 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Are Watermarks in LLMs Ready for Deployment?
Jun 05, 2025Large Language Models (LLMs) have transformed natural language processing, demonstrating impressive capabilities across diverse tasks. However, deploying these models introduces critical risks related to intellectual property violations and potential misuse, particularly as adversaries can imitate these models to steal services or generate misleading outputs. We specifically focus on model stealing attacks, as they are highly relevant to proprietary LLMs and pose a serious threat to their security, revenue, and ethical deployment. While various watermarking techniques have emerged to mitigate these risks, it remains unclear how far the community and industry have progressed in developing and deploying watermarks in LLMs. To bridge this gap, we aim to develop a comprehensive systematization for watermarks in LLMs by 1) presenting a detailed taxonomy for watermarks in LLMs, 2) proposing a novel intellectual property classifier to explore the effectiveness and impacts of watermarks on LLMs under both attack and attack-free environments, 3) analyzing the limitations of existing watermarks in LLMs, and 4) discussing practical challenges and potential future directions for watermarks in LLMs. Through extensive experiments, we show that despite promising research outcomes and significant attention from leading companies and community to deploy watermarks, these techniques have yet to reach their full potential in real-world applications due to their unfavorable impacts on model utility of LLMs and downstream tasks. Our findings provide an insightful understanding of watermarks in LLMs, highlighting the need for practical watermarks solutions tailored to LLM deployment.
A Client-level Assessment of Collaborative Backdoor Poisoning in Non-IID Federated Learning
Apr 21, 2025Federated learning (FL) enables collaborative model training using decentralized private data from multiple clients. While FL has shown robustness against poisoning attacks with basic defenses, our research reveals new vulnerabilities stemming from non-independent and identically distributed (non-IID) data among clients. These vulnerabilities pose a substantial risk of model poisoning in real-world FL scenarios. To demonstrate such vulnerabilities, we develop a novel collaborative backdoor poisoning attack called CollaPois. In this attack, we distribute a single pre-trained model infected with a Trojan to a group of compromised clients. These clients then work together to produce malicious gradients, causing the FL model to consistently converge towards a low-loss region centered around the Trojan-infected model. Consequently, the impact of the Trojan is amplified, especially when the benign clients have diverse local data distributions and scattered local gradients. CollaPois stands out by achieving its goals while involving only a limited number of compromised clients, setting it apart from existing attacks. Also, CollaPois effectively avoids noticeable shifts or degradation in the FL model's performance on legitimate data samples, allowing it to operate stealthily and evade detection by advanced robust FL algorithms. Thorough theoretical analysis and experiments conducted on various benchmark datasets demonstrate the superiority of CollaPois compared to state-of-the-art backdoor attacks. Notably, CollaPois bypasses existing backdoor defenses, especially in scenarios where clients possess diverse data distributions. Moreover, the results show that CollaPois remains effective even when involving a small number of compromised clients. Notably, clients whose local data is closely aligned with compromised clients experience higher risks of backdoor infections.
FedX: Adaptive Model Decomposition and Quantization for IoT Federated Learning
Apr 19, 2025Federated Learning (FL) allows collaborative training among multiple devices without data sharing, thus enabling privacy-sensitive applications on mobile or Internet of Things (IoT) devices, such as mobile health and asset tracking. However, designing an FL system with good model utility that works with low computation/communication overhead on heterogeneous, resource-constrained mobile/IoT devices is challenging. To address this problem, this paper proposes FedX, a novel adaptive model decomposition and quantization FL system for IoT. To balance utility with resource constraints on IoT devices, FedX decomposes a global FL model into different sub-networks with adaptive numbers of quantized bits for different devices. The key idea is that a device with fewer resources receives a smaller sub-network for lower overhead but utilizes a larger number of quantized bits for higher model utility, and vice versa. The quantization operations in FedX are done at the server to reduce the computational load on devices. FedX iteratively minimizes the losses in the devices' local data and in the server's public data using quantized sub-networks under a regularization term, and thus it maximizes the benefits of combining FL with model quantization through knowledge sharing among the server and devices in a cost-effective training process. Extensive experiments show that FedX significantly improves quantization times by up to 8.43X, on-device computation time by 1.5X, and total end-to-end training time by 1.36X, compared with baseline FL systems. We guarantee the global model convergence theoretically and validate local model convergence empirically, highlighting FedX's optimization efficiency.
XSub: Explanation-Driven Adversarial Attack against Blackbox Classifiers via Feature Substitution
Sep 13, 2024Despite its significant benefits in enhancing the transparency and trustworthiness of artificial intelligence (AI) systems, explainable AI (XAI) has yet to reach its full potential in real-world applications. One key challenge is that XAI can unintentionally provide adversaries with insights into black-box models, inevitably increasing their vulnerability to various attacks. In this paper, we develop a novel explanation-driven adversarial attack against black-box classifiers based on feature substitution, called XSub. The key idea of XSub is to strategically replace important features (identified via XAI) in the original sample with corresponding important features from a "golden sample" of a different label, thereby increasing the likelihood of the model misclassifying the perturbed sample. The degree of feature substitution is adjustable, allowing us to control how much of the original samples information is replaced. This flexibility effectively balances a trade-off between the attacks effectiveness and its stealthiness. XSub is also highly cost-effective in that the number of required queries to the prediction model and the explanation model in conducting the attack is in O(1). In addition, XSub can be easily extended to launch backdoor attacks in case the attacker has access to the models training data. Our evaluation demonstrates that XSub is not only effective and stealthy but also cost-effective, enabling its application across a wide range of AI models.
Active Membership Inference Attack under Local Differential Privacy in Federated Learning
Feb 24, 2023Federated learning (FL) was originally regarded as a framework for collaborative learning among clients with data privacy protection through a coordinating server. In this paper, we propose a new active membership inference (AMI) attack carried out by a dishonest server in FL. In AMI attacks, the server crafts and embeds malicious parameters into global models to effectively infer whether a target data sample is included in a client's private training data or not. By exploiting the correlation among data features through a non-linear decision boundary, AMI attacks with a certified guarantee of success can achieve severely high success rates under rigorous local differential privacy (LDP) protection; thereby exposing clients' training data to significant privacy risk. Theoretical and experimental results on several benchmark datasets show that adding sufficient privacy-preserving noise to prevent our attack would significantly damage FL's model utility.
XRand: Differentially Private Defense against Explanation-Guided Attacks
Dec 14, 2022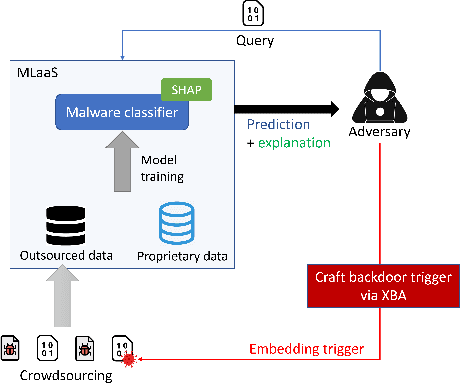
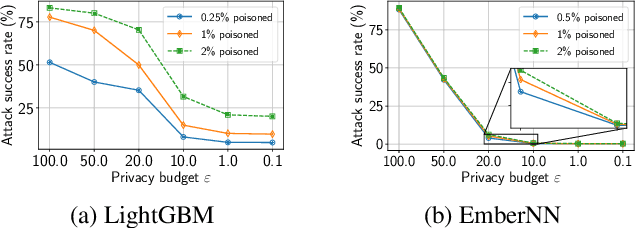
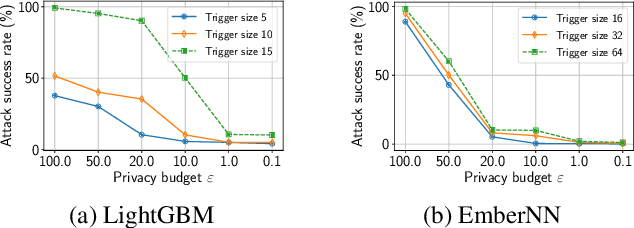
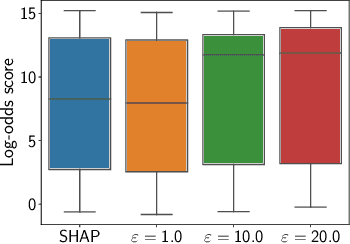
Recent development in the field of explainable artificial intelligence (XAI) has helped improve trust in Machine-Learning-as-a-Service (MLaaS) systems, in which an explanation is provided together with the model prediction in response to each query. However, XAI also opens a door for adversaries to gain insights into the black-box models in MLaaS, thereby making the models more vulnerable to several attacks. For example, feature-based explanations (e.g., SHAP) could expose the top important features that a black-box model focuses on. Such disclosure has been exploited to craft effective backdoor triggers against malware classifiers. To address this trade-off, we introduce a new concept of achieving local differential privacy (LDP) in the explanations, and from that we establish a defense, called XRand, against such attacks. We show that our mechanism restricts the information that the adversary can learn about the top important features, while maintaining the faithfulness of the explanations.
Heterogeneous Randomized Response for Differential Privacy in Graph Neural Networks
Nov 10, 2022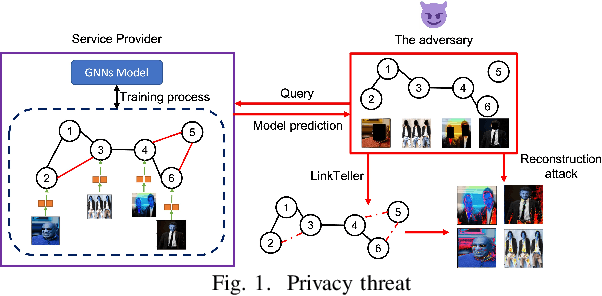
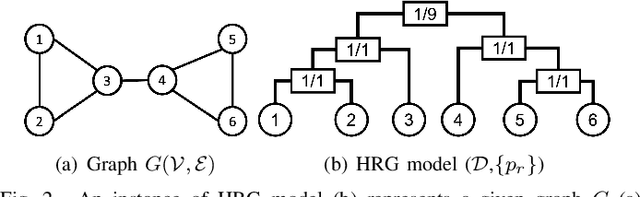
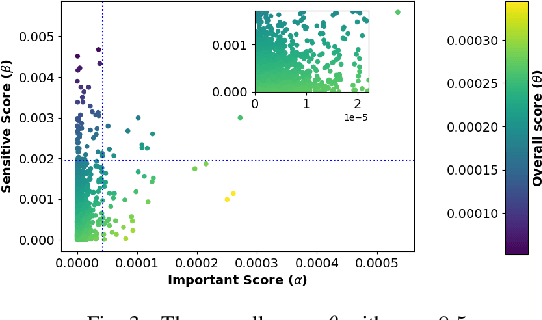
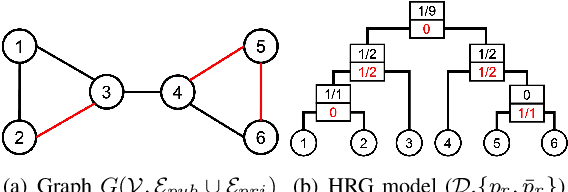
Graph neural networks (GNNs) are susceptible to privacy inference attacks (PIAs), given their ability to learn joint representation from features and edges among nodes in graph data. To prevent privacy leakages in GNNs, we propose a novel heterogeneous randomized response (HeteroRR) mechanism to protect nodes' features and edges against PIAs under differential privacy (DP) guarantees without an undue cost of data and model utility in training GNNs. Our idea is to balance the importance and sensitivity of nodes' features and edges in redistributing the privacy budgets since some features and edges are more sensitive or important to the model utility than others. As a result, we derive significantly better randomization probabilities and tighter error bounds at both levels of nodes' features and edges departing from existing approaches, thus enabling us to maintain high data utility for training GNNs. An extensive theoretical and empirical analysis using benchmark datasets shows that HeteroRR significantly outperforms various baselines in terms of model utility under rigorous privacy protection for both nodes' features and edges. That enables us to defend PIAs in DP-preserving GNNs effectively.
User-Entity Differential Privacy in Learning Natural Language Models
Nov 09, 2022In this paper, we introduce a novel concept of user-entity differential privacy (UeDP) to provide formal privacy protection simultaneously to both sensitive entities in textual data and data owners in learning natural language models (NLMs). To preserve UeDP, we developed a novel algorithm, called UeDP-Alg, optimizing the trade-off between privacy loss and model utility with a tight sensitivity bound derived from seamlessly combining user and sensitive entity sampling processes. An extensive theoretical analysis and evaluation show that our UeDP-Alg outperforms baseline approaches in model utility under the same privacy budget consumption on several NLM tasks, using benchmark datasets.
Lifelong DP: Consistently Bounded Differential Privacy in Lifelong Machine Learning
Jul 26, 2022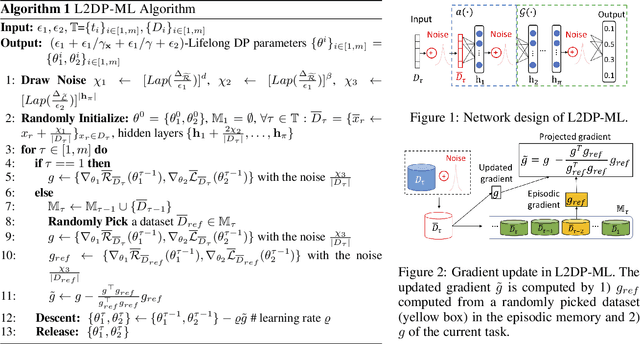
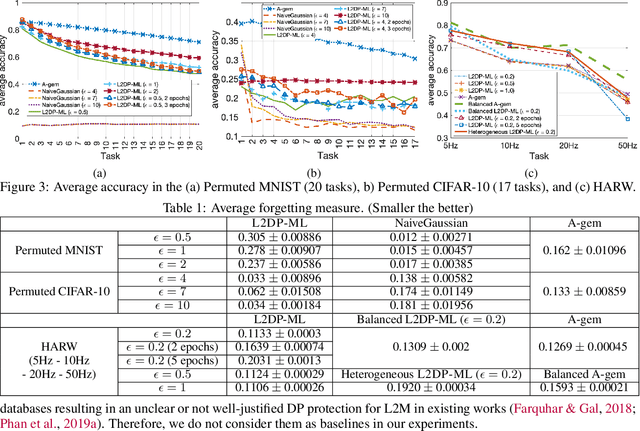
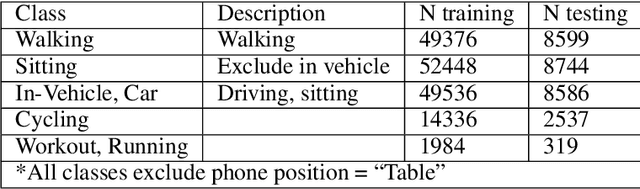
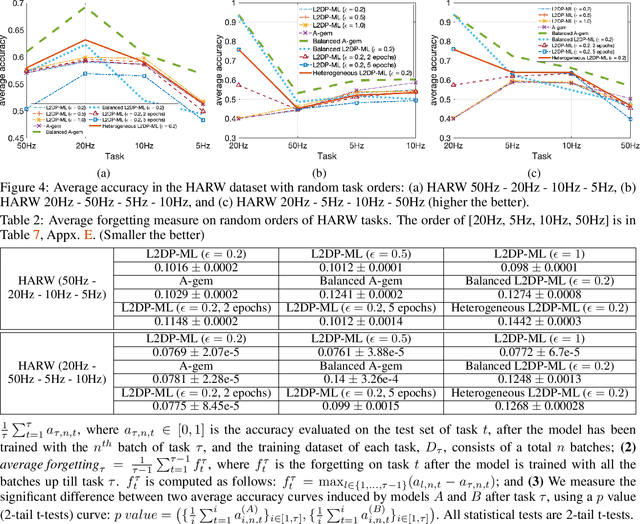
In this paper, we show that the process of continually learning new tasks and memorizing previous tasks introduces unknown privacy risks and challenges to bound the privacy loss. Based upon this, we introduce a formal definition of Lifelong DP, in which the participation of any data tuples in the training set of any tasks is protected, under a consistently bounded DP protection, given a growing stream of tasks. A consistently bounded DP means having only one fixed value of the DP privacy budget, regardless of the number of tasks. To preserve Lifelong DP, we propose a scalable and heterogeneous algorithm, called L2DP-ML with a streaming batch training, to efficiently train and continue releasing new versions of an L2M model, given the heterogeneity in terms of data sizes and the training order of tasks, without affecting DP protection of the private training set. An end-to-end theoretical analysis and thorough evaluations show that our mechanism is significantly better than baseline approaches in preserving Lifelong DP. The implementation of L2DP-ML is available at: https://github.com/haiphanNJIT/PrivateDeepLearning.
Model Transferring Attacks to Backdoor HyperNetwork in Personalized Federated Learning
Jan 19, 2022



This paper explores previously unknown backdoor risks in HyperNet-based personalized federated learning (HyperNetFL) through poisoning attacks. Based upon that, we propose a novel model transferring attack (called HNTROJ), i.e., the first of its kind, to transfer a local backdoor infected model to all legitimate and personalized local models, which are generated by the HyperNetFL model, through consistent and effective malicious local gradients computed across all compromised clients in the whole training process. As a result, HNTROJ reduces the number of compromised clients needed to successfully launch the attack without any observable signs of sudden shifts or degradation regarding model utility on legitimate data samples making our attack stealthy. To defend against HNTROJ, we adapted several backdoor-resistant FL training algorithms into HyperNetFL. An extensive experiment that is carried out using several benchmark datasets shows that HNTROJ significantly outperforms data poisoning and model replacement attacks and bypasses robust training algorithms.