 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWellFactor: Patient Profiling using Integrative Embedding of Healthcare Data
Dec 21, 2023



In the rapidly evolving healthcare industry, platforms now have access to not only traditional medical records, but also diverse data sets encompassing various patient interactions, such as those from healthcare web portals. To address this rich diversity of data, we introduce WellFactor: a method that derives patient profiles by integrating information from these sources. Central to our approach is the utilization of constrained low-rank approximation. WellFactor is optimized to handle the sparsity that is often inherent in healthcare data. Moreover, by incorporating task-specific label information, our method refines the embedding results, offering a more informed perspective on patients. One important feature of WellFactor is its ability to compute embeddings for new, previously unobserved patient data instantaneously, eliminating the need to revisit the entire data set or recomputing the embedding. Comprehensive evaluations on real-world healthcare data demonstrate WellFactor's effectiveness. It produces better results compared to other existing methods in classification performance, yields meaningful clustering of patients, and delivers consistent results in patient similarity searches and predictions.
A Knowledge Graph-Based Search Engine for Robustly Finding Doctors and Locations in the Healthcare Domain
Oct 08, 2023

Efficiently finding doctors and locations is an important search problem for patients in the healthcare domain, for which traditional information retrieval methods tend not to work optimally. In the last ten years, knowledge graphs (KGs) have emerged as a powerful way to combine the benefits of gleaning insights from semi-structured data using semantic modeling, natural language processing techniques like information extraction, and robust querying using structured query languages like SPARQL and Cypher. In this short paper, we present a KG-based search engine architecture for robustly finding doctors and locations in the healthcare domain. Early results demonstrate that our approach can lead to significantly higher coverage for complex queries without degrading quality.
Patient Clustering via Integrated Profiling of Clinical and Digital Data
Aug 22, 2023


We introduce a novel profile-based patient clustering model designed for clinical data in healthcare. By utilizing a method grounded on constrained low-rank approximation, our model takes advantage of patients' clinical data and digital interaction data, including browsing and search, to construct patient profiles. As a result of the method, nonnegative embedding vectors are generated, serving as a low-dimensional representation of the patients. Our model was assessed using real-world patient data from a healthcare web portal, with a comprehensive evaluation approach which considered clustering and recommendation capabilities. In comparison to other baselines, our approach demonstrated superior performance in terms of clustering coherence and recommendation accuracy.
DeepCAT: Deep Category Representation for Query Understanding in E-commerce Search
May 10, 2021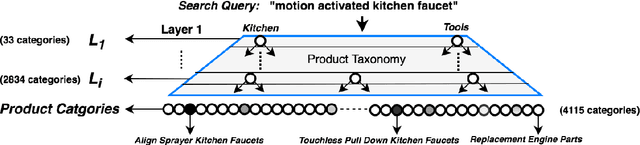
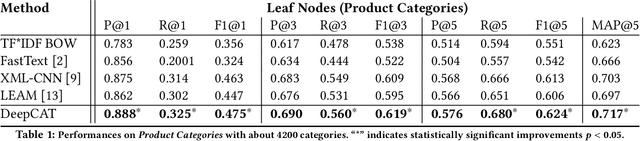
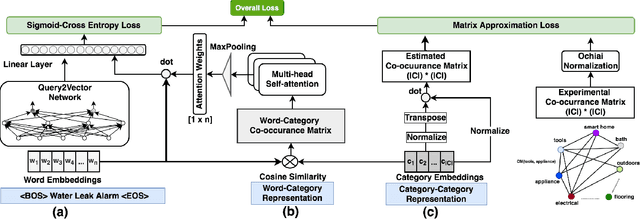
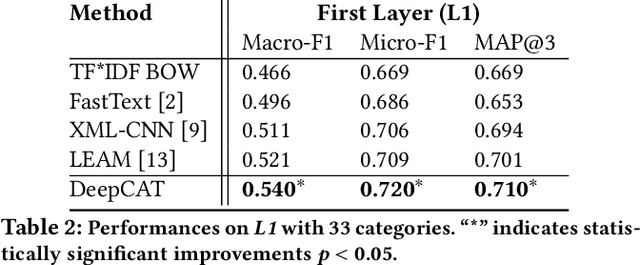
Mapping a search query to a set of relevant categories in the product taxonomy is a significant challenge in e-commerce search for two reasons: 1) Training data exhibits severe class imbalance problem due to biased click behavior, and 2) queries with little customer feedback (e.g., tail queries) are not well-represented in the training set, and cause difficulties for query understanding. To address these problems, we propose a deep learning model, DeepCAT, which learns joint word-category representations to enhance the query understanding process. We believe learning category interactions helps to improve the performance of category mapping on minority classes, tail and torso queries. DeepCAT contains a novel word-category representation model that trains the category representations based on word-category co-occurrences in the training set. The category representation is then leveraged to introduce a new loss function to estimate the category-category co-occurrences for refining joint word-category embeddings. To demonstrate our model's effectiveness on minority categories and tail queries, we conduct two sets of experiments. The results show that DeepCAT reaches a 10% improvement on minority classes and a 7.1% improvement on tail queries over a state-of-the-art label embedding model. Our findings suggest a promising direction for improving e-commerce search by semantic modeling of taxonomy hierarchies.
An End-to-End Solution for Named Entity Recognition in eCommerce Search
Dec 11, 2020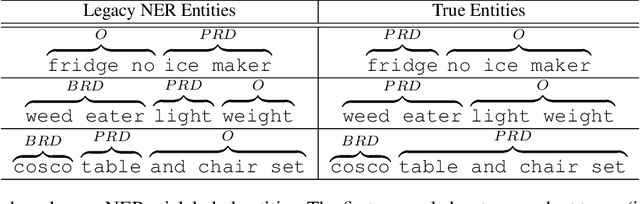



Named entity recognition (NER) is a critical step in modern search query understanding. In the domain of eCommerce, identifying the key entities, such as brand and product type, can help a search engine retrieve relevant products and therefore offer an engaging shopping experience. Recent research shows promising results on shared benchmark NER tasks using deep learning methods, but there are still unique challenges in the industry regarding domain knowledge, training data, and model production. This paper demonstrates an end-to-end solution to address these challenges. The core of our solution is a novel model training framework "TripleLearn" which iteratively learns from three separate training datasets, instead of one training set as is traditionally done. Using this approach, the best model lifts the F1 score from 69.5 to 93.3 on the holdout test data. In our offline experiments, TripleLearn improved the model performance compared to traditional training approaches which use a single set of training data. Moreover, in the online A/B test, we see significant improvements in user engagement and revenue conversion. The model has been live on homedepot.com for more than 9 months, boosting search conversions and revenue. Beyond our application, this TripleLearn framework, as well as the end-to-end process, is model-independent and problem-independent, so it can be generalized to more industrial applications, especially to the eCommerce industry which has similar data foundations and problems.
Active Learning for Product Type Ontology Enhancement in E-commerce
Sep 19, 2020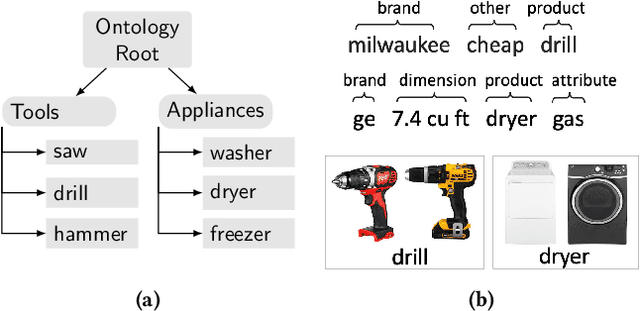
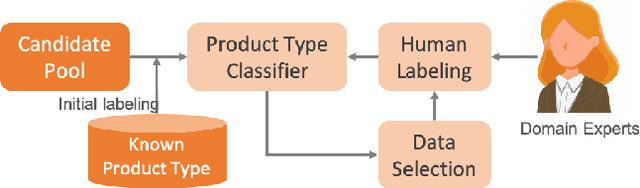
Entity-based semantic search has been widely adopted in modern search engines to improve search accuracy by understanding users' intent. In e-commerce, an accurate and complete product type (PT) ontology is essential for recognizing product entities in queries and retrieving relevant products from catalog. However, finding product types (PTs) to construct such an ontology is usually expensive due to the considerable amount of human efforts it may involve. In this work, we propose an active learning framework that efficiently utilizes domain experts' knowledge for PT discovery. We also show the quality and coverage of the resulting PTs in the experiment results.
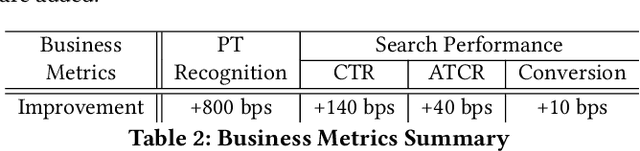
JointMap: Joint Query Intent Understanding For Modeling Intent Hierarchies in E-commerce Search
May 29, 2020
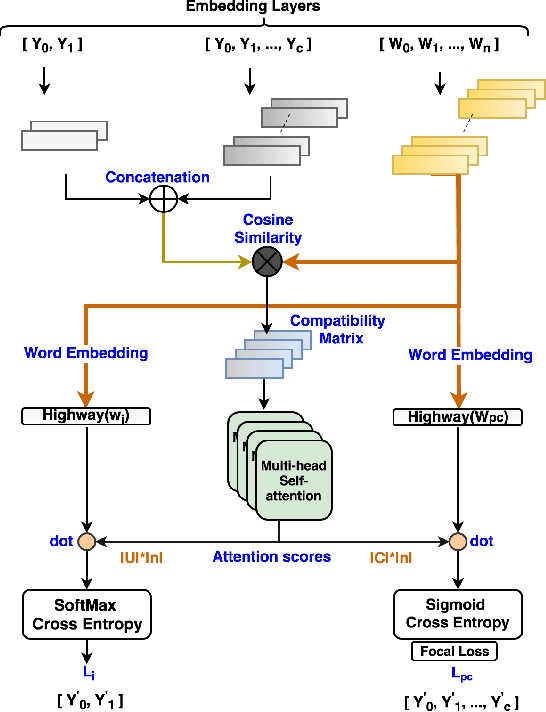
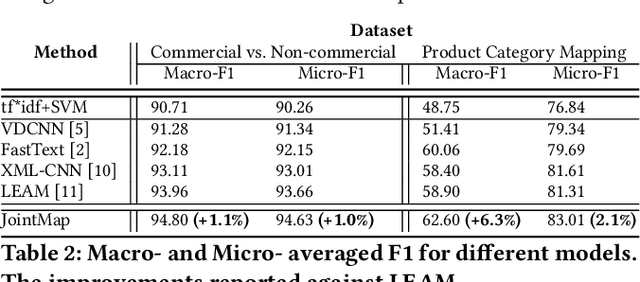
An accurate understanding of a user's query intent can help improve the performance of downstream tasks such as query scoping and ranking. In the e-commerce domain, recent work in query understanding focuses on the query to product-category mapping. But, a small yet significant percentage of queries (in our website 1.5% or 33M queries in 2019) have non-commercial intent associated with them. These intents are usually associated with non-commercial information seeking needs such as discounts, store hours, installation guides, etc. In this paper, we introduce Joint Query Intent Understanding (JointMap), a deep learning model to simultaneously learn two different high-level user intent tasks: 1) identifying a query's commercial vs. non-commercial intent, and 2) associating a set of relevant product categories in taxonomy to a product query. JointMap model works by leveraging the transfer bias that exists between these two related tasks through a joint-learning process. As curating a labeled data set for these tasks can be expensive and time-consuming, we propose a distant supervision approach in conjunction with an active learning model to generate high-quality training data sets. To demonstrate the effectiveness of JointMap, we use search queries collected from a large commercial website. Our results show that JointMap significantly improves both "commercial vs. non-commercial" intent prediction and product category mapping by 2.3% and 10% on average over state-of-the-art deep learning methods. Our findings suggest a promising direction to model the intent hierarchies in an e-commerce search engine.
An Ensemble Blocking Scheme for Entity Resolution of Large and Sparse Datasets
Sep 21, 2016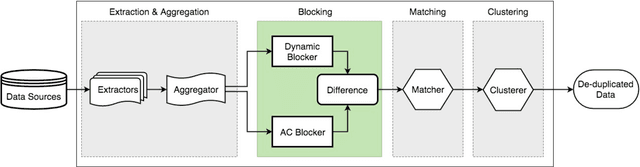
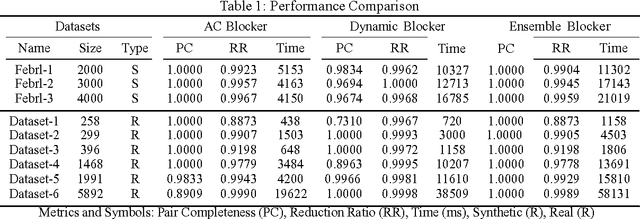
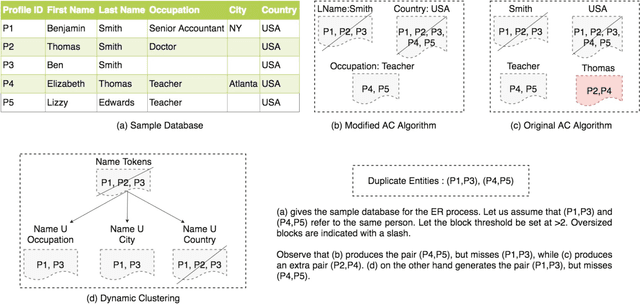
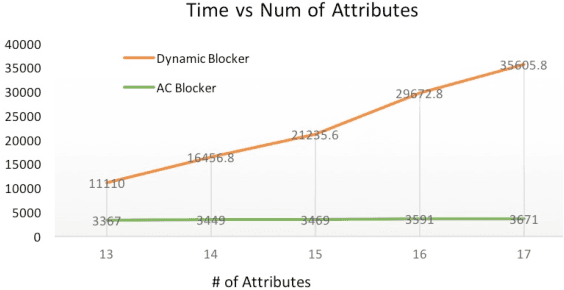
Entity Resolution, also called record linkage or deduplication, refers to the process of identifying and merging duplicate versions of the same entity into a unified representation. The standard practice is to use a Rule based or Machine Learning based model that compares entity pairs and assigns a score to represent the pairs' Match/Non-Match status. However, performing an exhaustive pair-wise comparison on all pairs of records leads to quadratic matcher complexity and hence a Blocking step is performed before the Matching to group similar entities into smaller blocks that the matcher can then examine exhaustively. Several blocking schemes have been developed to efficiently and effectively block the input dataset into manageable groups. At CareerBuilder (CB), we perform deduplication on massive datasets of people profiles collected from disparate sources with varying informational content. We observed that, employing a single blocking technique did not cover the base for all possible scenarios due to the multi-faceted nature of our data sources. In this paper, we describe our ensemble approach to blocking that combines two different blocking techniques to leverage their respective strengths.
Semantic Similarity Strategies for Job Title Classification
Sep 20, 2016
Automatic and accurate classification of items enables numerous downstream applications in many domains. These applications can range from faceted browsing of items to product recommendations and big data analytics. In the online recruitment domain, we refer to classifying job ads to pre-defined or custom occupation categories as job title classification. A large-scale job title classification system can power various downstream applications such as semantic search, job recommendations and labor market analytics. In this paper, we discuss experiments conducted to improve our in-house job title classification system. The classification component of the system is composed of a two-stage coarse and fine level classifier cascade that classifies input text such as job title and/or job ads to one of the thousands of job titles in our taxonomy. To improve classification accuracy and effectiveness, we experiment with various semantic representation strategies such as average W2V vectors and document similarity measures such as Word Movers Distance (WMD). Our initial results show an overall improvement in accuracy of Carotene[1].
Towards a Job Title Classification System
Jun 02, 2016Document classification for text, images and other applicable entities has long been a focus of research in academia and also finds application in many industrial settings. Amidst a plethora of approaches to solve such problems, machine-learning techniques have found success in a variety of scenarios. In this paper we discuss the design of a machine learning-based semi-supervised job title classification system for the online job recruitment domain currently in production at CareerBuilder.com and propose enhancements to it. The system leverages a varied collection of classification as well clustering algorithms. These algorithms are encompassed in an architecture that facilitates leveraging existing off-the-shelf machine learning tools and techniques while keeping into consideration the challenges of constructing a scalable classification system for a large taxonomy of categories. As a continuously evolving system that is still under development we first discuss the existing semi-supervised classification system which is composed of both clustering and classification components in a proximity-based classifier setup and results of which are already used across numerous products at CareerBuilder. We then elucidate our long-term goals for job title classification and propose enhancements to the existing system in the form of a two-stage coarse and fine level classifier augmentation to construct a cascade of hierarchical vertical classifiers. Preliminary results are presented using experimental evaluation on real world industrial data.