 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid least squares for learning functions from highly noisy data
Jul 03, 2025Motivated by the need for efficient estimation of conditional expectations, we consider a least-squares function approximation problem with heavily polluted data. Existing methods that are powerful in the small noise regime are suboptimal when large noise is present. We propose a hybrid approach that combines Christoffel sampling with certain types of optimal experimental design to address this issue. We show that the proposed algorithm enjoys appropriate optimality properties for both sample point generation and noise mollification, leading to improved computational efficiency and sample complexity compared to existing methods. We also extend the algorithm to convex-constrained settings with similar theoretical guarantees. When the target function is defined as the expectation of a random field, we extend our approach to leverage adaptive random subspaces and establish results on the approximation capacity of the adaptive procedure. Our theoretical findings are supported by numerical studies on both synthetic data and on a more challenging stochastic simulation problem in computational finance.
Arbitrarily-Conditioned Multi-Functional Diffusion for Multi-Physics Emulation
Oct 17, 2024Modern physics simulation often involves multiple functions of interests, and traditional numerical approaches are known to be complex and computationally costly. While machine learning-based surrogate models can offer significant cost reductions, most focus on a single task, such as forward prediction, and typically lack uncertainty quantification -- an essential component in many applications. To overcome these limitations, we propose Arbitrarily-Conditioned Multi-Functional Diffusion (ACMFD), a versatile probabilistic surrogate model for multi-physics emulation. ACMFD can perform a wide range of tasks within a single framework, including forward prediction, various inverse problems, and simulating data for entire systems or subsets of quantities conditioned on others. Specifically, we extend the standard Denoising Diffusion Probabilistic Model (DDPM) for multi-functional generation by modeling noise as Gaussian processes (GP). We then introduce an innovative denoising loss. The training involves randomly sampling the conditioned part and fitting the corresponding predicted noise to zero, enabling ACMFD to flexibly generate function values conditioned on any other functions or quantities. To enable efficient training and sampling, and to flexibly handle irregularly sampled data, we use GPs to interpolate function samples onto a grid, inducing a Kronecker product structure for efficient computation. We demonstrate the advantages of ACMFD across several fundamental multi-physics systems.
Kernel Neural Operators (KNOs) for Scalable, Memory-efficient, Geometrically-flexible Operator Learning
Jun 30, 2024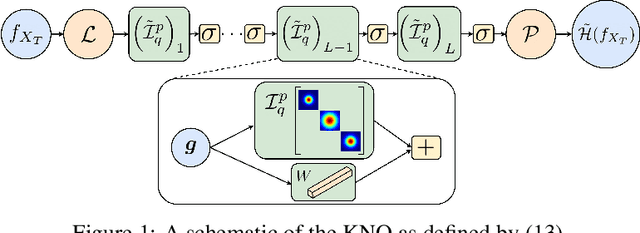
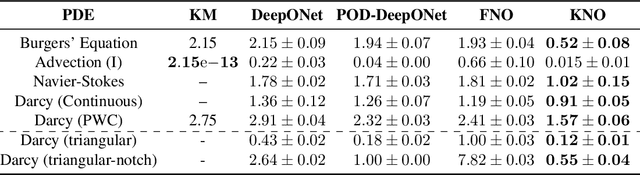
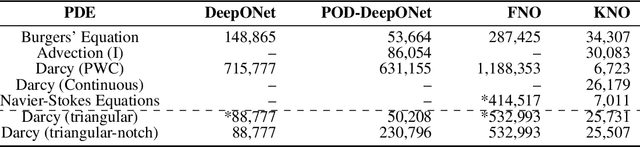
This paper introduces the Kernel Neural Operator (KNO), a novel operator learning technique that uses deep kernel-based integral operators in conjunction with quadrature for function-space approximation of operators (maps from functions to functions). KNOs use parameterized, closed-form, finitely-smooth, and compactly-supported kernels with trainable sparsity parameters within the integral operators to significantly reduce the number of parameters that must be learned relative to existing neural operators. Moreover, the use of quadrature for numerical integration endows the KNO with geometric flexibility that enables operator learning on irregular geometries. Numerical results demonstrate that on existing benchmarks the training and test accuracy of KNOs is higher than popular operator learning techniques while using at least an order of magnitude fewer trainable parameters. KNOs thus represent a new paradigm of low-memory, geometrically-flexible, deep operator learning, while retaining the implementation simplicity and transparency of traditional kernel methods from both scientific computing and machine learning.
TGPT-PINN: Nonlinear model reduction with transformed GPT-PINNs
Mar 06, 2024



We introduce the Transformed Generative Pre-Trained Physics-Informed Neural Networks (TGPT-PINN) for accomplishing nonlinear model order reduction (MOR) of transport-dominated partial differential equations in an MOR-integrating PINNs framework. Building on the recent development of the GPT-PINN that is a network-of-networks design achieving snapshot-based model reduction, we design and test a novel paradigm for nonlinear model reduction that can effectively tackle problems with parameter-dependent discontinuities. Through incorporation of a shock-capturing loss function component as well as a parameter-dependent transform layer, the TGPT-PINN overcomes the limitations of linear model reduction in the transport-dominated regime. We demonstrate this new capability for nonlinear model reduction in the PINNs framework by several nontrivial parametric partial differential equations.
Multi-Resolution Active Learning of Fourier Neural Operators
Oct 08, 2023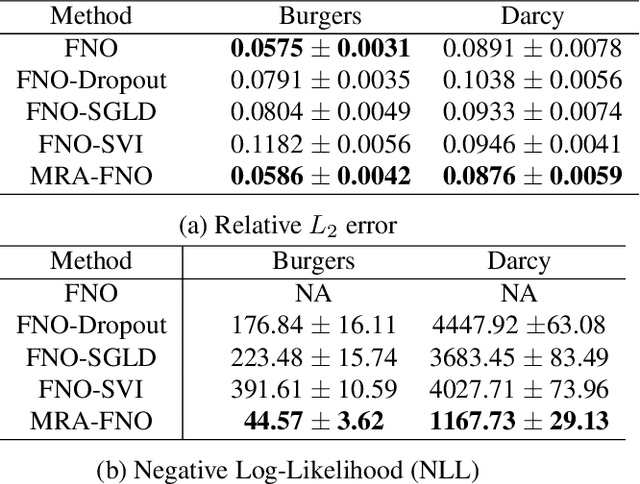
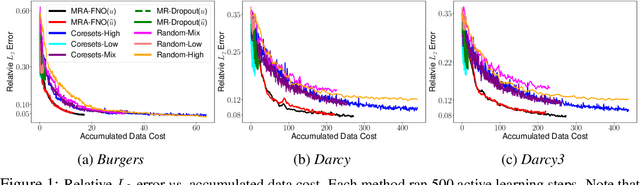

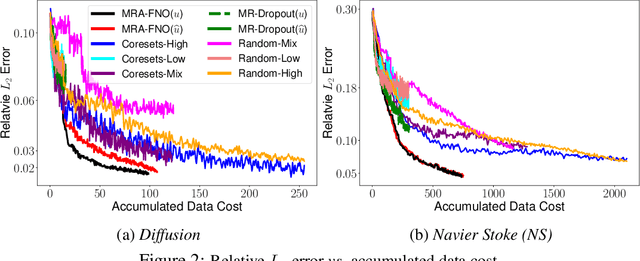
Fourier Neural Operator (FNO) is a popular operator learning framework, which not only achieves the state-of-the-art performance in many tasks, but also is highly efficient in training and prediction. However, collecting training data for the FNO is a costly bottleneck in practice, because it often demands expensive physical simulations. To overcome this problem, we propose Multi-Resolution Active learning of FNO (MRA-FNO), which can dynamically select the input functions and resolutions to lower the data cost as much as possible while optimizing the learning efficiency. Specifically, we propose a probabilistic multi-resolution FNO and use ensemble Monte-Carlo to develop an effective posterior inference algorithm. To conduct active learning, we maximize a utility-cost ratio as the acquisition function to acquire new examples and resolutions at each step. We use moment matching and the matrix determinant lemma to enable tractable, efficient utility computation. Furthermore, we develop a cost annealing framework to avoid over-penalizing high-resolution queries at the early stage. The over-penalization is severe when the cost difference is significant between the resolutions, which renders active learning often stuck at low-resolution queries and inferior performance. Our method overcomes this problem and applies to general multi-fidelity active learning and optimization problems. We have shown the advantage of our method in several benchmark operator learning tasks.
Nonparametric Embeddings of Sparse High-Order Interaction Events
Jul 08, 2022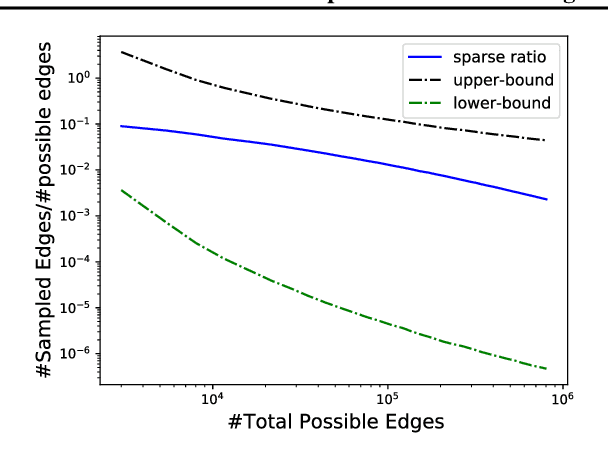
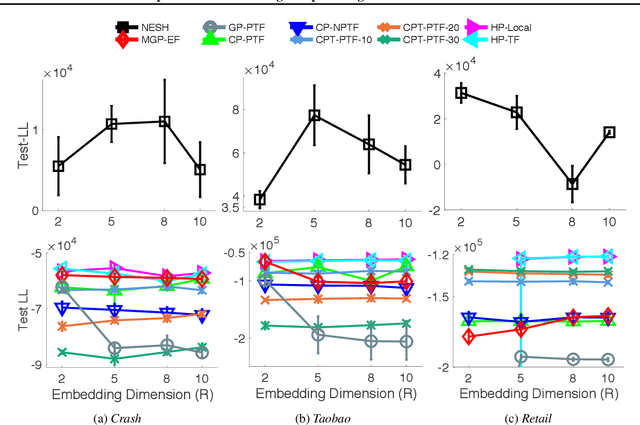
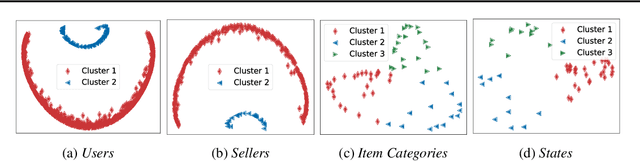
High-order interaction events are common in real-world applications. Learning embeddings that encode the complex relationships of the participants from these events is of great importance in knowledge mining and predictive tasks. Despite the success of existing approaches, e.g. Poisson tensor factorization, they ignore the sparse structure underlying the data, namely the occurred interactions are far less than the possible interactions among all the participants. In this paper, we propose Nonparametric Embeddings of Sparse High-order interaction events (NESH). We hybridize a sparse hypergraph (tensor) process and a matrix Gaussian process to capture both the asymptotic structural sparsity within the interactions and nonlinear temporal relationships between the participants. We prove strong asymptotic bounds (including both a lower and an upper bound) of the sparsity ratio, which reveals the asymptotic properties of the sampled structure. We use batch-normalization, stick-breaking construction, and sparse variational GP approximations to develop an efficient, scalable model inference algorithm. We demonstrate the advantage of our approach in several real-world applications.
Proximal Implicit ODE Solvers for Accelerating Learning Neural ODEs
Apr 19, 2022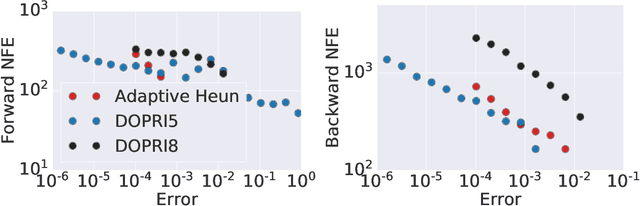

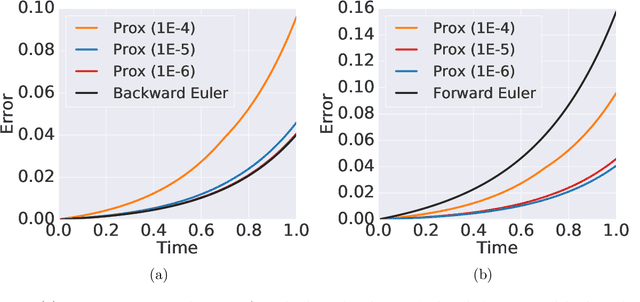

Learning neural ODEs often requires solving very stiff ODE systems, primarily using explicit adaptive step size ODE solvers. These solvers are computationally expensive, requiring the use of tiny step sizes for numerical stability and accuracy guarantees. This paper considers learning neural ODEs using implicit ODE solvers of different orders leveraging proximal operators. The proximal implicit solver consists of inner-outer iterations: the inner iterations approximate each implicit update step using a fast optimization algorithm, and the outer iterations solve the ODE system over time. The proximal implicit ODE solver guarantees superiority over explicit solvers in numerical stability and computational efficiency. We validate the advantages of proximal implicit solvers over existing popular neural ODE solvers on various challenging benchmark tasks, including learning continuous-depth graph neural networks and continuous normalizing flows.
Dimensionality Reduction in Deep Learning via Kronecker Multi-layer Architectures
Apr 08, 2022


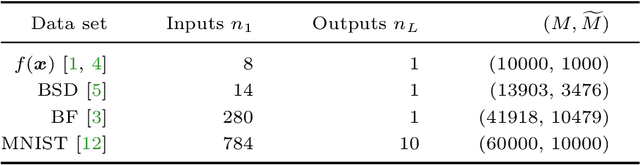
Deep learning using neural networks is an effective technique for generating models of complex data. However, training such models can be expensive when networks have large model capacity resulting from a large number of layers and nodes. For training in such a computationally prohibitive regime, dimensionality reduction techniques ease the computational burden, and allow implementations of more robust networks. We propose a novel type of such dimensionality reduction via a new deep learning architecture based on fast matrix multiplication of a Kronecker product decomposition; in particular our network construction can be viewed as a Kronecker product-induced sparsification of an "extended" fully connected network. Analysis and practical examples show that this architecture allows a neural network to be trained and implemented with a significant reduction in computational time and resources, while achieving a similar error level compared to a traditional feedforward neural network.
Learning POD of Complex Dynamics Using Heavy-ball Neural ODEs
Feb 24, 2022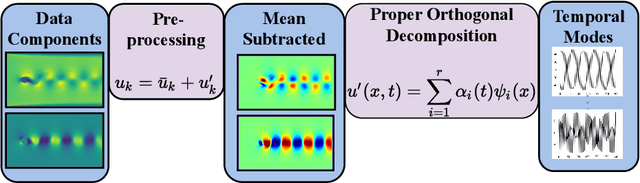

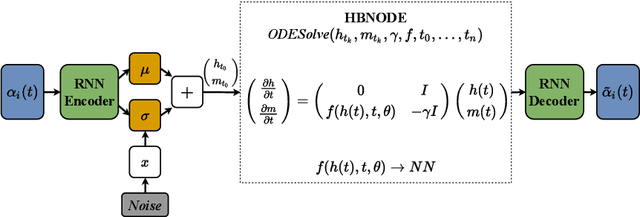

Proper orthogonal decomposition (POD) allows reduced-order modeling of complex dynamical systems at a substantial level, while maintaining a high degree of accuracy in modeling the underlying dynamical systems. Advances in machine learning algorithms enable learning POD-based dynamics from data and making accurate and fast predictions of dynamical systems. In this paper, we leverage the recently proposed heavy-ball neural ODEs (HBNODEs) [Xia et al. NeurIPS, 2021] for learning data-driven reduced-order models (ROMs) in the POD context, in particular, for learning dynamics of time-varying coefficients generated by the POD analysis on training snapshots generated from solving full order models. HBNODE enjoys several practical advantages for learning POD-based ROMs with theoretical guarantees, including 1) HBNODE can learn long-term dependencies effectively from sequential observations and 2) HBNODE is computationally efficient in both training and testing. We compare HBNODE with other popular ROMs on several complex dynamical systems, including the von K\'{a}rm\'{a}n Street flow, the Kurganov-Petrova-Popov equation, and the one-dimensional Euler equations for fluids modeling.
Physics-Informed Neural Networks for Parameterized PDEs: A Metalearning Approach
Oct 26, 2021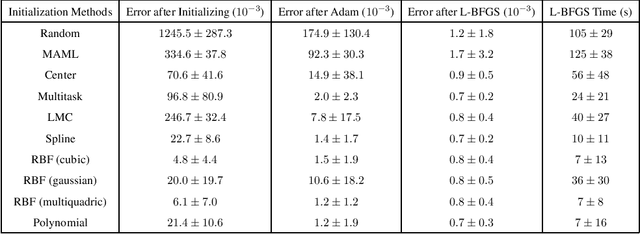

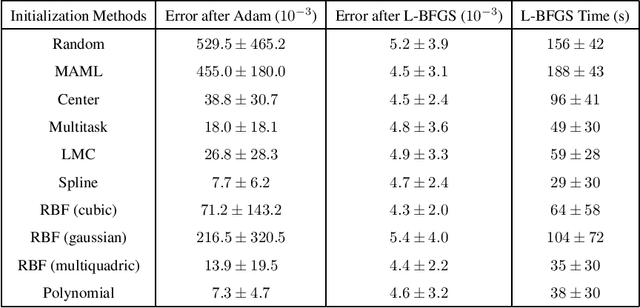
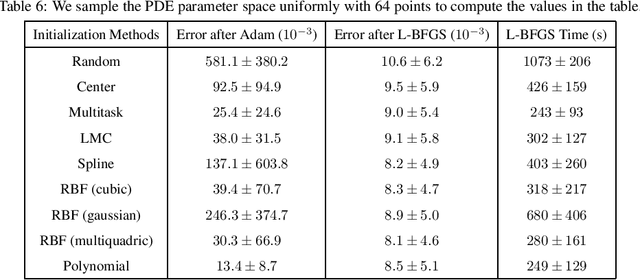
Physics-informed neural networks (PINNs) as a means of discretizing partial differential equations (PDEs) are garnering much attention in the Computational Science and Engineering (CS&E) world. At least two challenges exist for PINNs at present: an understanding of accuracy and convergence characteristics with respect to tunable parameters and identification of optimization strategies that make PINNs as efficient as other computational science tools. The cost of PINNs training remains a major challenge of Physics-informed Machine Learning (PiML) -- and, in fact, machine learning (ML) in general. This paper is meant to move towards addressing the latter through the study of PINNs for parameterized PDEs. Following the ML world, we introduce metalearning of PINNs for parameterized PDEs. By introducing metalearning and transfer learning concepts, we can greatly accelerate the PINNs optimization process. We present a survey of model-agnostic metalearning, and then discuss our model-aware metalearning applied to PINNs. We provide theoretically motivated and empirically backed assumptions that make our metalearning approach possible. We then test our approach on various canonical forward parameterized PDEs that have been presented in the emerging PINNs literature.