 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Hallucinations in Inverse Problems: Fundamental Limits and Provable Assessment Methods
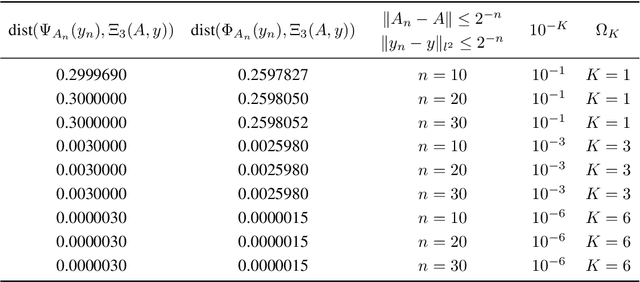
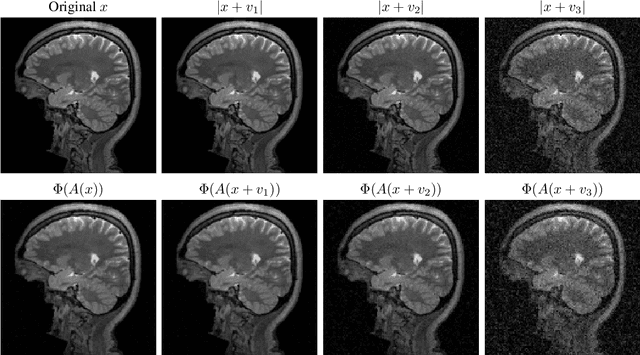
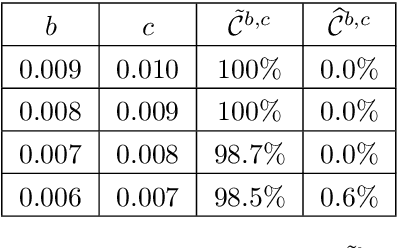
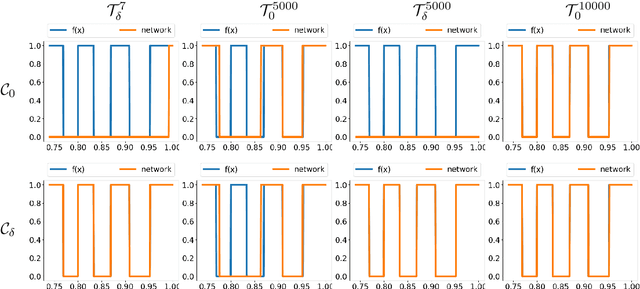
May 13, 2026Artificial intelligence (AI) has transformed imaging inverse problems, from medical diagnostics to Earth observation. Yet deep neural networks can produce hallucinations, realistic-looking but incorrect details, undermining their reliability, especially when ground truth data is unavailable. We develop a theoretical framework showing that such hallucinations are not merely artifacts of particular models, but can arise from the ill-posed nature of the inverse problem itself. We derive necessary and sufficient conditions for hallucinations, together with computable bounds on their magnitude that depend only on the forward model. Building on this theory, we introduce algorithms to: (1) estimate the minimum hallucination magnitude achievable by any reconstruction model for a given input; (2) assess the faithfulness of reconstructed details by a given reconstruction model. Experiments across three imaging tasks demonstrate that our approach applies broadly, including to modern generative models, and provides a principled way to quantify and evaluate AI hallucinations.
On the consistent reasoning paradox of intelligence and optimal trust in AI: The power of 'I don't know'
Aug 05, 2024We introduce the Consistent Reasoning Paradox (CRP). Consistent reasoning, which lies at the core of human intelligence, is the ability to handle tasks that are equivalent, yet described by different sentences ('Tell me the time!' and 'What is the time?'). The CRP asserts that consistent reasoning implies fallibility -- in particular, human-like intelligence in AI necessarily comes with human-like fallibility. Specifically, it states that there are problems, e.g. in basic arithmetic, where any AI that always answers and strives to mimic human intelligence by reasoning consistently will hallucinate (produce wrong, yet plausible answers) infinitely often. The paradox is that there exists a non-consistently reasoning AI (which therefore cannot be on the level of human intelligence) that will be correct on the same set of problems. The CRP also shows that detecting these hallucinations, even in a probabilistic sense, is strictly harder than solving the original problems, and that there are problems that an AI may answer correctly, but it cannot provide a correct logical explanation for how it arrived at the answer. Therefore, the CRP implies that any trustworthy AI (i.e., an AI that never answers incorrectly) that also reasons consistently must be able to say 'I don't know'. Moreover, this can only be done by implicitly computing a new concept that we introduce, termed the 'I don't know' function -- something currently lacking in modern AI. In view of these insights, the CRP also provides a glimpse into the behaviour of Artificial General Intelligence (AGI). An AGI cannot be 'almost sure', nor can it always explain itself, and therefore to be trustworthy it must be able to say 'I don't know'.
When can you trust feature selection? -- I: A condition-based analysis of LASSO and generalised hardness of approximation
Dec 18, 2023The arrival of AI techniques in computations, with the potential for hallucinations and non-robustness, has made trustworthiness of algorithms a focal point. However, trustworthiness of the many classical approaches are not well understood. This is the case for feature selection, a classical problem in the sciences, statistics, machine learning etc. Here, the LASSO optimisation problem is standard. Despite its widespread use, it has not been established when the output of algorithms attempting to compute support sets of minimisers of LASSO in order to do feature selection can be trusted. In this paper we establish how no (randomised) algorithm that works on all inputs can determine the correct support sets (with probability $> 1/2$) of minimisers of LASSO when reading approximate input, regardless of precision and computing power. However, we define a LASSO condition number and design an efficient algorithm for computing these support sets provided the input data is well-posed (has finite condition number) in time polynomial in the dimensions and logarithm of the condition number. For ill-posed inputs the algorithm runs forever, hence, it will never produce a wrong answer. Furthermore, the algorithm computes an upper bound for the condition number when this is finite. Finally, for any algorithm defined on an open set containing a point with infinite condition number, there is an input for which the algorithm will either run forever or produce a wrong answer. Our impossibility results stem from generalised hardness of approximation -- within the Solvability Complexity Index (SCI) hierarchy framework -- that generalises the classical phenomenon of hardness of approximation.
The Boundaries of Verifiable Accuracy, Robustness, and Generalisation in Deep Learning
Sep 13, 2023In this work, we assess the theoretical limitations of determining guaranteed stability and accuracy of neural networks in classification tasks. We consider classical distribution-agnostic framework and algorithms minimising empirical risks and potentially subjected to some weights regularisation. We show that there is a large family of tasks for which computing and verifying ideal stable and accurate neural networks in the above settings is extremely challenging, if at all possible, even when such ideal solutions exist within the given class of neural architectures.
Implicit regularization in AI meets generalized hardness of approximation in optimization -- Sharp results for diagonal linear networks
Jul 13, 2023Understanding the implicit regularization imposed by neural network architectures and gradient based optimization methods is a key challenge in deep learning and AI. In this work we provide sharp results for the implicit regularization imposed by the gradient flow of Diagonal Linear Networks (DLNs) in the over-parameterized regression setting and, potentially surprisingly, link this to the phenomenon of phase transitions in generalized hardness of approximation (GHA). GHA generalizes the phenomenon of hardness of approximation from computer science to, among others, continuous and robust optimization. It is well-known that the $\ell^1$-norm of the gradient flow of DLNs with tiny initialization converges to the objective function of basis pursuit. We improve upon these results by showing that the gradient flow of DLNs with tiny initialization approximates minimizers of the basis pursuit optimization problem (as opposed to just the objective function), and we obtain new and sharp convergence bounds w.r.t.\ the initialization size. Non-sharpness of our results would imply that the GHA phenomenon would not occur for the basis pursuit optimization problem -- which is a contradiction -- thus implying sharpness. Moreover, we characterize $\textit{which}$ $\ell_1$ minimizer of the basis pursuit problem is chosen by the gradient flow whenever the minimizer is not unique. Interestingly, this depends on the depth of the DLN.
Can stable and accurate neural networks be computed? -- On the barriers of deep learning and Smale's 18th problem
Jan 20, 2021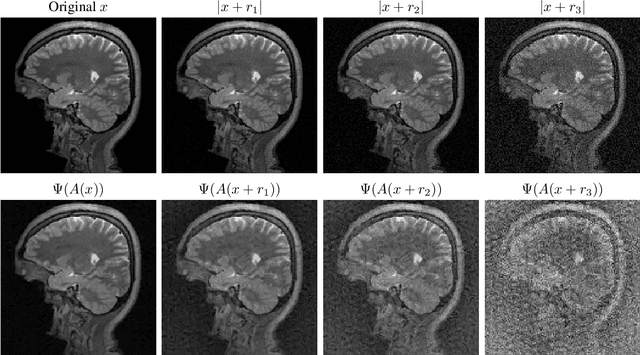

Deep learning (DL) has had unprecedented success and is now entering scientific computing with full force. However, DL suffers from a universal phenomenon: instability, despite universal approximating properties that often guarantee the existence of stable neural networks (NNs). We show the following paradox. There are basic well-conditioned problems in scientific computing where one can prove the existence of NNs with great approximation qualities, however, there does not exist any algorithm, even randomised, that can train (or compute) such a NN. Indeed, for any positive integers $K > 2$ and $L$, there are cases where simultaneously: (a) no randomised algorithm can compute a NN correct to $K$ digits with probability greater than $1/2$, (b) there exists a deterministic algorithm that computes a NN with $K-1$ correct digits, but any such (even randomised) algorithm needs arbitrarily many training data, (c) there exists a deterministic algorithm that computes a NN with $K-2$ correct digits using no more than $L$ training samples. These results provide basic foundations for Smale's 18th problem and imply a potentially vast, and crucial, classification theory describing conditions under which (stable) NNs with a given accuracy can be computed by an algorithm. We begin this theory by initiating a unified theory for compressed sensing and DL, leading to sufficient conditions for the existence of algorithms that compute stable NNs in inverse problems. We introduce Fast Iterative REstarted NETworks (FIRENETs), which we prove and numerically verify are stable. Moreover, we prove that only $\mathcal{O}(|\log(\epsilon)|)$ layers are needed for an $\epsilon$ accurate solution to the inverse problem (exponential convergence), and that the inner dimensions in the layers do not exceed the dimension of the inverse problem. Thus, FIRENETs are computationally very efficient.
The troublesome kernel: why deep learning for inverse problems is typically unstable
Jan 05, 2020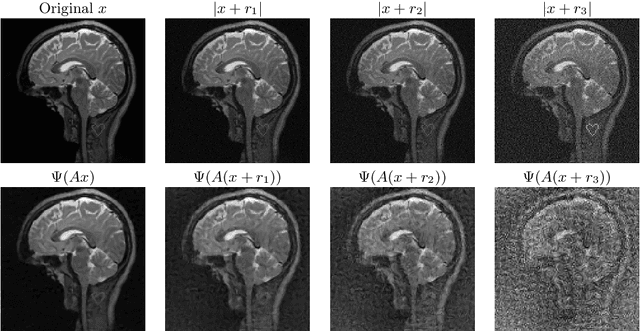

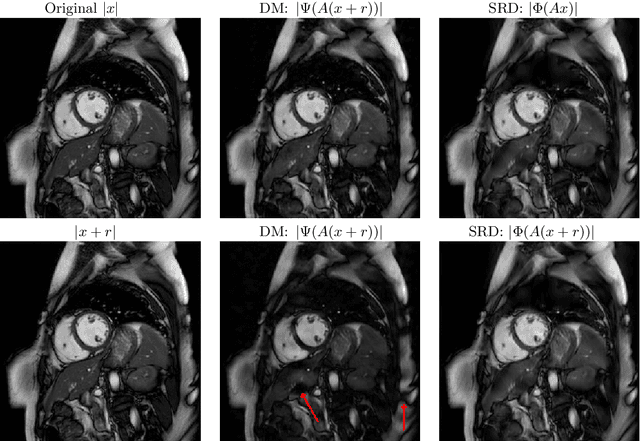
There is overwhelming empirical evidence that Deep Learning (DL) leads to unstable methods in applications ranging from image classification and computer vision to voice recognition and automated diagnosis in medicine. Recently, a similar instability phenomenon has been discovered when DL is used to solve certain problems in computational science, namely, inverse problems in imaging. In this paper we present a comprehensive mathematical analysis explaining the many facets of the instability phenomenon in DL for inverse problems. Our main results not only explain why this phenomenon occurs, they also shed light as to why finding a cure for instabilities is so difficult in practice. Additionally, these theorems show that instabilities are typically not rare events - rather, they can occur even when the measurements are subject to completely random noise - and consequently how easy it can be to destablise certain trained neural networks. We also examine the delicate balance between reconstruction performance and stability, and in particular, how DL methods may outperform state-of-the-art sparse regularization methods, but at the cost of instability. Finally, we demonstrate a counterintuitive phenomenon: training a neural network may generically not yield an optimal reconstruction method for an inverse problem.
What do AI algorithms actually learn? - On false structures in deep learning
Jun 04, 2019

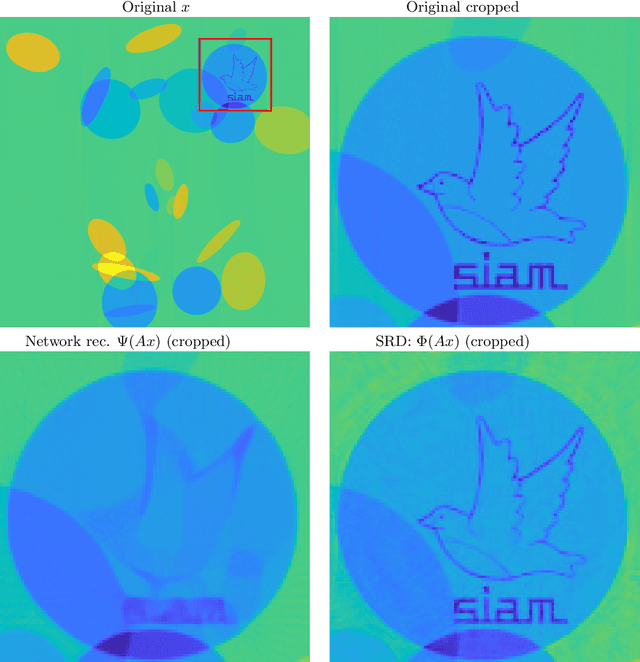
There are two big unsolved mathematical questions in artificial intelligence (AI): (1) Why is deep learning so successful in classification problems and (2) why are neural nets based on deep learning at the same time universally unstable, where the instabilities make the networks vulnerable to adversarial attacks. We present a solution to these questions that can be summed up in two words; false structures. Indeed, deep learning does not learn the original structures that humans use when recognising images (cats have whiskers, paws, fur, pointy ears, etc), but rather different false structures that correlate with the original structure and hence yield the success. However, the false structure, unlike the original structure, is unstable. The false structure is simpler than the original structure, hence easier to learn with less data and the numerical algorithm used in the training will more easily converge to the neural network that captures the false structure. We formally define the concept of false structures and formulate the solution as a conjecture. Given that trained neural networks always are computed with approximations, this conjecture can only be established through a combination of theoretical and computational results similar to how one establishes a postulate in theoretical physics (e.g. the speed of light is constant). Establishing the conjecture fully will require a vast research program characterising the false structures. We provide the foundations for such a program establishing the existence of the false structures in practice. Finally, we discuss the far reaching consequences the existence of the false structures has on state-of-the-art AI and Smale's 18th problem.
On instabilities of deep learning in image reconstruction - Does AI come at a cost?
Feb 14, 2019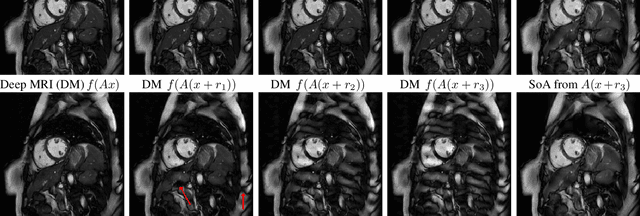
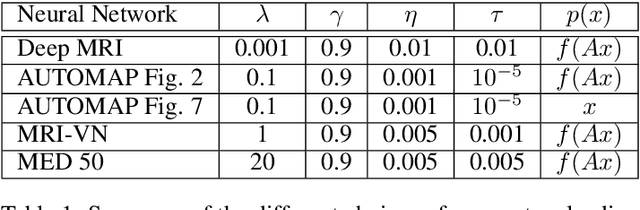
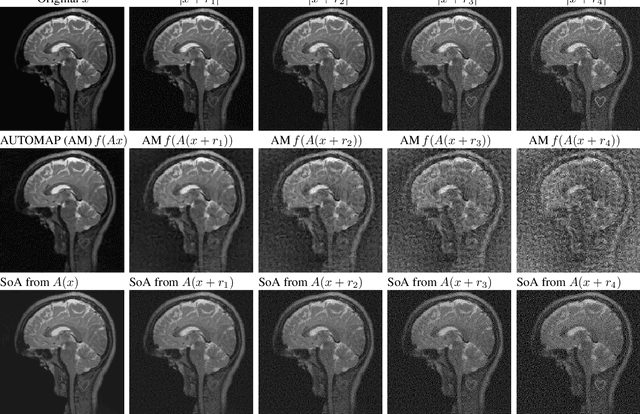
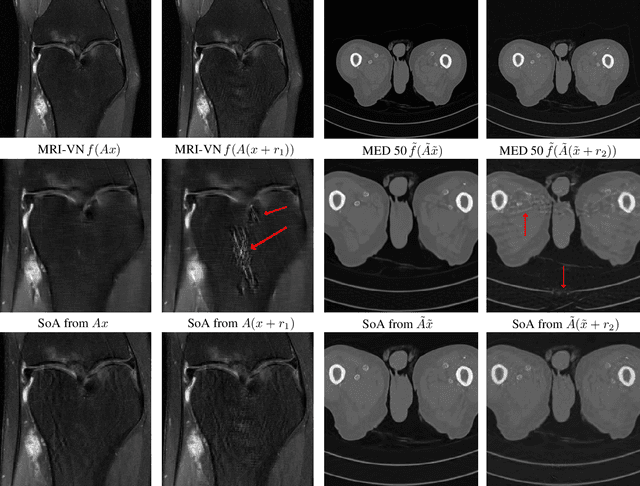
Deep learning, due to its unprecedented success in tasks such as image classification, has emerged as a new tool in image reconstruction with potential to change the field. In this paper we demonstrate a crucial phenomenon: deep learning typically yields unstablemethods for image reconstruction. The instabilities usually occur in several forms: (1) tiny, almost undetectable perturbations, both in the image and sampling domain, may result in severe artefacts in the reconstruction, (2) a small structural change, for example a tumour, may not be captured in the reconstructed image and (3) (a counterintuitive type of instability) more samples may yield poorer performance. Our new stability test with algorithms and easy to use software detects the instability phenomena. The test is aimed at researchers to test their networks for instabilities and for government agencies, such as the Food and Drug Administration (FDA), to secure safe use of deep learning methods.