 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal deep learning of holomorphic operators between Banach spaces
Jun 20, 2024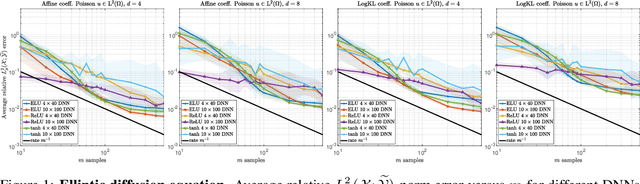
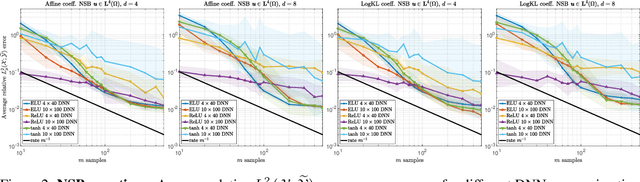
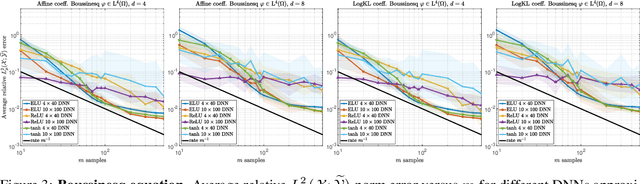
Operator learning problems arise in many key areas of scientific computing where Partial Differential Equations (PDEs) are used to model physical systems. In such scenarios, the operators map between Banach or Hilbert spaces. In this work, we tackle the problem of learning operators between Banach spaces, in contrast to the vast majority of past works considering only Hilbert spaces. We focus on learning holomorphic operators - an important class of problems with many applications. We combine arbitrary approximate encoders and decoders with standard feedforward Deep Neural Network (DNN) architectures - specifically, those with constant width exceeding the depth - under standard $\ell^2$-loss minimization. We first identify a family of DNNs such that the resulting Deep Learning (DL) procedure achieves optimal generalization bounds for such operators. For standard fully-connected architectures, we then show that there are uncountably many minimizers of the training problem that yield equivalent optimal performance. The DNN architectures we consider are `problem agnostic', with width and depth only depending on the amount of training data $m$ and not on regularity assumptions of the target operator. Next, we show that DL is optimal for this problem: no recovery procedure can surpass these generalization bounds up to log terms. Finally, we present numerical results demonstrating the practical performance on challenging problems including the parametric diffusion, Navier-Stokes-Brinkman and Boussinesq PDEs.
Learning smooth functions in high dimensions: from sparse polynomials to deep neural networks
Apr 04, 2024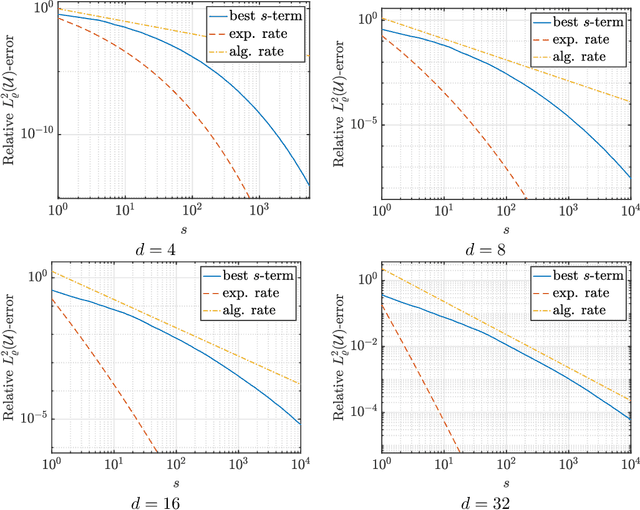
Learning approximations to smooth target functions of many variables from finite sets of pointwise samples is an important task in scientific computing and its many applications in computational science and engineering. Despite well over half a century of research on high-dimensional approximation, this remains a challenging problem. Yet, significant advances have been made in the last decade towards efficient methods for doing this, commencing with so-called sparse polynomial approximation methods and continuing most recently with methods based on Deep Neural Networks (DNNs). In tandem, there have been substantial advances in the relevant approximation theory and analysis of these techniques. In this work, we survey this recent progress. We describe the contemporary motivations for this problem, which stem from parametric models and computational uncertainty quantification; the relevant function classes, namely, classes of infinite-dimensional, Banach-valued, holomorphic functions; fundamental limits of learnability from finite data for these classes; and finally, sparse polynomial and DNN methods for efficiently learning such functions from finite data. For the latter, there is currently a significant gap between the approximation theory of DNNs and the practical performance of deep learning. Aiming to narrow this gap, we develop the topic of practical existence theory, which asserts the existence of dimension-independent DNN architectures and training strategies that achieve provably near-optimal generalization errors in terms of the amount of training data.
On efficient algorithms for computing near-best polynomial approximations to high-dimensional, Hilbert-valued functions from limited samples
Mar 25, 2022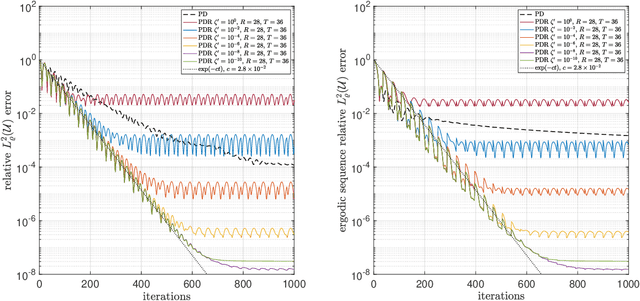

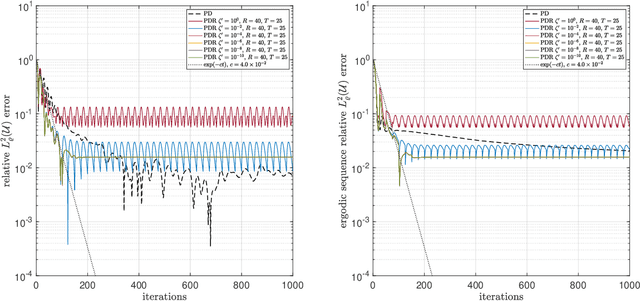

Sparse polynomial approximation has become indispensable for approximating smooth, high- or infinite-dimensional functions from limited samples. This is a key task in computational science and engineering, e.g., surrogate modelling in UQ where the function is the solution map of a parametric or stochastic PDE. Yet, sparse polynomial approximation lacks a complete theory. On the one hand, there is a well-developed theory of best $s$-term polynomial approximation, which asserts exponential or algebraic rates of convergence for holomorphic functions. On the other hand, there are increasingly mature methods such as (weighted) $\ell^1$-minimization for computing such approximations. While the sample complexity of these methods has been analyzed in detail, the matter of whether or not these methods achieve such rates is not well understood. Furthermore, these methods are not algorithms per se, since they involve exact minimizers of nonlinear optimization problems. This paper closes these gaps. Specifically, we pose and answer the following question: are there robust, efficient algorithms for computing approximations to finite- or infinite-dimensional, holomorphic and Hilbert-valued functions from limited samples that achieve best $s$-term rates? We answer this in the affirmative by introducing algorithms and theoretical guarantees that assert exponential or algebraic rates of convergence, along with robustness to sampling, algorithmic, and physical discretization errors. We tackle both scalar- and Hilbert-valued functions, this being particularly relevant to parametric and stochastic PDEs. Our work involves several significant developments of existing techniques, including a novel restarted primal-dual iteration for solving weighted $\ell^1$-minimization problems in Hilbert spaces. Our theory is supplemented by numerical experiments demonstrating the practical efficacy of these algorithms.
Deep Neural Networks Are Effective At Learning High-Dimensional Hilbert-Valued Functions From Limited Data
Dec 11, 2020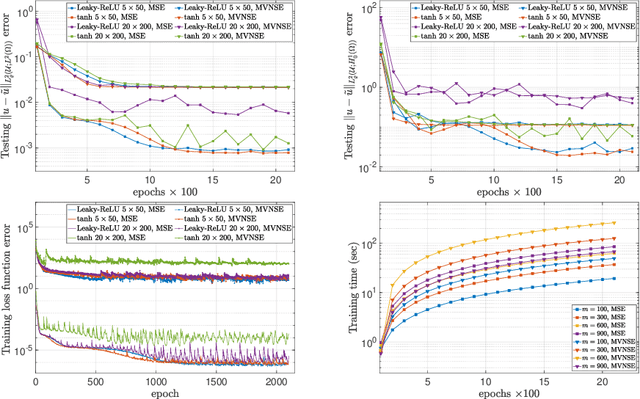
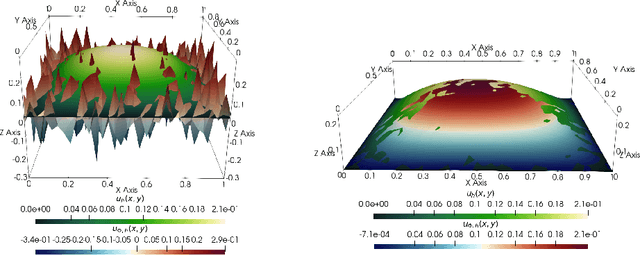
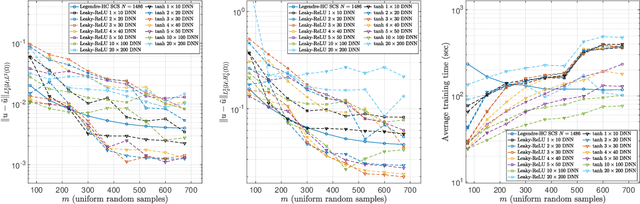
The accurate approximation of scalar-valued functions from sample points is a key task in mathematical modeling and computational science. Recently, machine learning techniques based on Deep Neural Networks (DNNs) have begun to emerge as promising tools for function approximation in scientific computing problems, with impressive results achieved on problems where the dimension of the underlying data or problem domain is large. In this work, we broaden this perspective by focusing on approximation of functions that are Hilbert-valued, i.e. they take values in a separable, but typically infinite-dimensional, Hilbert space. This problem arises in many science and engineering problems, in particular those involving the solution of parametric Partial Differential Equations (PDEs). Such problems are challenging for three reasons. First, pointwise samples are expensive to acquire. Second, the domain of the function is usually high dimensional, and third, the range lies in a Hilbert space. Our contributions are twofold. First, we present a novel result on DNN training for holomorphic functions with so-called hidden anisotropy. This result introduces a DNN training procedure and a full theoretical analysis with explicit guarantees on the error and sample complexity. This error bound is explicit in the three key errors occurred in the approximation procedure: best approximation error, measurement error and physical discretization error. Our result shows that there is a procedure for learning Hilbert-valued functions via DNNs that performs as well as current best-in-class schemes. Second, we provide preliminary numerical results illustrating the practical performance of DNNs on Hilbert-valued functions arising as solutions to parametric PDEs. We consider different parameters, modify the DNN architecture to achieve better and competitive results and compare these to current best-in-class schemes.