 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWellFactor: Patient Profiling using Integrative Embedding of Healthcare Data
Dec 21, 2023



In the rapidly evolving healthcare industry, platforms now have access to not only traditional medical records, but also diverse data sets encompassing various patient interactions, such as those from healthcare web portals. To address this rich diversity of data, we introduce WellFactor: a method that derives patient profiles by integrating information from these sources. Central to our approach is the utilization of constrained low-rank approximation. WellFactor is optimized to handle the sparsity that is often inherent in healthcare data. Moreover, by incorporating task-specific label information, our method refines the embedding results, offering a more informed perspective on patients. One important feature of WellFactor is its ability to compute embeddings for new, previously unobserved patient data instantaneously, eliminating the need to revisit the entire data set or recomputing the embedding. Comprehensive evaluations on real-world healthcare data demonstrate WellFactor's effectiveness. It produces better results compared to other existing methods in classification performance, yields meaningful clustering of patients, and delivers consistent results in patient similarity searches and predictions.
Patient Clustering via Integrated Profiling of Clinical and Digital Data
Aug 22, 2023


We introduce a novel profile-based patient clustering model designed for clinical data in healthcare. By utilizing a method grounded on constrained low-rank approximation, our model takes advantage of patients' clinical data and digital interaction data, including browsing and search, to construct patient profiles. As a result of the method, nonnegative embedding vectors are generated, serving as a low-dimensional representation of the patients. Our model was assessed using real-world patient data from a healthcare web portal, with a comprehensive evaluation approach which considered clustering and recommendation capabilities. In comparison to other baselines, our approach demonstrated superior performance in terms of clustering coherence and recommendation accuracy.
An Ensemble Blocking Scheme for Entity Resolution of Large and Sparse Datasets
Sep 21, 2016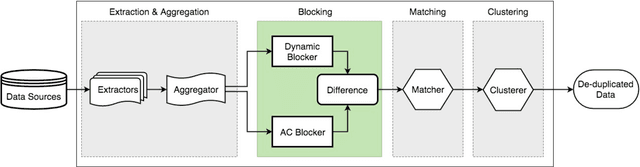
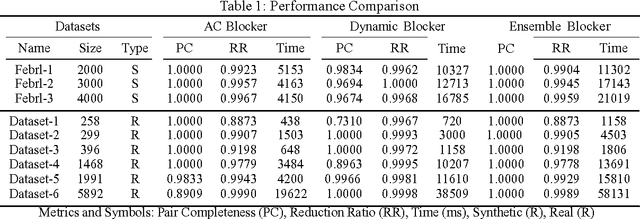
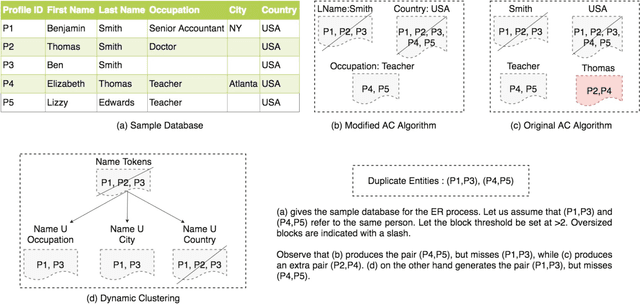
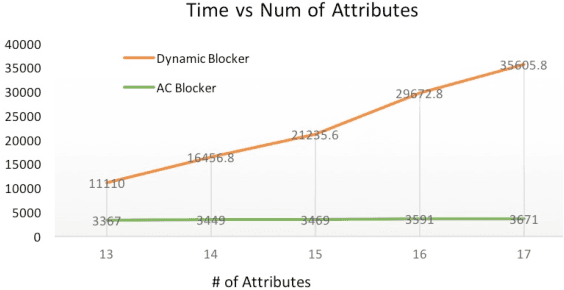
Entity Resolution, also called record linkage or deduplication, refers to the process of identifying and merging duplicate versions of the same entity into a unified representation. The standard practice is to use a Rule based or Machine Learning based model that compares entity pairs and assigns a score to represent the pairs' Match/Non-Match status. However, performing an exhaustive pair-wise comparison on all pairs of records leads to quadratic matcher complexity and hence a Blocking step is performed before the Matching to group similar entities into smaller blocks that the matcher can then examine exhaustively. Several blocking schemes have been developed to efficiently and effectively block the input dataset into manageable groups. At CareerBuilder (CB), we perform deduplication on massive datasets of people profiles collected from disparate sources with varying informational content. We observed that, employing a single blocking technique did not cover the base for all possible scenarios due to the multi-faceted nature of our data sources. In this paper, we describe our ensemble approach to blocking that combines two different blocking techniques to leverage their respective strengths.
Semantic Similarity Strategies for Job Title Classification
Sep 20, 2016
Automatic and accurate classification of items enables numerous downstream applications in many domains. These applications can range from faceted browsing of items to product recommendations and big data analytics. In the online recruitment domain, we refer to classifying job ads to pre-defined or custom occupation categories as job title classification. A large-scale job title classification system can power various downstream applications such as semantic search, job recommendations and labor market analytics. In this paper, we discuss experiments conducted to improve our in-house job title classification system. The classification component of the system is composed of a two-stage coarse and fine level classifier cascade that classifies input text such as job title and/or job ads to one of the thousands of job titles in our taxonomy. To improve classification accuracy and effectiveness, we experiment with various semantic representation strategies such as average W2V vectors and document similarity measures such as Word Movers Distance (WMD). Our initial results show an overall improvement in accuracy of Carotene[1].