 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSumformer: Universal Approximation for Efficient Transformers
Jul 05, 2023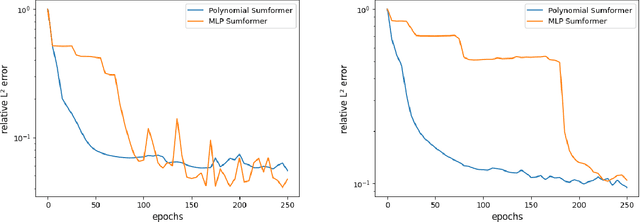
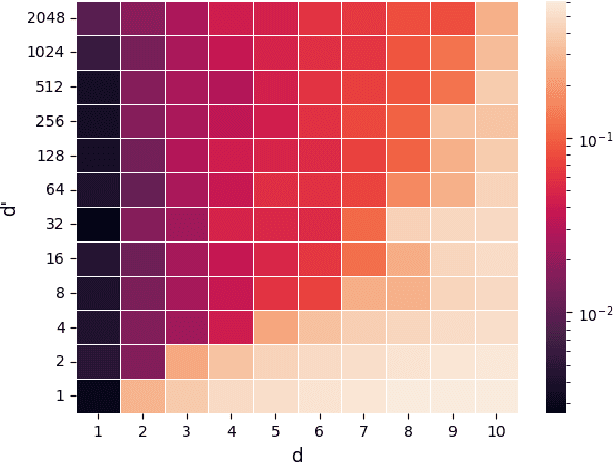
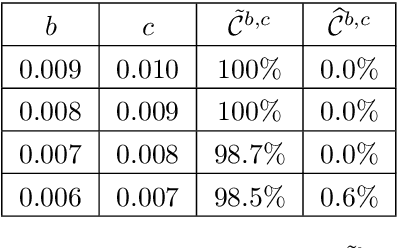
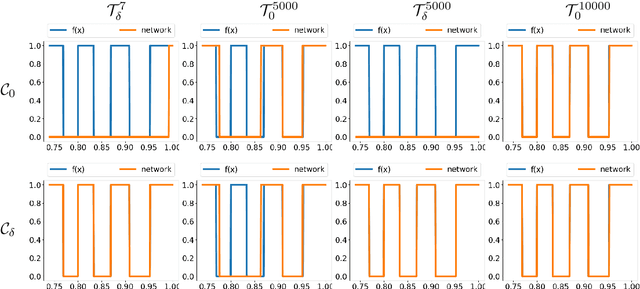
Natural language processing (NLP) made an impressive jump with the introduction of Transformers. ChatGPT is one of the most famous examples, changing the perception of the possibilities of AI even outside the research community. However, besides the impressive performance, the quadratic time and space complexity of Transformers with respect to sequence length pose significant limitations for handling long sequences. While efficient Transformer architectures like Linformer and Performer with linear complexity have emerged as promising solutions, their theoretical understanding remains limited. In this paper, we introduce Sumformer, a novel and simple architecture capable of universally approximating equivariant sequence-to-sequence functions. We use Sumformer to give the first universal approximation results for Linformer and Performer. Moreover, we derive a new proof for Transformers, showing that just one attention layer is sufficient for universal approximation.
What do AI algorithms actually learn? - On false structures in deep learning
Jun 04, 2019

There are two big unsolved mathematical questions in artificial intelligence (AI): (1) Why is deep learning so successful in classification problems and (2) why are neural nets based on deep learning at the same time universally unstable, where the instabilities make the networks vulnerable to adversarial attacks. We present a solution to these questions that can be summed up in two words; false structures. Indeed, deep learning does not learn the original structures that humans use when recognising images (cats have whiskers, paws, fur, pointy ears, etc), but rather different false structures that correlate with the original structure and hence yield the success. However, the false structure, unlike the original structure, is unstable. The false structure is simpler than the original structure, hence easier to learn with less data and the numerical algorithm used in the training will more easily converge to the neural network that captures the false structure. We formally define the concept of false structures and formulate the solution as a conjecture. Given that trained neural networks always are computed with approximations, this conjecture can only be established through a combination of theoretical and computational results similar to how one establishes a postulate in theoretical physics (e.g. the speed of light is constant). Establishing the conjecture fully will require a vast research program characterising the false structures. We provide the foundations for such a program establishing the existence of the false structures in practice. Finally, we discuss the far reaching consequences the existence of the false structures has on state-of-the-art AI and Smale's 18th problem.
The Oracle of DLphi
Jan 27, 2019We present a novel technique based on deep learning and set theory which yields exceptional classification and prediction results. Having access to a sufficiently large amount of labelled training data, our methodology is capable of predicting the labels of the test data almost always even if the training data is entirely unrelated to the test data. In other words, we prove in a specific setting that as long as one has access to enough data points, the quality of the data is irrelevant.