 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Implicit ODE Solvers for Accelerating Learning Neural ODEs
Apr 19, 2022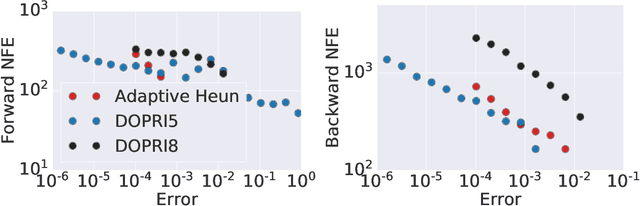

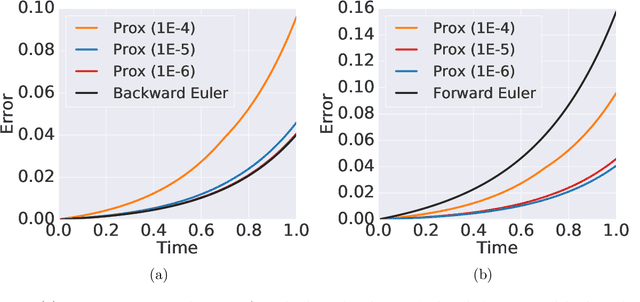

Learning neural ODEs often requires solving very stiff ODE systems, primarily using explicit adaptive step size ODE solvers. These solvers are computationally expensive, requiring the use of tiny step sizes for numerical stability and accuracy guarantees. This paper considers learning neural ODEs using implicit ODE solvers of different orders leveraging proximal operators. The proximal implicit solver consists of inner-outer iterations: the inner iterations approximate each implicit update step using a fast optimization algorithm, and the outer iterations solve the ODE system over time. The proximal implicit ODE solver guarantees superiority over explicit solvers in numerical stability and computational efficiency. We validate the advantages of proximal implicit solvers over existing popular neural ODE solvers on various challenging benchmark tasks, including learning continuous-depth graph neural networks and continuous normalizing flows.
How Does Momentum Benefit Deep Neural Networks Architecture Design? A Few Case Studies
Oct 19, 2021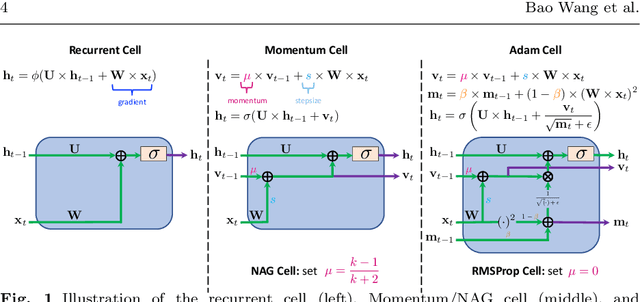
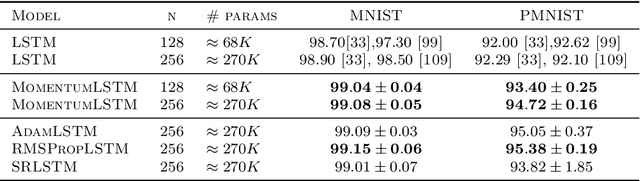
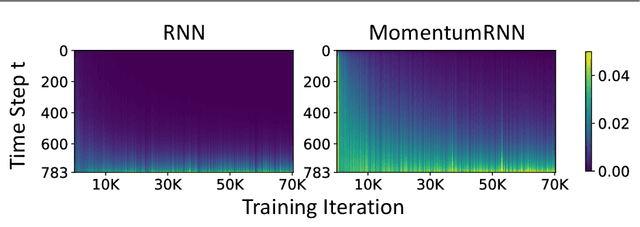
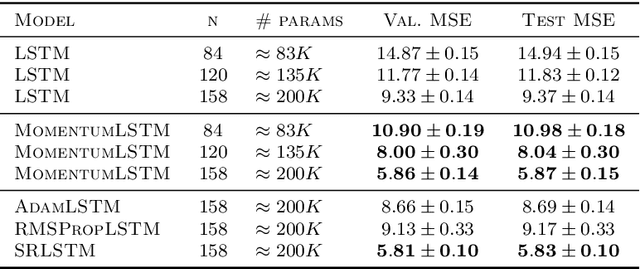
We present and review an algorithmic and theoretical framework for improving neural network architecture design via momentum. As case studies, we consider how momentum can improve the architecture design for recurrent neural networks (RNNs), neural ordinary differential equations (ODEs), and transformers. We show that integrating momentum into neural network architectures has several remarkable theoretical and empirical benefits, including 1) integrating momentum into RNNs and neural ODEs can overcome the vanishing gradient issues in training RNNs and neural ODEs, resulting in effective learning long-term dependencies. 2) momentum in neural ODEs can reduce the stiffness of the ODE dynamics, which significantly enhances the computational efficiency in training and testing. 3) momentum can improve the efficiency and accuracy of transformers.
Heavy Ball Neural Ordinary Differential Equations
Oct 10, 2021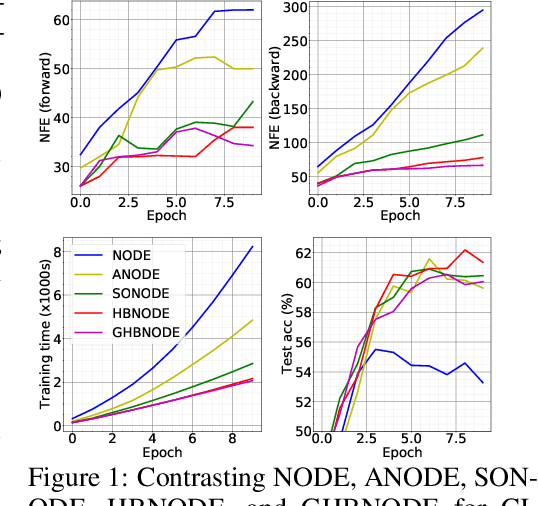

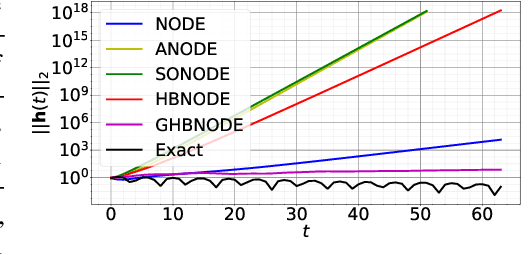
We propose heavy ball neural ordinary differential equations (HBNODEs), leveraging the continuous limit of the classical momentum accelerated gradient descent, to improve neural ODEs (NODEs) training and inference. HBNODEs have two properties that imply practical advantages over NODEs: (i) The adjoint state of an HBNODE also satisfies an HBNODE, accelerating both forward and backward ODE solvers, thus significantly reducing the number of function evaluations (NFEs) and improving the utility of the trained models. (ii) The spectrum of HBNODEs is well structured, enabling effective learning of long-term dependencies from complex sequential data. We verify the advantages of HBNODEs over NODEs on benchmark tasks, including image classification, learning complex dynamics, and sequential modeling. Our method requires remarkably fewer forward and backward NFEs, is more accurate, and learns long-term dependencies more effectively than the other ODE-based neural network models. Code is available at \url{https://github.com/hedixia/HeavyBallNODE}.
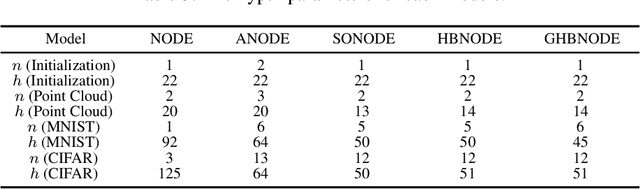
Kernel Treelets
Dec 12, 2018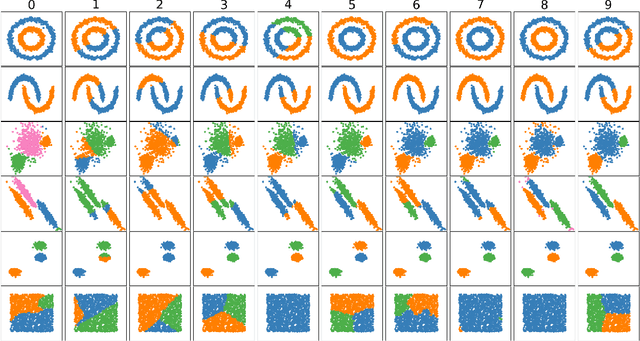
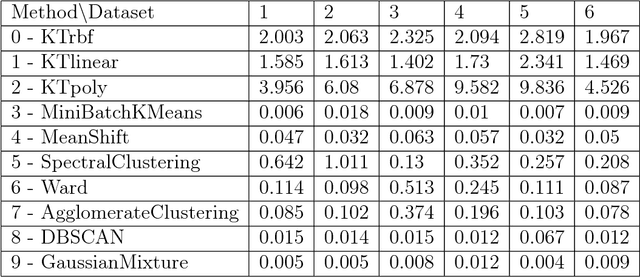
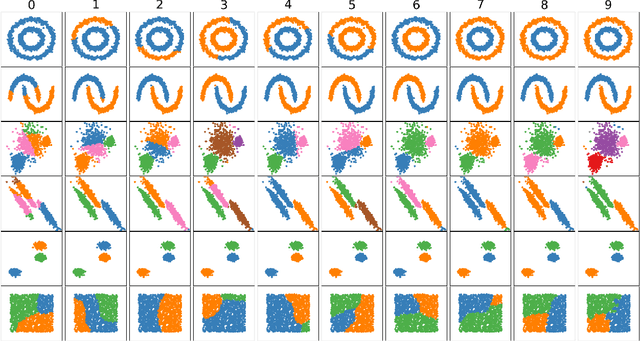
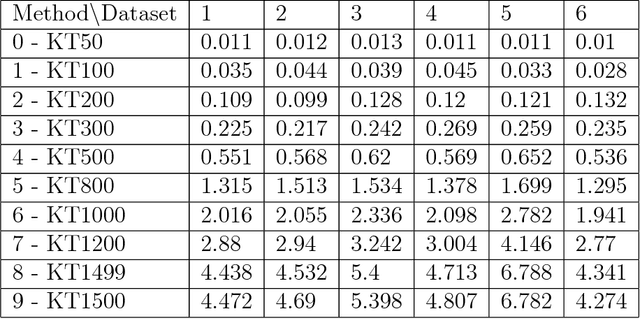
A new method for hierarchical clustering is presented. It combines treelets, a particular multiscale decomposition of data, with a projection on a reproducing kernel Hilbert space. The proposed approach, called kernel treelets (KT), effectively substitutes the correlation coefficient matrix used in treelets with a symmetric, positive semi-definite matrix efficiently constructed from a kernel function. Unlike most clustering methods, which require data sets to be numeric, KT can be applied to more general data and yield a multi-resolution sequence of basis on the data directly in feature space. The effectiveness and potential of KT in clustering analysis is illustrated with some examples.