop a cost annealing framework to avoid over-penalizing high-resolution queries at the early stage. The over-penalization is severe when the cost difference is significant between the resolutions, which renders active learning often stuck at low-resolution queries and inferior performance. Our method overcomes this problem and applies to general multi-fidelity active learning and optimization problems. We have shown the advantage of our method in several benchmark operator learning tasks.
Multi-Fidelity Bayesian Optimization via Deep Neural Networks
Jul 08, 2020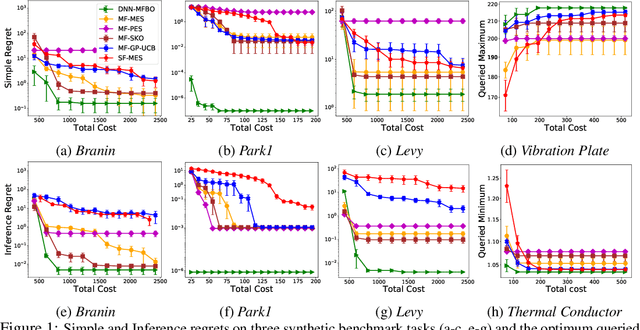
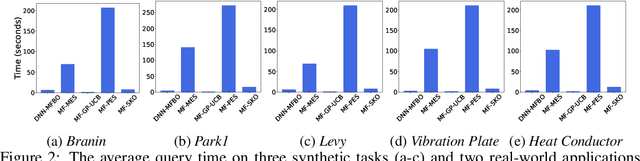
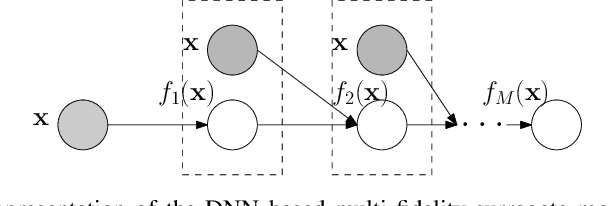

Bayesian optimization (BO) is a popular framework to optimize black-box functions. In many applications, the objective function can be evaluated at multiple fidelities to enable a trade-off between the cost and accuracy. To reduce the optimization cost, many multi-fidelity BO methods have been proposed. Despite their success, these methods either ignore or over-simplify the strong, complex correlations across the fidelities, and hence can be inefficient in estimating the objective function. To address this issue, we propose Deep Neural Network Multi-Fidelity Bayesian Optimization (DNN-MFBO) that can flexibly capture all kinds of complicated relationships between the fidelities to improve the objective function estimation and hence the optimization performance. We use sequential, fidelity-wise Gauss-Hermite quadrature and moment-matching to fulfill a mutual information-based acquisition function, which is computationally tractable and efficient. We show the advantages of our method in both synthetic benchmark datasets and real-world applications in engineering design.
Scalable Variational Gaussian Process Regression Networks
Mar 25, 2020


Gaussian process regression networks (GPRN) are powerful Bayesian models for multi-output regression, but their inference is intractable. To address this issue, existing methods use a fully factorized structure (or a mixture of such structures) over all the outputs and latent functions for posterior approximation, which, however, can miss the strong posterior dependencies among the latent variables and hurt the inference quality. In addition, the updates of the variational parameters are inefficient and can be prohibitively expensive for a large number of outputs. To overcome these limitations, we propose a scalable variational inference algorithm for GPRN, which not only captures the abundant posterior dependencies but also is much more efficient for massive outputs. We tensorize the output space and introduce tensor/matrix-normal variational posteriors to capture the posterior correlations and to reduce the parameters. We jointly optimize all the parameters and exploit the inherent Kronecker product structure in the variational model evidence lower bound to accelerate the computation. We demonstrate the advantages of our method in several real-world applications.