 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Multi-View Query Learning for Short Text Classification in User-Generated Data
Dec 05, 2021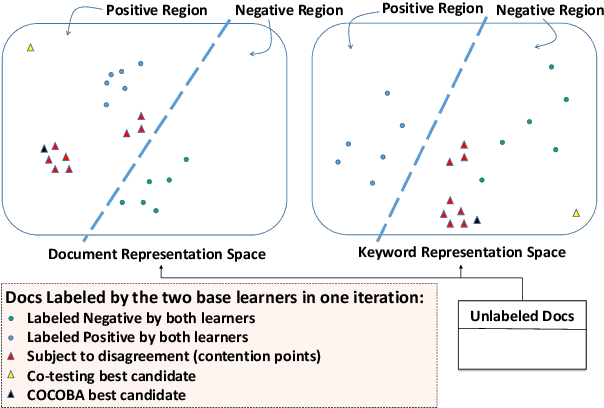
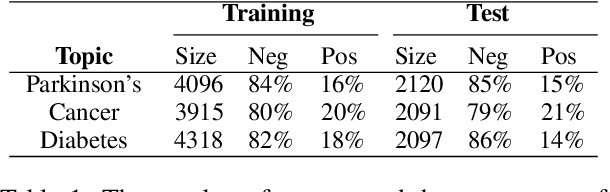
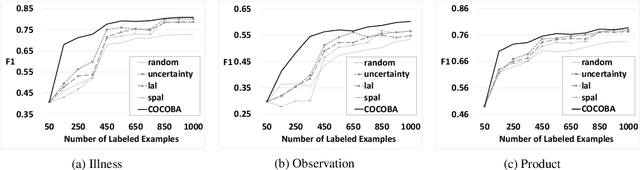

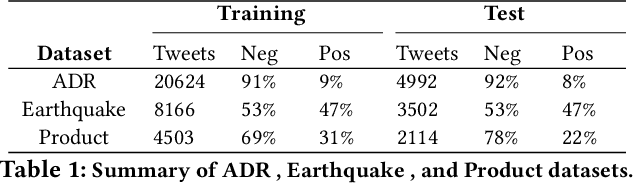
Mining user-generated content--e.g., for the early detection of outbreaks or for extracting personal observations--often suffers from the lack of enough training data, short document length, and informal language model. We propose a novel multi-view active learning model, called Context-aware Co-testing with Bagging (COCOBA), to address these issues in the classification tasks tailored for a query word--e.g., detecting illness reports given the disease name. COCOBA employs the context of user postings to construct two views. Then it uses the distribution of the representations in each view to detect the regions that are assigned to the opposite classes. This effectively leads to detecting the contexts that the two base learners disagree on. Our model also employs a query-by-committee model to address the usually noisy language of user postings. The experiments testify that our model is applicable to multiple important representative Twitter tasks and also significantly outperforms the existing baselines.
Semi-Supervised Text Classification via Self-Pretraining
Sep 30, 2021
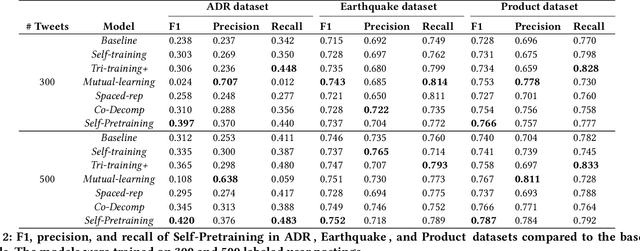
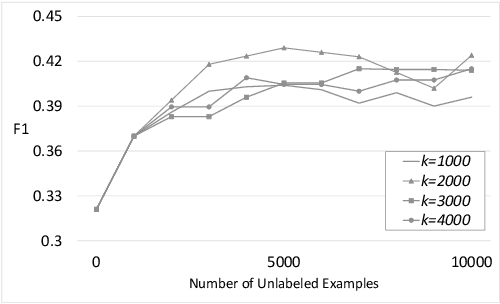
We present a neural semi-supervised learning model termed Self-Pretraining. Our model is inspired by the classic self-training algorithm. However, as opposed to self-training, Self-Pretraining is threshold-free, it can potentially update its belief about previously labeled documents, and can cope with the semantic drift problem. Self-Pretraining is iterative and consists of two classifiers. In each iteration, one classifier draws a random set of unlabeled documents and labels them. This set is used to initialize the second classifier, to be further trained by the set of labeled documents. The algorithm proceeds to the next iteration and the classifiers' roles are reversed. To improve the flow of information across the iterations and also to cope with the semantic drift problem, Self-Pretraining employs an iterative distillation process, transfers hypotheses across the iterations, utilizes a two-stage training model, uses an efficient learning rate schedule, and employs a pseudo-label transformation heuristic. We have evaluated our model in three publicly available social media datasets. Our experiments show that Self-Pretraining outperforms the existing state-of-the-art semi-supervised classifiers across multiple settings. Our code is available at https://github.com/p-karisani/self_pretraining.
Inferring COVID-19 Biological Pathways from Clinical Phenotypes via Topological Analysis
Jan 19, 2021
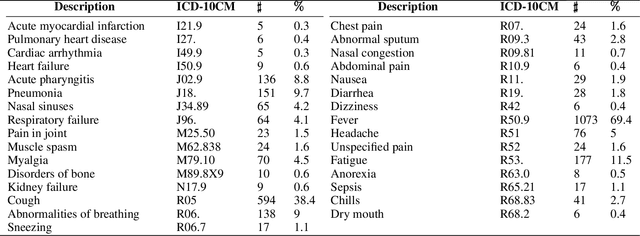
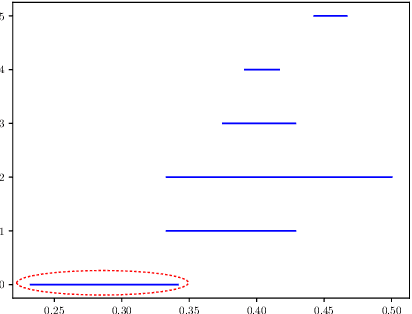
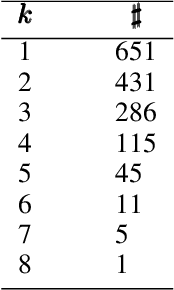
COVID-19 has caused thousands of deaths around the world and also resulted in a large international economic disruption. Identifying the pathways associated with this illness can help medical researchers to better understand the properties of the condition. This process can be carried out by analyzing the medical records. It is crucial to develop tools and models that can aid researchers with this process in a timely manner. However, medical records are often unstructured clinical notes, and this poses significant challenges to developing the automated systems. In this article, we propose a pipeline to aid practitioners in analyzing clinical notes and revealing the pathways associated with this disease. Our pipeline relies on topological properties and consists of three steps: 1) pre-processing the clinical notes to extract the salient concepts, 2) constructing a feature space of the patients to characterize the extracted concepts, and finally, 3) leveraging the topological properties to distill the available knowledge and visualize the result. Our experiments on a publicly available dataset of COVID-19 clinical notes testify that our pipeline can indeed extract meaningful pathways.
Mining Coronavirus (COVID-19) Posts in Social Media
Mar 28, 2020
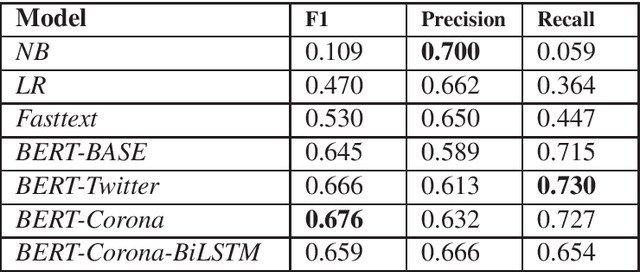
World Health Organization (WHO) characterized the novel coronavirus (COVID-19) as a global pandemic on March 11th, 2020. Before this and in late January, more specifically on January 27th, while the majority of the infection cases were still reported in China and a few cruise ships, we began crawling social media user postings using the Twitter search API. Our goal was to leverage machine learning and linguistic tools to better understand the impact of the outbreak in China. Unlike our initial expectation to monitor a local outbreak, COVID-19 rapidly spread across the globe. In this short article we report the preliminary results of our study on automatically detecting the positive reports of COVID-19 from social media user postings using state-of-the-art machine learning models.