 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sharp Minimax Risk Bounds for Operator Learning
Dec 19, 2025We develop a minimax theory for operator learning, where the goal is to estimate an unknown operator between separable Hilbert spaces from finitely many noisy input-output samples. For uniformly bounded Lipschitz operators, we prove information-theoretic lower bounds together with matching or near-matching upper bounds, covering both fixed and random designs under Hilbert-valued Gaussian noise and Gaussian white noise errors. The rates are controlled by the spectrum of the covariance operator of the measure that defines the error metric. Our setup is very general and allows for measures with unbounded support. A key implication is a curse of sample complexity which shows that the minimax risk for generic Lipschitz operators cannot decay at any algebraic rate in the sample size. We obtain essentially sharp characterizations when the covariance spectrum decays exponentially and provide general upper and lower bounds in slower-decay regimes.
Hybrid least squares for learning functions from highly noisy data
Jul 03, 2025Motivated by the need for efficient estimation of conditional expectations, we consider a least-squares function approximation problem with heavily polluted data. Existing methods that are powerful in the small noise regime are suboptimal when large noise is present. We propose a hybrid approach that combines Christoffel sampling with certain types of optimal experimental design to address this issue. We show that the proposed algorithm enjoys appropriate optimality properties for both sample point generation and noise mollification, leading to improved computational efficiency and sample complexity compared to existing methods. We also extend the algorithm to convex-constrained settings with similar theoretical guarantees. When the target function is defined as the expectation of a random field, we extend our approach to leverage adaptive random subspaces and establish results on the approximation capacity of the adaptive procedure. Our theoretical findings are supported by numerical studies on both synthetic data and on a more challenging stochastic simulation problem in computational finance.
How many measurements are enough? Bayesian recovery in inverse problems with general distributions
May 15, 2025We study the sample complexity of Bayesian recovery for solving inverse problems with general prior, forward operator and noise distributions. We consider posterior sampling according to an approximate prior $\mathcal{P}$, and establish sufficient conditions for stable and accurate recovery with high probability. Our main result is a non-asymptotic bound that shows that the sample complexity depends on (i) the intrinsic complexity of $\mathcal{P}$, quantified by its so-called approximate covering number, and (ii) concentration bounds for the forward operator and noise distributions. As a key application, we specialize to generative priors, where $\mathcal{P}$ is the pushforward of a latent distribution via a Deep Neural Network (DNN). We show that the sample complexity scales log-linearly with the latent dimension $k$, thus establishing the efficacy of DNN-based priors. Generalizing existing results on deterministic (i.e., non-Bayesian) recovery for the important problem of random sampling with an orthogonal matrix $U$, we show how the sample complexity is determined by the coherence of $U$ with respect to the support of $\mathcal{P}$. Hence, we establish that coherence plays a fundamental role in Bayesian recovery as well. Overall, our framework unifies and extends prior work, providing rigorous guarantees for the sample complexity of solving Bayesian inverse problems with arbitrary distributions.
Learning Lipschitz Operators with respect to Gaussian Measures with Near-Optimal Sample Complexity
Oct 30, 2024Operator learning, the approximation of mappings between infinite-dimensional function spaces using ideas from machine learning, has gained increasing research attention in recent years. Approximate operators, learned from data, hold promise to serve as efficient surrogate models for problems in computational science and engineering, complementing traditional numerical methods. However, despite their empirical success, our understanding of the underpinning mathematical theory is in large part still incomplete. In this paper, we study the approximation of Lipschitz operators in expectation with respect to Gaussian measures. We prove higher Gaussian Sobolev regularity of Lipschitz operators and establish lower and upper bounds on the Hermite polynomial approximation error. We further consider the reconstruction of Lipschitz operators from $m$ arbitrary (adaptive) linear samples. A key finding is the tight characterization of the smallest achievable error for all possible (adaptive) sampling and reconstruction maps in terms of $m$. It is shown that Hermite polynomial approximation is an optimal recovery strategy, but we have the following curse of sample complexity: No method to approximate Lipschitz operators based on finitely many samples can achieve algebraic convergence rates in $m$. On the positive side, we prove that a sufficiently fast spectral decay of the covariance operator of the Gaussian measure guarantees convergence rates which are arbitrarily close to any algebraic rate in the large data limit $m \to \infty$. Finally, we focus on the recovery of Lipschitz operators from finitely many point samples. We consider Christoffel sampling and weighted least-squares approximation, and present an algorithm which provably achieves near-optimal sample complexity.
Optimal sampling for least-squares approximation
Sep 04, 2024
Least-squares approximation is one of the most important methods for recovering an unknown function from data. While in many applications the data is fixed, in many others there is substantial freedom to choose where to sample. In this paper, we review recent progress on optimal sampling for (weighted) least-squares approximation in arbitrary linear spaces. We introduce the Christoffel function as a key quantity in the analysis of (weighted) least-squares approximation from random samples, then show how it can be used to construct sampling strategies that possess near-optimal sample complexity: namely, the number of samples scales log-linearly in $n$, the dimension of the approximation space. We discuss a series of variations, extensions and further topics, and throughout highlight connections to approximation theory, machine learning, information-based complexity and numerical linear algebra. Finally, motivated by various contemporary applications, we consider a generalization of the classical setting where the samples need not be pointwise samples of a scalar-valued function, and the approximation space need not be linear. We show that even in this significantly more general setting suitable generalizations of the Christoffel function still determine the sample complexity. This provides a unified procedure for designing improved sampling strategies for general recovery problems. This article is largely self-contained, and intended to be accessible to nonspecialists.
On the consistent reasoning paradox of intelligence and optimal trust in AI: The power of 'I don't know'
Aug 05, 2024We introduce the Consistent Reasoning Paradox (CRP). Consistent reasoning, which lies at the core of human intelligence, is the ability to handle tasks that are equivalent, yet described by different sentences ('Tell me the time!' and 'What is the time?'). The CRP asserts that consistent reasoning implies fallibility -- in particular, human-like intelligence in AI necessarily comes with human-like fallibility. Specifically, it states that there are problems, e.g. in basic arithmetic, where any AI that always answers and strives to mimic human intelligence by reasoning consistently will hallucinate (produce wrong, yet plausible answers) infinitely often. The paradox is that there exists a non-consistently reasoning AI (which therefore cannot be on the level of human intelligence) that will be correct on the same set of problems. The CRP also shows that detecting these hallucinations, even in a probabilistic sense, is strictly harder than solving the original problems, and that there are problems that an AI may answer correctly, but it cannot provide a correct logical explanation for how it arrived at the answer. Therefore, the CRP implies that any trustworthy AI (i.e., an AI that never answers incorrectly) that also reasons consistently must be able to say 'I don't know'. Moreover, this can only be done by implicitly computing a new concept that we introduce, termed the 'I don't know' function -- something currently lacking in modern AI. In view of these insights, the CRP also provides a glimpse into the behaviour of Artificial General Intelligence (AGI). An AGI cannot be 'almost sure', nor can it always explain itself, and therefore to be trustworthy it must be able to say 'I don't know'.
Optimal deep learning of holomorphic operators between Banach spaces
Jun 20, 2024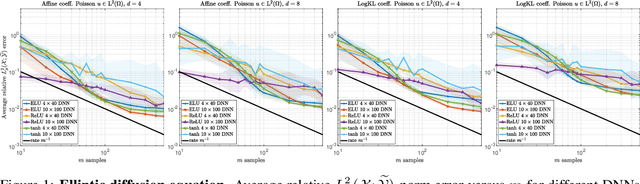
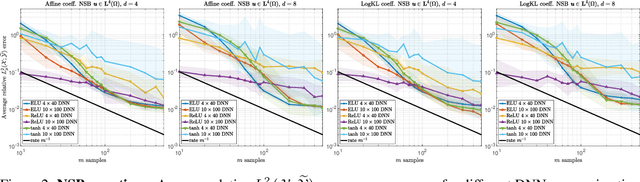
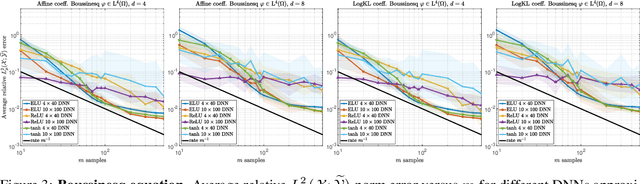
Operator learning problems arise in many key areas of scientific computing where Partial Differential Equations (PDEs) are used to model physical systems. In such scenarios, the operators map between Banach or Hilbert spaces. In this work, we tackle the problem of learning operators between Banach spaces, in contrast to the vast majority of past works considering only Hilbert spaces. We focus on learning holomorphic operators - an important class of problems with many applications. We combine arbitrary approximate encoders and decoders with standard feedforward Deep Neural Network (DNN) architectures - specifically, those with constant width exceeding the depth - under standard $\ell^2$-loss minimization. We first identify a family of DNNs such that the resulting Deep Learning (DL) procedure achieves optimal generalization bounds for such operators. For standard fully-connected architectures, we then show that there are uncountably many minimizers of the training problem that yield equivalent optimal performance. The DNN architectures we consider are `problem agnostic', with width and depth only depending on the amount of training data $m$ and not on regularity assumptions of the target operator. Next, we show that DL is optimal for this problem: no recovery procedure can surpass these generalization bounds up to log terms. Finally, we present numerical results demonstrating the practical performance on challenging problems including the parametric diffusion, Navier-Stokes-Brinkman and Boussinesq PDEs.
Learning smooth functions in high dimensions: from sparse polynomials to deep neural networks
Apr 04, 2024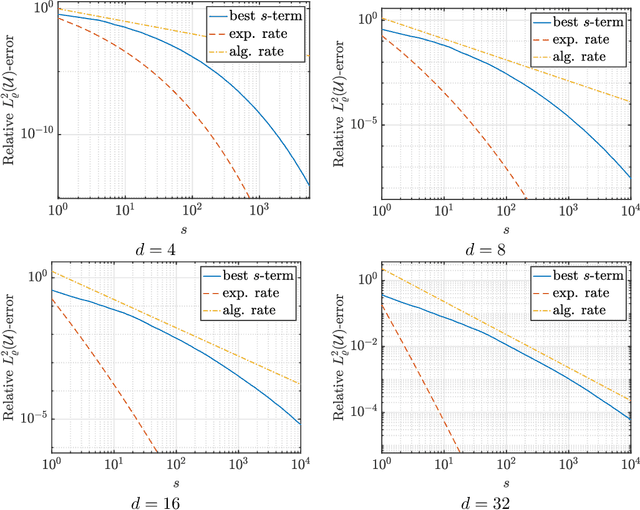
Learning approximations to smooth target functions of many variables from finite sets of pointwise samples is an important task in scientific computing and its many applications in computational science and engineering. Despite well over half a century of research on high-dimensional approximation, this remains a challenging problem. Yet, significant advances have been made in the last decade towards efficient methods for doing this, commencing with so-called sparse polynomial approximation methods and continuing most recently with methods based on Deep Neural Networks (DNNs). In tandem, there have been substantial advances in the relevant approximation theory and analysis of these techniques. In this work, we survey this recent progress. We describe the contemporary motivations for this problem, which stem from parametric models and computational uncertainty quantification; the relevant function classes, namely, classes of infinite-dimensional, Banach-valued, holomorphic functions; fundamental limits of learnability from finite data for these classes; and finally, sparse polynomial and DNN methods for efficiently learning such functions from finite data. For the latter, there is currently a significant gap between the approximation theory of DNNs and the practical performance of deep learning. Aiming to narrow this gap, we develop the topic of practical existence theory, which asserts the existence of dimension-independent DNN architectures and training strategies that achieve provably near-optimal generalization errors in terms of the amount of training data.
A unified framework for learning with nonlinear model classes from arbitrary linear samples
Nov 25, 2023This work considers the fundamental problem of learning an unknown object from training data using a given model class. We introduce a unified framework that allows for objects in arbitrary Hilbert spaces, general types of (random) linear measurements as training data and general types of nonlinear model classes. We establish a series of learning guarantees for this framework. These guarantees provide explicit relations between the amount of training data and properties of the model class to ensure near-best generalization bounds. In doing so, we also introduce and develop the key notion of the variation of a model class with respect to a distribution of sampling operators. To exhibit the versatility of this framework, we show that it can accommodate many different types of well-known problems of interest. We present examples such as matrix sketching by random sampling, compressed sensing with isotropic vectors, active learning in regression and compressed sensing with generative models. In all cases, we show how known results become straightforward corollaries of our general learning guarantees. For compressed sensing with generative models, we also present a number of generalizations and improvements of recent results. In summary, our work not only introduces a unified way to study learning unknown objects from general types of data, but also establishes a series of general theoretical guarantees which consolidate and improve various known results.
CS4ML: A general framework for active learning with arbitrary data based on Christoffel functions
Jun 01, 2023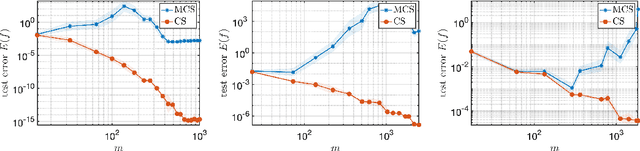

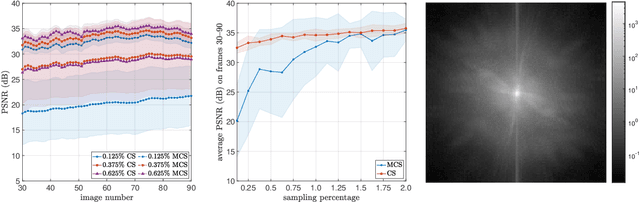
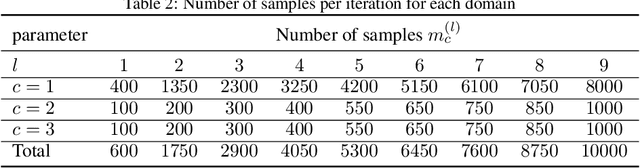
We introduce a general framework for active learning in regression problems. Our framework extends the standard setup by allowing for general types of data, rather than merely pointwise samples of the target function. This generalization covers many cases of practical interest, such as data acquired in transform domains (e.g., Fourier data), vector-valued data (e.g., gradient-augmented data), data acquired along continuous curves, and, multimodal data (i.e., combinations of different types of measurements). Our framework considers random sampling according to a finite number of sampling measures and arbitrary nonlinear approximation spaces (model classes). We introduce the concept of generalized Christoffel functions and show how these can be used to optimize the sampling measures. We prove that this leads to near-optimal sample complexity in various important cases. This paper focuses on applications in scientific computing, where active learning is often desirable, since it is usually expensive to generate data. We demonstrate the efficacy of our framework for gradient-augmented learning with polynomials, Magnetic Resonance Imaging (MRI) using generative models and adaptive sampling for solving PDEs using Physics-Informed Neural Networks (PINNs).