 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Data Efficient Neural Networks with Hybrid Concept-based Models
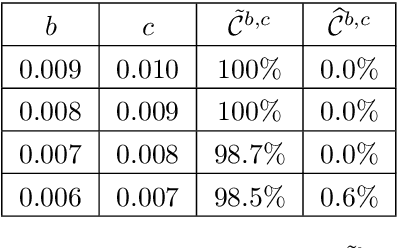
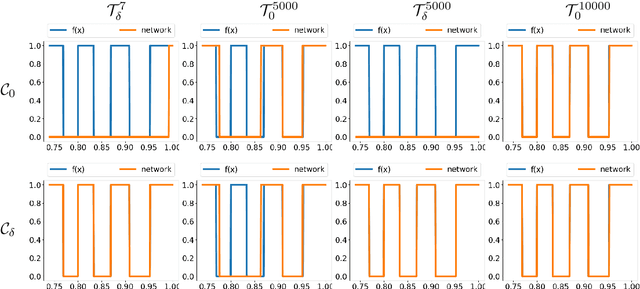
Aug 14, 2024Most datasets used for supervised machine learning consist of a single label per data point. However, in cases where more information than just the class label is available, would it be possible to train models more efficiently? We introduce two novel model architectures, which we call hybrid concept-based models, that train using both class labels and additional information in the dataset referred to as concepts. In order to thoroughly assess their performance, we introduce ConceptShapes, an open and flexible class of datasets with concept labels. We show that the hybrid concept-based models outperform standard computer vision models and previously proposed concept-based models with respect to accuracy, especially in sparse data settings. We also introduce an algorithm for performing adversarial concept attacks, where an image is perturbed in a way that does not change a concept-based model's concept predictions, but changes the class prediction. The existence of such adversarial examples raises questions about the interpretable qualities promised by concept-based models.
Implicit regularization in AI meets generalized hardness of approximation in optimization -- Sharp results for diagonal linear networks
Jul 13, 2023Understanding the implicit regularization imposed by neural network architectures and gradient based optimization methods is a key challenge in deep learning and AI. In this work we provide sharp results for the implicit regularization imposed by the gradient flow of Diagonal Linear Networks (DLNs) in the over-parameterized regression setting and, potentially surprisingly, link this to the phenomenon of phase transitions in generalized hardness of approximation (GHA). GHA generalizes the phenomenon of hardness of approximation from computer science to, among others, continuous and robust optimization. It is well-known that the $\ell^1$-norm of the gradient flow of DLNs with tiny initialization converges to the objective function of basis pursuit. We improve upon these results by showing that the gradient flow of DLNs with tiny initialization approximates minimizers of the basis pursuit optimization problem (as opposed to just the objective function), and we obtain new and sharp convergence bounds w.r.t.\ the initialization size. Non-sharpness of our results would imply that the GHA phenomenon would not occur for the basis pursuit optimization problem -- which is a contradiction -- thus implying sharpness. Moreover, we characterize $\textit{which}$ $\ell_1$ minimizer of the basis pursuit problem is chosen by the gradient flow whenever the minimizer is not unique. Interestingly, this depends on the depth of the DLN.
Can stable and accurate neural networks be computed? -- On the barriers of deep learning and Smale's 18th problem
Jan 20, 2021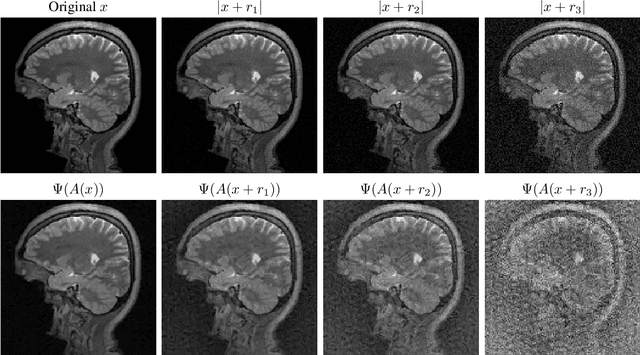
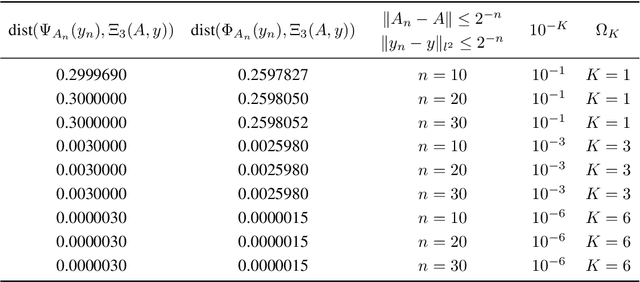
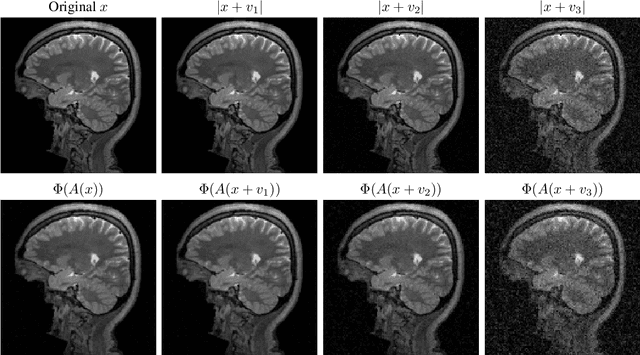

Deep learning (DL) has had unprecedented success and is now entering scientific computing with full force. However, DL suffers from a universal phenomenon: instability, despite universal approximating properties that often guarantee the existence of stable neural networks (NNs). We show the following paradox. There are basic well-conditioned problems in scientific computing where one can prove the existence of NNs with great approximation qualities, however, there does not exist any algorithm, even randomised, that can train (or compute) such a NN. Indeed, for any positive integers $K > 2$ and $L$, there are cases where simultaneously: (a) no randomised algorithm can compute a NN correct to $K$ digits with probability greater than $1/2$, (b) there exists a deterministic algorithm that computes a NN with $K-1$ correct digits, but any such (even randomised) algorithm needs arbitrarily many training data, (c) there exists a deterministic algorithm that computes a NN with $K-2$ correct digits using no more than $L$ training samples. These results provide basic foundations for Smale's 18th problem and imply a potentially vast, and crucial, classification theory describing conditions under which (stable) NNs with a given accuracy can be computed by an algorithm. We begin this theory by initiating a unified theory for compressed sensing and DL, leading to sufficient conditions for the existence of algorithms that compute stable NNs in inverse problems. We introduce Fast Iterative REstarted NETworks (FIRENETs), which we prove and numerically verify are stable. Moreover, we prove that only $\mathcal{O}(|\log(\epsilon)|)$ layers are needed for an $\epsilon$ accurate solution to the inverse problem (exponential convergence), and that the inner dimensions in the layers do not exceed the dimension of the inverse problem. Thus, FIRENETs are computationally very efficient.
The troublesome kernel: why deep learning for inverse problems is typically unstable
Jan 05, 2020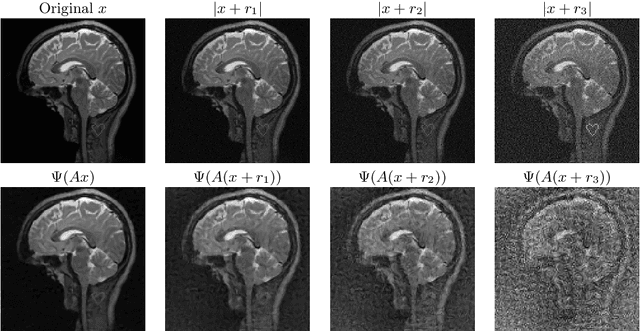

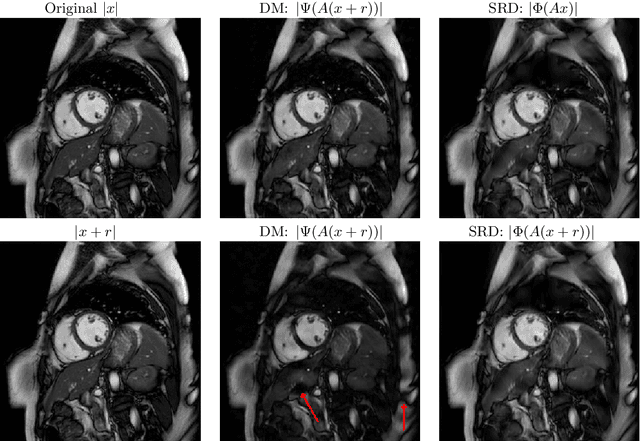
There is overwhelming empirical evidence that Deep Learning (DL) leads to unstable methods in applications ranging from image classification and computer vision to voice recognition and automated diagnosis in medicine. Recently, a similar instability phenomenon has been discovered when DL is used to solve certain problems in computational science, namely, inverse problems in imaging. In this paper we present a comprehensive mathematical analysis explaining the many facets of the instability phenomenon in DL for inverse problems. Our main results not only explain why this phenomenon occurs, they also shed light as to why finding a cure for instabilities is so difficult in practice. Additionally, these theorems show that instabilities are typically not rare events - rather, they can occur even when the measurements are subject to completely random noise - and consequently how easy it can be to destablise certain trained neural networks. We also examine the delicate balance between reconstruction performance and stability, and in particular, how DL methods may outperform state-of-the-art sparse regularization methods, but at the cost of instability. Finally, we demonstrate a counterintuitive phenomenon: training a neural network may generically not yield an optimal reconstruction method for an inverse problem.
What do AI algorithms actually learn? - On false structures in deep learning
Jun 04, 2019

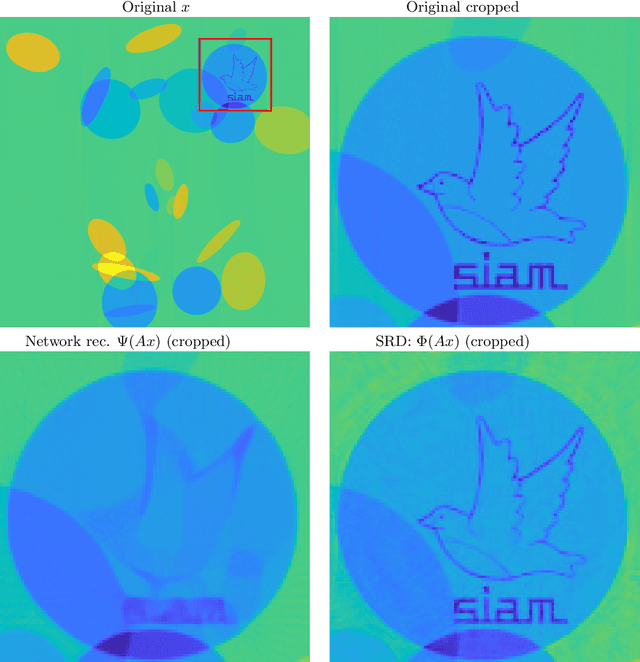
There are two big unsolved mathematical questions in artificial intelligence (AI): (1) Why is deep learning so successful in classification problems and (2) why are neural nets based on deep learning at the same time universally unstable, where the instabilities make the networks vulnerable to adversarial attacks. We present a solution to these questions that can be summed up in two words; false structures. Indeed, deep learning does not learn the original structures that humans use when recognising images (cats have whiskers, paws, fur, pointy ears, etc), but rather different false structures that correlate with the original structure and hence yield the success. However, the false structure, unlike the original structure, is unstable. The false structure is simpler than the original structure, hence easier to learn with less data and the numerical algorithm used in the training will more easily converge to the neural network that captures the false structure. We formally define the concept of false structures and formulate the solution as a conjecture. Given that trained neural networks always are computed with approximations, this conjecture can only be established through a combination of theoretical and computational results similar to how one establishes a postulate in theoretical physics (e.g. the speed of light is constant). Establishing the conjecture fully will require a vast research program characterising the false structures. We provide the foundations for such a program establishing the existence of the false structures in practice. Finally, we discuss the far reaching consequences the existence of the false structures has on state-of-the-art AI and Smale's 18th problem.
On instabilities of deep learning in image reconstruction - Does AI come at a cost?
Feb 14, 2019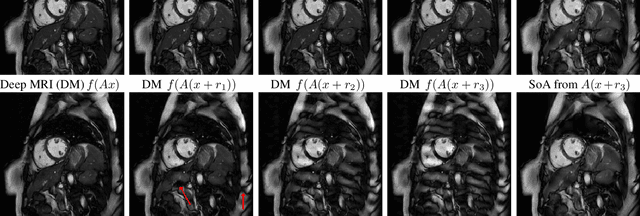
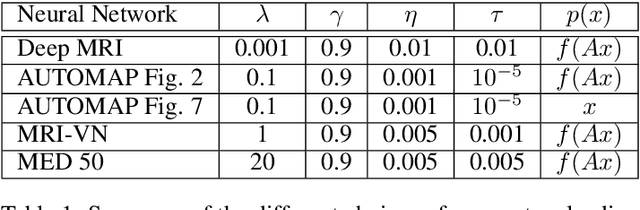
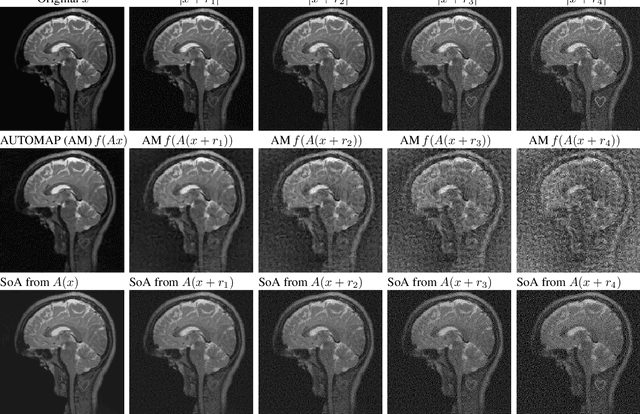
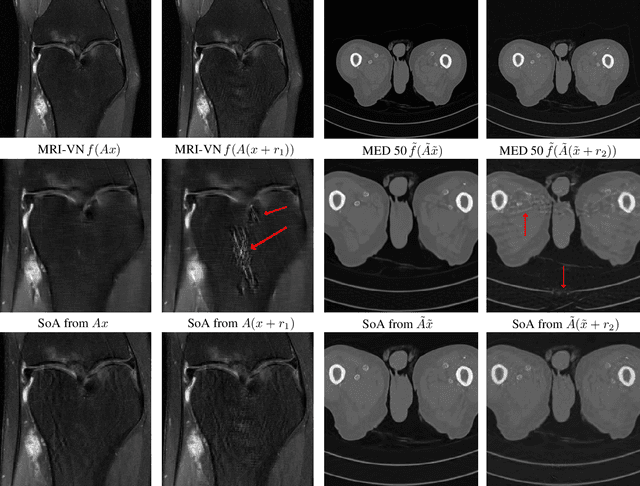
Deep learning, due to its unprecedented success in tasks such as image classification, has emerged as a new tool in image reconstruction with potential to change the field. In this paper we demonstrate a crucial phenomenon: deep learning typically yields unstablemethods for image reconstruction. The instabilities usually occur in several forms: (1) tiny, almost undetectable perturbations, both in the image and sampling domain, may result in severe artefacts in the reconstruction, (2) a small structural change, for example a tumour, may not be captured in the reconstructed image and (3) (a counterintuitive type of instability) more samples may yield poorer performance. Our new stability test with algorithms and easy to use software detects the instability phenomena. The test is aimed at researchers to test their networks for instabilities and for government agencies, such as the Food and Drug Administration (FDA), to secure safe use of deep learning methods.