 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Text Classification via Self-Pretraining
Paper and Code

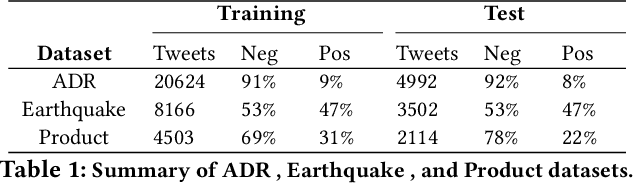
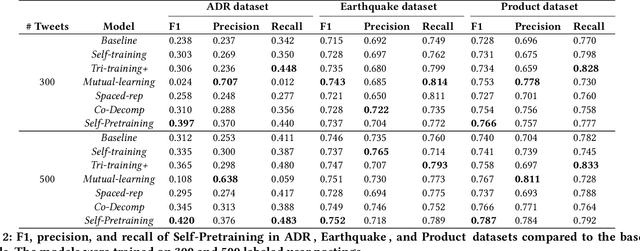
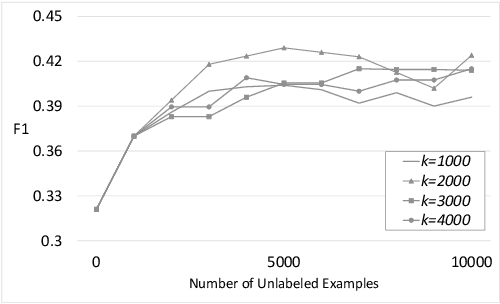
We present a neural semi-supervised learning model termed Self-Pretraining. Our model is inspired by the classic self-training algorithm. However, as opposed to self-training, Self-Pretraining is threshold-free, it can potentially update its belief about previously labeled documents, and can cope with the semantic drift problem. Self-Pretraining is iterative and consists of two classifiers. In each iteration, one classifier draws a random set of unlabeled documents and labels them. This set is used to initialize the second classifier, to be further trained by the set of labeled documents. The algorithm proceeds to the next iteration and the classifiers' roles are reversed. To improve the flow of information across the iterations and also to cope with the semantic drift problem, Self-Pretraining employs an iterative distillation process, transfers hypotheses across the iterations, utilizes a two-stage training model, uses an efficient learning rate schedule, and employs a pseudo-label transformation heuristic. We have evaluated our model in three publicly available social media datasets. Our experiments show that Self-Pretraining outperforms the existing state-of-the-art semi-supervised classifiers across multiple settings. Our code is available at https://github.com/p-karisani/self_pretraining.