 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn efficient algorithms for computing near-best polynomial approximations to high-dimensional, Hilbert-valued functions from limited samples
Paper and Code
Mar 25, 2022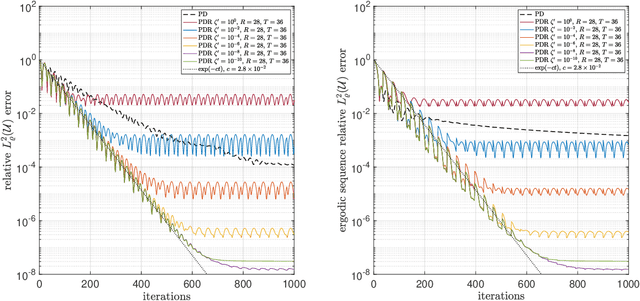

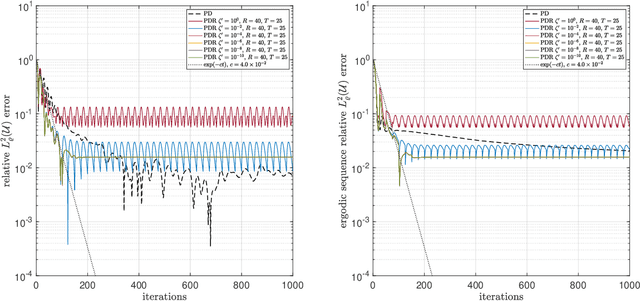

Sparse polynomial approximation has become indispensable for approximating smooth, high- or infinite-dimensional functions from limited samples. This is a key task in computational science and engineering, e.g., surrogate modelling in UQ where the function is the solution map of a parametric or stochastic PDE. Yet, sparse polynomial approximation lacks a complete theory. On the one hand, there is a well-developed theory of best $s$-term polynomial approximation, which asserts exponential or algebraic rates of convergence for holomorphic functions. On the other hand, there are increasingly mature methods such as (weighted) $\ell^1$-minimization for computing such approximations. While the sample complexity of these methods has been analyzed in detail, the matter of whether or not these methods achieve such rates is not well understood. Furthermore, these methods are not algorithms per se, since they involve exact minimizers of nonlinear optimization problems. This paper closes these gaps. Specifically, we pose and answer the following question: are there robust, efficient algorithms for computing approximations to finite- or infinite-dimensional, holomorphic and Hilbert-valued functions from limited samples that achieve best $s$-term rates? We answer this in the affirmative by introducing algorithms and theoretical guarantees that assert exponential or algebraic rates of convergence, along with robustness to sampling, algorithmic, and physical discretization errors. We tackle both scalar- and Hilbert-valued functions, this being particularly relevant to parametric and stochastic PDEs. Our work involves several significant developments of existing techniques, including a novel restarted primal-dual iteration for solving weighted $\ell^1$-minimization problems in Hilbert spaces. Our theory is supplemented by numerical experiments demonstrating the practical efficacy of these algorithms.